In einer Zeit, in der Datenmengen exponentiell wachsen und Anwendungen höchste Anforderungen an Geschwindigkeit und Effizienz stellen, rücken Technologien wie Zero-Copy (De)Serialization immer stärker in den Fokus. Diese Methode revolutioniert die Art und Weise, wie Daten zwischen Systemen übertragen und verarbeitet werden, indem sie den Verbrauch von Rechenressourcen minimiert und gleichzeitig Durchsatz und Latenz verbessert. Besonders in der Netzwerkkommunikation, verteilten Datenbanken und Streaming-Anwendungen entfaltet Zero-Copy sein volles Potenzial und definiert damit die Performance-Standards der Zukunft neu. Was versteht man unter Zero-Copy (De)Serialization? Traditionell werden Daten, die über das Netzwerk oder zwischen Prozessen transportiert werden, zuerst serialisiert – also in ein Byte-Format umgewandelt – und anschließend vom Empfänger wieder deserialisiert. Dabei entstehen oft zahlreiche Datenkopien im Speicher, die Zeit und Ressourcen binden.
Zero-Copy verfolgt einen grundlegend anderen Ansatz: Es vermeidet diese Zwischenschritte der Speicherung und Kopie vollständig. Dadurch können Daten direkt im ursprünglichen Speicherbereich weiterverarbeitet oder an den Empfänger übergeben werden. Das Ergebnis ist eine signifikante Reduzierung der CPU-Last und eine Beschleunigung von Ein- und Ausgabeoperationen. Ein bekanntes Beispiel moderner Implementierungen ist die Bibliothek rkyv, die in Programmiersprachen wie Rust eingesetzt wird. Sie ermöglicht Zero-Copy-Deserialisierung durch die Definition sogenannter Archivtraits, die eine Datenstruktur direkt in einem Speicherabbild repräsentieren.
Dieses Speicherabbild kann dann ohne aufwendige Transformation direkt genutzt werden. Ein entscheidender Vorteil dieser Technik liegt darin, dass sie es erlaubt, zum Beispiel Netzwerkpakete oder Datenströme in ihrem Format belassen zu können, ohne sie erst in interne Repräsentationen umzuwandeln. In der Praxis bedeutet dies, dass große Datenmengen wesentlich schneller verarbeitet und nahezu ohne Overhead übertragen werden können. Die zunehmende Verbreitung von Zero-Copy-Strategien hat vor allem mit den Anforderungen moderner Anwendungen zu tun. Systeme mit hoher Parallelität, Streaming-Plattformen oder Event-getriebene Architekturen profitieren davon, dass sie Daten in Echtzeit nahezu ohne Verzögerung verarbeiten können.
Dies führt nicht nur zu besseren Nutzererfahrungen, sondern auch zu geringeren Betriebskosten, da Hardware effizienter genutzt wird. Apache Iggy ist ein exzellentes Beispiel für ein Projekt, das Zero-Copy-Serialization erfolgreich einsetzt und weiterentwickelt. Die Entwickler begannen zunächst mit der Integration der rkyv-Bibliothek, setzten sich aber intensiv mit den Herausforderungen auseinander, die sich aus dieser Herangehensweise ergaben. So stellte sich heraus, dass die Verarbeitung großer Datenpakete, etwa zur Nachrichtenübermittlung innerhalb eines Logs, bestimmte Limitierungen mit sich brachte. Zum Beispiel konnte man bei rkyv nicht ohne weiteres nur Teile eines großen Datenpakets selektiv nutzen, ohne das ganze Archiv zu berücksichtigen.
Das führte zu einer innovativen Weiterentwicklung, bei der Daten in einer Kombination aus einem Längen-Präfix und einer optimierten Speicherstruktur abgelegt werden. Dadurch wurde die Flexibilität erhöht und die Performance weiter gesteigert. Ein wichtiger Aspekt bei der Umsetzung von Zero-Copy ist die Speicheralignment-Anforderung. Bibliotheken wie rkyv verlangen, dass Daten bestimmter Byte-Grenzen ausgerichtet sind, typischerweise 16 Byte. Das stellt Entwickler vor die Herausforderung, Metadaten oder zusätzliche Steuerinformationen so einzufügen, dass die Speicheralignment nicht verloren geht oder spezielle unaligned-Features genutzt werden.
Diese technische Feinheit ist essentiell, um die versprochene Performancesteigerung tatsächlich voll auszuschöpfen. Darüber hinaus zeigen Projekte wie Apache Iggy, dass Zero-Copy-Ansätze auch unabhängig von Schwergewichten wie rkyv möglich sind. Mit maßgeschneiderten Lösungen, die etwa Index-Vektoren nutzen, um Nachrichten innerhalb eines Datenstroms effizient zu lokalisieren, lässt sich Zero-Copy (De)Serialization individuell an die Anforderungen einer Anwendung anpassen. Solche Konzepte orientieren sich an der Idee, Datenzugriffe soweit wie möglich auf Ansicht-Ebenen zu halten, während eine komplette Deserialisierung erst bei tatsächlichem Bedarf erfolgt. Dieses „Lazy Deserialization“-Prinzip garantiert eine optimale Balance zwischen Flexibilität und Performance.
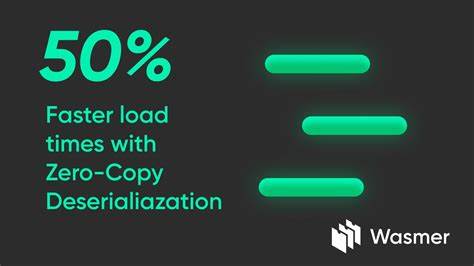
Die Leistungssteigerung durch Zero-Copy ist messbar und beeindruckend. Benchmarks von Apache Iggy verdeutlichen, dass die Durchsatzraten bei Lesetransaktionen um das Doppelte ansteigen können. Gleichzeitig sinken die Antwortzeiten, was besonders in Umgebungen mit hohen Service-Level-Agreements entscheidend ist. Auch Schreiboperationen profitieren von der Technik, wenn auch in geringerem Maße, was jedoch angesichts der Verbesserung bei der Lesegeschwindigkeit besonders wertvoll ist. Ein Hinweis zur Praxis: Zero-Copy ist nicht immer die optimale Lösung für jedes Szenario.
In eingebetteten Systemen oder bei Anwendungen mit sehr einfachen Datenformaten kann ein Overhead entstehen, der die Vorteile zunichtemacht. Außerdem ist die Integration oft mit erhöhtem Entwicklungsaufwand verbunden, da Speicherverwaltung und Sicherheitsaspekte intensiv bedacht werden müssen, um Fehler und Sicherheitslücken zu vermeiden. Dennoch wächst die Bedeutung von Zero-Copy-Deserialisierung stetig. Mit der steigenden Verfügbarkeit von High-Performance-Spezifikationen wie io_uring unter Linux lässt sich das Potential dieser Technik sogar noch weiter ausbauen. Die Kombination von Zero-Copy mit modernen IO- und Scheduler-Architekturen, etwa pro Kern eine eigene isolierte Thread-Gruppe, ermöglicht extrem effiziente Datenverarbeitungspipelines ohne Engpässe.