In der Welt der künstlichen Intelligenz und visuellen Generierung haben Diffusionsmodelle, insbesondere Diffusions-Transformer, in den letzten Jahren bemerkenswerte Fortschritte erzielt. Diese Modelle sind in der Lage, beeindruckende und realistische Bilder und Videos zu erzeugen, die in zahlreichen Bereichen von Kunst und Design bis hin zu Filmproduktion und medizinischer Bildgebung Anwendung finden. Trotz ihres Potenzials sind Diffusions-Transformer wegen ihrer enorm hohen Rechenleistung und der damit verbundenen langen Verarbeitungszeiten häufig schwer praktikabel – gerade bei hochauflösenden Ausgaben wie 8192 × 8192 Pixel großen Bildern kann die Generierung auf modernen GPUs, zum Beispiel einer NVIDIA A100, leicht über eine Stunde dauern. Diese Herausforderungen begrenzen den Einsatz dieser Technologie in Echtzeit- oder großflächigen Anwendungsfällen. Neue Wege zur Beschleunigung dieser Systeme ohne Qualitätseinbußen sind daher dringend gefragt.
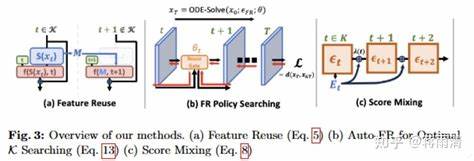
Das vor Kurzem vorgestellte Konzept GRAT (Group first, Attending smartly) steht für eine bahnbrechende Innovation, die genau diese Lücke schließt. Grat steht für ein Training-freies Beschleunigungsverfahren für Diffusions-Transformer, das keinen zusätzlichen Trainingsaufwand erfordert und dabei eine dramatische Reduktion der Rechenzeit ermöglicht. Die Grundlage von GRAT bildet die Beobachtung, dass die Aufmerksamkeit innerhalb der Transformer-Modelle oft lokal fokussiert und somit intrinsisch spärlich ist. Dank dieser Eigenschaft lässt sich die Aufmerksamkeit so umstrukturieren, dass sie effizienter berechnet werden kann, ohne die wesentlichen Zusammenhänge im Bild oder Video zu verlieren. Im Kernpartitioniert GRAT zusammenhängende Tokens in nicht überlappende Gruppen.
Diese Gruppierung ist so konzipiert, dass sie optimal mit den parallelen Ausführungsmechanismen auf modernen GPUs harmoniert und gleichzeitig die lokale Aufmerksamkeit berücksichtigt, welche die Diffusions-Transformer während des Trainings erlernt haben. Durch die Gruppierung teilen alle Query-Tokens innerhalb einer Gruppe ein gemeinsames Subset an Schlüssel- und Wert-Tokens, die für die Aufmerksamkeit genutzt werden. Restriktionen auf diese Schlüssel- und Wert-Tokens – beispielsweise auf benachbarte oder criss-cross Blockstrukturen – erlauben eine signifikante Reduktion der zu berechnenden Aufmerksamkeitselemente, was den Rechenaufwand drastisch minimiert. Ein besonders beeindruckender Aspekt von GRAT ist, dass dabei eine enorme Beschleunigung erreicht wird – laut den Autoren sind bis zu 35,8-fache Geschwindigkeitssteigerungen gegenüber der vollumfänglichen Aufmerksamkeit möglich, wenn Bilder mit 8192 × 8192 Pixeln generiert werden. Diese Performance wird ohne jegliche Fine-Tuning-Phase oder modellspezifische Trainingsanpassungen realisiert.
Somit kann GRAT direkt auf vortrainierte Modelle wie Flux oder HunyuanVideo angewandt werden, die sich jeweils auf Bild- und Videogenerierung spezialisiert haben. Die Ergebnisse zeigen, dass trotz der deutlichen Beschleunigung die Qualität der generierten Ergebnisse erhalten bleibt und sich kaum von der originalen vollumfänglichen Aufmerksamkeit unterscheidet. Damit zeigt sich, dass strukturierte Einschränkungen der Aufmerksamkeit für praktische Anwendungen mehr als ausreichend sind, um lange Abhängigkeiten und Kontextinformationen einzufangen. Die Bedeutung dieser Technik erstreckt sich weit über die unmittelbaren Geschwindigkeitsvorteile hinaus. Indem die enorme Rechenzeit auf modernen GPUs drastisch reduziert wird, eröffnet GRAT die Möglichkeit, hochauflösende Bilder und Videos in Echtzeit oder zumindest in deutlich kürzeren Zeitfenstern zu generieren.
Dies ebnet den Weg für neue Anwendungen im Bereich der interaktiven Bildbe- und videoerstellung, in digitalen Designprozessen oder in der Medienproduktion, in denen bisher lange Wartezeiten eine nennenswerte Hürde darstellten. Außerdem schafft die Methode eine demokratischere Nutzung solcher Modelle, da selbst kleinere Forschungseinrichtungen oder Entwicklerteams mit begrenzter Rechenkapazität von den Vorteilen profitieren können. Die zugrundeliegende technische Idee von GRAT basiert auf einem tiefen Verständnis der Rollen von Query-, Key- und Value-Tokens innerhalb der Attention-Mechanismen von Transformer-Modellen. Normalerweise führt die Berechnung der vollständigen Aufmerksamkeit vor jedem generierten Token zu quadratisch steigendem Rechenaufwand. Indem Tokens in Gruppen zusammengefasst werden, teilt sich der Overhead auf und die Aggregation der Aufmerksamkeit erfolgt gemeinsam für die Gruppe, was die Komplexität erheblich verringert.
Dabei sind die gewählten Gruppierungs- und Einflussbereiche so gestaltet, dass keine relevanten Informationen verloren gehen. Die lokalen Affinitäten, die in vielen vortrainierten Modellen bereits angelegt sind, werden so optimal ausgenutzt. Interessanterweise kann GRAT auch gut mit verschiedenen Arten von Diffusions-Transformern kombiniert werden, da die Methode modellar- indifferent ist und auf der Ausnutzung von Aufmerksamkeitsstrukturen basiert. Dies macht sie zu einem universellen Werkzeug in der Pipeline moderner generativer Modelle. Forschungsergebnisse zeigen, dass neben der Bildgenerierung auch Videogenerierung enorm von der beschleunigten Aufmerksamkeit profitiert.
Bei Videomodellen, bei denen Sequenzlängen und damit zusammenhängende Token weit höher sind, ist die Beschleunigung besonders wichtig, um praktikable Anwendungen zu gewährleisten. Zweifelsohne wird die weitere Verbreitung und Integration von Methoden wie GRAT die Entwicklung größerer, komplexerer und qualitativ hochwertigerer KI-Modelle vorantreiben und deren Nutzbarkeit verbessern. Die Forschung rund um die Beschleunigung von Diffusions-Transformern ist Teil eines größeren Trends, der auf Optimierung, Effizienzsteigerung und ökologischen Fußabdruck von KI-Systemen fokussiert ist. Gerade im Bereich der generativen Modelle, der erfahrungsgemäß hohe Energie- und Rechenaufwände erfordert, sind solche Innovationen technisch und umweltpolitisch von großem Wert. Abschließend lässt sich festhalten, dass die Entwicklung von trainingfreien Beschleunigungsmethoden für Diffusions-Transformer wie GRAT einen bedeutenden Schritt zur praktischen Nutzung von generativen KI-Systemen darstellt.