Die Welt der künstlichen Intelligenz und des Machine Learnings (ML) entwickelt sich rasant und bietet Unternehmen zahlreiche Möglichkeiten, ihre Prozesse effizienter zu gestalten und Wettbewerbsvorteile zu erlangen. Doch häufig scheitern Projekte nicht an der Technik oder den Algorithmen, sondern daran, dass das zugrunde liegende Geschäftsproblem nicht klar definiert wurde. Deshalb ist das korrekte Framing, die richtige Problemformulierung, im Machine Learning der zentrale Erfolgsfaktor – es entscheidet maßgeblich darüber, ob ein Modell am Ende wirklich nutzbringend ist oder nur Datenmüll produziert. Unternehmen verlangen oft vage Ziele wie „Wir wollen die Kundenbindung verbessern“ oder „Der Umsatz soll steigen“. So ambitioniert diese Ziele sind, für ein Machine Learning-Modell sind sie zu unspezifisch, um zielgerichtet bearbeitet zu werden.
Ein Datenwissenschaftler muss daher die Vision des Stakeholders in ein konkretes, messbares Problem übersetzen, das durch passende ML-Techniken lösbar ist. Dieser Prozess ist als Problemframing bekannt und bildet die Brücke zwischen Geschäftswelt und technischer Umsetzung. Machine Learning-Probleme können aus drei Hauptperspektiven betrachtet werden – den sogenannten Linsen Classification (Klassifikation), Regression und Ranking. Diese Kategorien helfen dabei, die Art des Problems zu bestimmen und den dazu passenden Algorithmus zu wählen. Klassifikation beschäftigt sich mit der Vorhersage von diskreten Kategorien oder Klassen.
Ein häufiges Beispiel ist die Kundenabwanderung, bei der vorhergesagt wird, ob ein Kunde in den nächsten Wochen abwandern wird oder nicht. Dabei liefert das Modell eine Wahrscheinlichkeitsbewertung und eine Entscheidung, wie „Ja“ oder „Nein“. Technisch kommen dabei oft Algorithmen wie Entscheidungsbäume, logistische Regression oder Support Vector Machines zum Einsatz, wobei Metriken wie Genauigkeit oder F1-Score über den Erfolg entscheiden. Regression hingegen befasst sich mit der Vorhersage kontinuierlicher Werte. Hier gilt es beispielsweise, den zukünftigen Umsatz, die Menge verkaufter Produkte oder den Kundenwert zu prognostizieren.
Ziel ist es, exakte Zahlen zu erhalten, die als Entscheidungsgrundlage dienen können. Übliche Algorithmen sind lineare Regression oder komplexere Modelle wie Random Forests oder XGBoost. Die Evaluierung erfolgt klassischerweise über Metriken wie den mittleren absoluten Fehler (MAE) oder die quadratische Wurzel des mittleren quadratischen Fehlers (RMSE). Die Ranking-Perspektive kommt dann ins Spiel, wenn ein optimales Ordnungs- oder Priorisierungsergebnis gefragt ist. Das klassische Beispiel dafür sind personalisierte Produktempfehlungen oder die Sortierung von Suchergebnissen in einem Online-Shop.
Anstatt einzelne Werte vorherzusagen, bewertet das Modell Elemente in einer Reihenfolge, die das Nutzererlebnis verbessert und beispielsweise Klick- oder Kaufwahrscheinlichkeiten maximiert. Learning-to-Rank-Algorithmen und Metriken wie nDCG oder Precision@k messen, wie gut diese Reihenfolgen den tatsächlichen Nutzerpräferenzen entsprechen. Neben diesen drei Kernlinien gibt es noch weitere wichtige Problemtypen im Machine Learning, wie zum Beispiel Clustering. Das ist ein unüberwachtes Verfahren zur Identifikation natürlicher Gruppen oder Segmente in Datensätzen, ohne vorliegende Beschriftungen. Ein praktisches Beispiel wäre die Segmentierung von Kunden in Kategorien wie „Schnäppchenjäger“ oder „treue Käufer“, was Marketingkampagnen gezielter und wirkungsvoller machen kann.
Auch das Thema Forecasting, also zeitliche Vorhersagen über eine Reihe von zukünftigen Zeitpunkten, ist wichtig. Unternehmen nutzen diese Technik, um etwa Website-Besucherzahlen oder Absatzmengen für die kommenden Wochen zu prognostizieren. Dies erfordert spezialisierte Modelle und Ansätze aus der Zeitreihenanalyse, wie ARIMA oder SARIMA. Ein ebenso wesentlicher Anwendungsfall ist Anomalieerkennung. Dabei werden ungewöhnliche oder abweichende Datenpunkte identifiziert, was für Sicherheitsanwendungen wie Betrugserkennung oder die Überwachung von IT-Systemen unerlässlich ist.
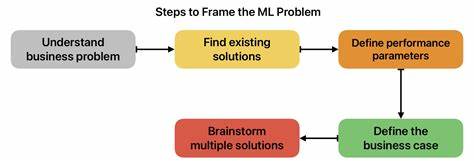
Um ein ML-Projekt erfolgreich zu starten, empfiehlt sich eine strukturierte Herangehensweise zur Problemframing. Zunächst ist zu klären, welche geschäftliche Entscheidung durch das Modell unterstützt wird. Es muss eindeutig sein, welchen konkreten Handlungsspielraum das Ergebnis bietet und welche Aktion sich daraus ableitet – ohne diesen Schritt droht die Entwicklung eines Modells, das technisch glänzt, aber keinen echten Nutzen bringt. Im nächsten Schritt definiert man, welche Art von Output für die Entscheidungsfindung benötigt wird. Ist die Antwort binär, eine genaue Zahl oder eine Rangfolge? Diese Überlegung führt zur Zuordnung der passenden ML-Perspektive.
Daraufhin bestimmt man die Einheit, für welche eine Vorhersage zu treffen ist – etwa ein einzelner Kunde, eine Produktbestellung oder ein Tag. Dieser Rahmen definiert die Struktur der Daten, auf die das Modell trainiert wird. Letztlich sind klare Erfolgskriterien sowohl technischer Natur als auch aus Geschäftssicht zu formulieren. Während Metriken wie F1-Score oder RMSE die Leistung eines Modells quantitativ bewerten, sollten sie in Beziehung zu quantifizierbaren Geschäftszielen stehen, etwa einer messbaren Reduzierung der Kundenabwanderung um fünf Prozent. So wird sichergestellt, dass das Projekt nicht nur technisch einwandfrei funktioniert, sondern auch den gewünschten Impact erzielt.
Das richtige Problemframing ist längst nicht nur eine theoretische Übung, sondern ein praktisches Muss für jedes Unternehmen, das Machine Learning wirkungsvoll einsetzen möchte. Wer diesen Schritt überspringt und direkt in die Modellierung einsteigt, läuft Gefahr, viel Zeit und Ressourcen in Lösungen zu investieren, die keine oder sogar kontraproduktive Auswirkungen haben. Dabei geht es nicht nur um Methodenkenntnis oder Programmierfertigkeiten. Die wesentliche Kompetenz eines guten Data Scientists liegt darin, die Bedürfnisse des Unternehmens zu verstehen und zu übersetzen. Algorithmen sind inzwischen weit zugänglich, zum Beispiel durch Open-Source-Bibliotheken oder Large Language Models, die Modelle automatisch generieren können.
Doch genau darin liegt auch die Gefahr: Ohne scharfen Fokus auf die Problemformulierung kann Technik zum Selbstzweck verkommen. Präzises Framing ist der Startpunkt für alle weiteren Schritte – von der Datenaufbereitung über Feature Engineering bis hin zur Modellbewertung und letztlich zum Deployment. Es sorgt dafür, dass die entwickelte Lösung von den Entscheidungsträgern akzeptiert und genutzt wird, wodurch Machine Learning tatsächlich einen messbaren Beitrag zum Geschäftserfolg leistet. Insgesamt zeigt sich, dass die Kunst des Problemframings eine der wichtigsten Fähigkeiten im Bereich Machine Learning ist. Sie ist der Schlüssel, um aus abstrakten Zielen konkrete, lösbare Fragen zu machen, die mit den richtigen Tools beantwortet werden können.
Unternehmen, die diesen Prozess ernst nehmen, heben sich signifikant von der Konkurrenz ab und setzen künstliche Intelligenz gewinnbringend ein. Die Kombination aus fachlichem Verständnis, klarem Geschäftsbezug und technischer Expertise bildet das Fundament für erfolgreiche Machine Learning Projekte, die echten Mehrwert schaffen.