Binäre Klassifikation ist eine der grundlegendsten Aufgaben im maschinellen Lernen und in der Künstlichen Intelligenz. Sie wird verwendet, um Vorhersagen in Entscheidungen zu übersetzen, die oft weitreichende Konsequenzen haben, wie etwa in der Medizin, im Finanzwesen oder in der Justiz. Trotz der Bedeutung dieser Aufgabe zeigen sich in der Praxis erhebliche Divergenzen bei der Art und Weise, wie Modelle bewertet werden. Ein zentrales Thema ist die Diskrepanz zwischen verschiedenen Bewertungskriterien, die oft ohne Berücksichtigung der tatsächlichen Konsequenzen eingesetzt werden. Aus einer konsequentialistischen Sichtweise, die die Ergebnisse von Entscheidungen und deren Auswirkungen in den Mittelpunkt stellt, ergeben sich neue Perspektiven auf die Bewertung von binären Klassifikationsmodellen.
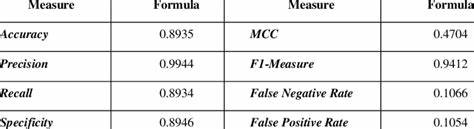
Eine kürzlich erschienene Studie beleuchtet genau diese Aspekte und stellt die vorherrschenden Praktiken an namhaften Fachkonferenzen in Frage. Die Bewertung binärer Klassifikatoren erfolgt heute vielfach anhand von Metriken wie Genauigkeit (Accuracy), Präzision, Recall, F1-Score oder AUC-ROC (Area Under the Receiver Operating Characteristic Curve). Diese Kennzahlen dienen als Maßstab, um die Leistungsfähigkeit eines Modells einzuschätzen. Allerdings wird oft übersehen, dass die Wahl der Metrik entscheidenden Einfluss darauf hat, wie praktikabel und nützlich die erzeugten Vorhersagen im jeweiligen Einsatzkontext tatsächlich sind. Beispielsweise betrachten einige Methoden feste Schwellenwerte, ab denen Vorhersagen als positiv oder negativ klassifiziert werden.
Andere wiederum verwenden sogenannte Top-K-Metriken, die sich fokussieren auf jene K Fälle mit der höchsten Wahrscheinlichkeit einer positiven Klasse. Während diese Ansätze technische Vorzüge bieten, werden aus konsequentialistischer Sicht die für unabhängige Entscheidungen erforderlichen Unsicherheiten und Wahrscheinlichkeitsverteilungen nicht umfassend genug berücksichtigt. Die Konsequenz dieser methodischen Auswahl betrifft letztlich, ob ein maschinelles Modell Entscheidungen bestmöglich unterstützt. In klinischen Anwendungen beispielsweise bedeutet es nicht nur, ob ein Test eine Krankheit korrekt identifiziert, sondern auch wie sich Fehldiagnosen oder unnötige Behandlungen auf Patientensicherheit, Kosten und ethische Überlegungen auswirken. Genau darin liegt die Stärke eines konsequentialistischen Ansatzes: Er fordert eine Integration von Entscheidungstheorie in die Modellbewertung, um so die Werte und Folgen verschiedenartiger Fehler explizit zu gewichten.
Solche Überlegungen legen den Fokus auf das Erzielen optimaler Ergebnisse durch den direkten Einbezug von Wahrscheinlichkeiten und Kosten in die Bewertung. Vor diesem Hintergrund empfiehlt die Studie, eingehender Protokolle zu verwenden, die Wahrscheinlichkeiten als Rohwerte interpretieren, anstatt einzelne Schwellen zu fixieren. Eine geeignete Metrik in diesem Zusammenhang ist der Brier-Score, der als quadratischer Fehler zwischen prognostizierter Wahrscheinlichkeit und tatsächlichem Ereigniswert definiert ist. Der Brier-Score bietet den Vorteil, dass er sowohl die Genauigkeit als auch die Kalibrierung der Wahrscheinlichkeitsvorhersagen bewertet und somit eine verlässlichere Grundlage für unabhängige Entscheidungen schafft. Interessanterweise wurde der Brier-Score lange Zeit nicht in vollem Umfang geschätzt, wobei traditionelle Metriken wie AUC-ROC oder Präzision@K dominierten.
Die Studie zeigt empirisch, dass die meisten Tutorials, Paper und Konferenzbeiträge zu binärer Klassifikation eher diese dominanten Metriken favorisieren, obwohl sie weniger gut zur Unterstützung vielfältiger, kontextabhängiger Entscheidungen geeignet sind. Darüber hinaus hebt die Untersuchung eine theoretische Einbettung des Brier-Scores in die Entscheidungskurvenanalyse (Decision Curve Analysis) hervor. Entscheidungskurven sind ein etabliertes Werkzeug in der Medizin, um die klinische Nützlichkeit eines diagnostischen Tests über unterschiedliche Schwellen hinweg zu bewerten. Die Verbindung von Brier-Score und Decision Curve Analysis macht das Werkzeugset für maschinelle Lernbewertung aussagekräftiger und praktischer einsetzbar in realen Entscheidungskontexten. Hierdurch können Debatten wie die um die klinische Anwendbarkeit von probabilistischen Vorhersagen, beispielsweise die frühere Kritik von Assel et al.
, produktiv aufgearbeitet und weiterentwickelt werden. Neben theoretischen Überlegungen stellt die Studie auch praktische Hilfsmittel bereit, etwa mit der Python-Bibliothek „briertools“. Dieses Paket macht es Forschern und Praktikern leichter, Brier-Scores in ihre Evaluationsprozesse zu integrieren und somit eine konsequentialistisch fundierte Bewertung umzusetzen. Die verstärkte Nutzung solcher Werkzeuge könnte langfristig bewirken, dass zukünftige Forschungsarbeiten und Anwendungen sich stärker an den tatsächlichen Auswirkungen von Entscheidungen orientieren statt an traditionell akzeptierten, jedoch weniger umfänglichen Metriken. Die Konsequenzen dieser neuen Perspektive sind weitreichend.
Sie berühren Fragen der Fairness, Ethik und Verantwortlichkeit in der algorithmischen Entscheidungsfindung. Wenn Bewertungskriterien tatsächlich das Ziel verfolgen, den Nutzen für Betroffene zu maximieren und Schäden zu minimieren, dann müssen die Metriken und Evaluationspraktiken diesen normativen Anspruch widerspiegeln. Gerade in gesellschaftlich sensiblen Feldern wie Justiz, Medizin oder Finanzdienstleistungen bekommen solche Bewertungsprinzipien ein besonderes Gewicht. Hier entscheidet sich, ob automatisierte Systeme vertrauenswürdig sind und unsere Werte angemessen abbilden. Schlussendlich fordert der konsequentialistische Ansatz auch eine verstärkte Sensibilisierung aller Stakeholder – von Datenwissenschaftlern über politische Entscheidungsträger bis hin zu Anwendern – für die Tragweite von Modellbewertungen.
Es reicht nicht mehr aus, auf technische Brillanz und Modellgenauigkeit zu verweisen. Vielmehr soll die Leistungsbewertung im Kontext der realen Nutzung erfolgen, bei der nicht jede Fehlentscheidung gleich gewichtet werden kann und Wahrscheinlichkeiten interaktiv mit individuellen Präferenzen und Kostenfaktoren verschmelzen. Nur so entstehen Modelle, die nicht nur statistisch gut abschneiden, sondern tatsächlich positive gesellschaftliche Effekte erzielen. Zusammenfassend lässt sich sagen, dass die aktuelle Dominanz von Metriken wie Top-K Bewertungen und fixen Schwellenwerten eine Lücke aufweist, wenn es um die Unterstützung folgenreicher, unabhängiger Entscheidungen geht. Die Integration von konsequentialistischen Prinzipien, insbesondere durch die Verwendung von Metriken wie dem Brier-Score, verspricht eine fundiertere und praktischere Modellbewertung.
Durch theoretische Verknüpfungen, empirische Evidenz und praktische Tools entstehen so neue Standards, die sich stärker an realen Bedürfnissen orientieren und die verantwortungsvolle Anwendung maschinellen Lernens fördern. Dieses Umdenken kann einen wichtigen Beitrag zur Weiterentwicklung im Bereich der binären Klassifikation leisten und dabei helfen, maschinelle Lernsysteme verantwortungsbewusst und effizient einzusetzen.