Graph Learning etablierte sich in den letzten Jahren als wegweisende Methode für Anwendungen, die mit vernetzten Strukturen arbeiten. Vom Empfehlungswesen über Betrugserkennung bis hin zur Analyse sozialer Netzwerke profitieren moderne KI-Systeme von dieser Fähigkeit, komplexe Beziehungen zwischen Datenpunkten zu verstehen und auszuwerten. Dabei steht die Effizienz der Modelle im Vordergrund, da große Datensätze und aufwändige Graphstrukturen enorme Rechenressourcen verlangen. Die Kombination von PyTorch Geometric (PyG), einer spezialisierten Bibliothek für Graph Neural Networks, und der neuen Kompilationstechnologie torch.compile aus PyTorch 2.
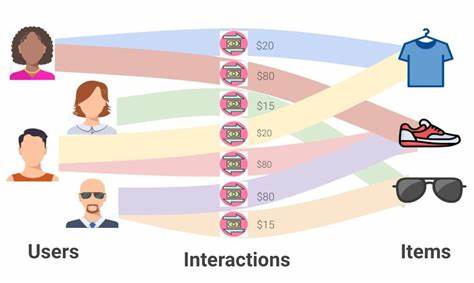
0 erweist sich als Schlüssel zur erheblichen Beschleunigung von Graph Learning Modellen, ohne dabei an Genauigkeit einzubüßen. Einblicke aus der Forschung bei Kumo AI zeigen, wie moderne Verfahren Relationale Deep Learning Modelle performant und skalierbar machen, speziell im Umgang mit heterogenen und multimodalen Daten. Relational Deep Learning (RDL) bildet die fortschrittliche Grundlage vieler graphbasierter KI-Modelle. Diese Methode integriert tiefes Lernen mit relationalem Denken, um strukturierte und vernetzte Informationen wirkungsvoll zu verarbeiten. Dabei werden große heterogene Graphen erstellt, bei denen unterschiedliche Knotentypen wie Benutzer, Interaktionen und Artikel verschiedene Datentabellen repräsentieren.
Die Beziehungen entstehen durch verknüpfte Primär- und Fremdschlüssel, die natürliche Kanten im Graph darstellen. Graph Transformer und Graph Neural Networks erlauben es, sowohl die topologischen Strukturen als auch die vielfältigen Merkmalsdaten wie numerische Werte, Kategoriedaten oder zeitliche Angaben einzubeziehen. Dies führt zu präzisen und skalierbaren Modellen, die beispielsweise den Churn von Kunden vorhersagen, Empfehlungen aussprechen oder Transaktionsbetrug aufdecken. Die Implementierung erfolgt dabei auf dem Open-Source-Stack von PyTorch, mit PyG als zentralem Framework für Message Passing und Graphoperationen. Ergänzend kommt PyTorch Frame zum Einsatz, das die effiziente Verarbeitung multimodaler Features unterstützt und sie in einem gemeinsamen Embedding-Raum zusammenführt.
PyTorch Lightning sorgt für eine saubere Struktur und Skalierbarkeit im Trainingsprozess. Trotz der großen Flexibilität der PyTorch-eigenen Eager-Ausführung stellt sich in produktiven Umgebungen die Frage nach Geschwindigkeit und Speicheroptimierung. Dort setzt PyTorch 2.0 mit torch.compile an, einer Funktion, die PyTorch-Modelle mittels eines Just-In-Time-Kompilierers in hoch optimierten Kernelcode übersetzt.
Die Nutzung ist dabei besonders einfach gestaltet: Ein Modell wird lediglich mit torch.compile ummantelt, ohne dass tiefe Änderungen im Sourcecode nötig sind. Allerdings zeigen erste Tests und Analysen, dass torch.compile nicht automatisch in allen Situationen optimale Performance garantiert. Beispielsweise traten bei den relationalen Deep Learning Modellen von Kumo AI gelegentliche Verzögerungen am Ende von Trainings-Epochen auf, und im Trainingsschritt führte die synchronisierte Wartezeit der CPU auf die GPU-Inferenz zu unnötigen Wartezeiten.
Solche Herausforderungen machen deutlich, dass umsichtige Optimierungen und das Vermeiden spezifischer Fallen notwendig sind, um die vollständigen Vorteile von torch.compile auszuschöpfen. Ein zentraler Punkt für die Effizienz ist der Umgang mit der dynamischen Form der Daten. In Graph Learning ändern sich die Eingabegrößen in jeder Iteration, da etwa die Anzahl der Nachbarknoten variiert und verschiedene Minibatches unterschiedlich große Subgraphen enthalten. Standardmäßig nimmt torch.
compile an, dass sich die Eingabeform nicht verändert. Wenn die Form doch variiert, wird das Modell bei jeder neuen Form des Eingabedatenstroms erneut kompiliert – ein zeitaufwändiger Prozess, der die Trainingsgeschwindigkeit beeinträchtigen würde. Hier ermöglicht die Option dynamic=True eine kompakte Vorabkompilierung, die verschiedene Datenformen akzeptiert. Das Resultat ist eine dramatische Reduzierung unnötiger Re-Kompilationen und eine bessere Ausnutzung der Hardware. Eine weitere Ursache für unerwünschte Re-Kompilationen liegt im Umgang mit Optimierern und Lernraten-Schedulern.
torch.compile interpretierte den üblicherweise als Fließkommazahl gespeicherten Lernrate-Parameter als unveränderlich, obwohl Schedulers diesen Wert im Laufe des Trainings schrittweise anpassten. Sobald die Lernrate verändert wurde, wurde die Annahme von torch.compile verletzt – erneute Optimierungen waren die Folge. Der Trick ist, den Lernrate-Parameter als Tensor zu definieren, der zur Laufzeit geändert werden kann.
Auf diese Weise bleibt der Kompilierungszustand stabil, und die Trainingsgeschwindigkeit bleibt hoch. Ein weiterer wichtiger Aspekt betrifft sogenannte Graph Breaks. Das sind Stellen im Programmablauf, an denen torch.compile den Code nicht zu einem nahtlosen Graphen zusammenfassen kann. An solchen Stellen kann die Ausführung nicht optimal gebündelt werden, was zu zusätzlicher Datenbewegung zwischen CPU und GPU und damit zu Performance-Einbußen führt.
Durch genaue Log-Analysen mit TORCH_LOGS=graph_breaks identifizieren Entwickler diese Problemstellen und beheben sie mit vergleichsweise einfachen Codeänderungen. Ein Beispiel ist die Verwendung von String-Schlüsseln anstelle von Tupeln als Schlüssel in PyG-ModuleDicts – eine Vorgehensweise, die Kompilierungsgraphen konsistenter macht und so Brüche minimiert. Auch wenn CUDA Graphs eine interessante Option für Performance-Steigerungen darstellen, sollte ihre Anwendung gut bedacht werden. CUDA Graphs zeichnen GPU-Operationen auf und erlauben deren Wiederholung mit einem einzigen Startaufruf durch die CPU. Die Technologie liefert vor allem bei statischen und wenig variierenden dynamischen Formen Vorteile.
In Szenarien mit stark wechselnden Graphgrößen wie in relationalen Graphmodellen können die hohen Speicheranforderungen und der Aufwand für die Aufzeichnung erhebliche Nachteile mit sich bringen. Kumo AI entschied sich daher bisher gegen den Einsatz von CUDA Graphs, um keinen Performanceverlust zu riskieren. Die Minimierung von Synchronisationen zwischen CPU und GPU erweist sich als weiterer wesentlicher Hebel. Standardmäßig läuft Python-Code asynchron zur GPU-Ausführung. Doch bestimmte Operationen, etwa die Umwandlung von GPU-Tensoren zu Skalarwerten auf der CPU, erzwingen eine Blockade, bis die GPU ihre Arbeit beendet hat.
Solche Synchronisationspunkte führen zu Leerlaufzeiten auf dem Gerät, die sich durch Anpassung des Codes vermeiden lassen. Beispielsweise kann die Berechnung von Metriken dauerhaft auf der GPU erfolgen, sodass eine Übertragung erst am Ende erfolgt. Außerdem wurde beobachtet, dass manche PyTorch-Funktionen wie torch.repeat_interleave durch das fehlende Vorwissen über Ausgabedimensionen implizite Synchronisationen auslösen. Hier hilft das explizite Übergeben von Attributen wie output_size, um die GPU-Auslastung optimaler zu gestalten.
Neben diesen spezifischen Maßnahmen empfiehlt sich das Befolgen allgemeiner Best Practices zur Performance-Optimierung in PyTorch Programmen. Dazu zählen Techniken wie das Verbergen von Kommunikations- oder Datenübertragungszeiten hinter GPU-Berechnungen sowie die kontinuierliche Integration von Updates aus dem PyG- und PyTorch-Ökosystem, die nicht nur die Kompatibilität mit torch.compile verbessern, sondern auch kontinuierliche Performancegewinne ermöglichen. Die Experimente bei Kumo AI belegen eindrücklich, wie sich der Aufwand lohnt. Beim Training von Graph Learning Modellen auf realen Datensätzen, etwa dem Empfehlungssystem-Datensatz der Kaggle H&M Challenge, führten die gezielten Optimierungen zu einer Beschleunigung von bis zu 35 Prozent gegenüber der klassischen Eager-Ausführung.
Gleichzeitig ließen sich präzise Vorhersagen erhalten, die keine Genauigkeitseinbußen erlitten. Zusammengefasst zeigt die Kombination von PyTorch Geometric mit torch.compile das immense Potenzial, graphbasierte Modelle effizient in produktiven Systemen einzusetzen. Die wichtigsten Erfolgsfaktoren liegen in der sorgfältigen Optimierung für dynamische Eingabedaten, dem Vermeiden unnötiger Re-Kompilationen, dem gezielten Entfernen von Graph Breaks und Synchronisationsfallen sowie dem konsequenten Updaten der eingesetzten Bibliotheken. Für Entwickler im Bereich Graph Learning eröffnen sich damit neue Möglichkeiten, komplexe Szenarien schneller und ressourcenschonender zu realisieren.
Die Erkenntnisse aus der Forschung bei Kumo AI schaffen eine wertvolle Grundlage für die PyTorch Community, die mit torch.compile noch leistungsfähigere und flexiblere Graph Learning Lösungen entwickeln möchte.