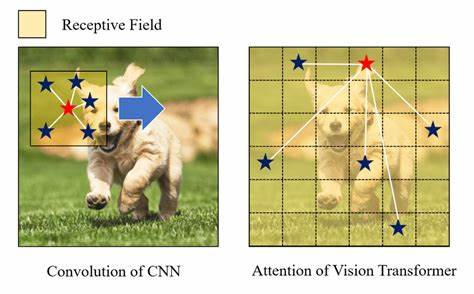
Die Computer-Vision-Landschaft hat sich in den letzten Jahren rasant entwickelt und wird heutzutage vor allem von zwei dominierenden Architekturtypen geprägt: den Convolutional Neural Networks (CNNs) und den Vision Transformers (ViTs). Während CNNs schon seit jeher als Standardarchitektur für Bilderkennung, Objektdetektion und viele weitere visuelle Aufgaben gelten, sind Vision Transformers eine relativ neue, aber stark aufstrebende Alternative, die auf dem Transformer-Mechanismus basiert und ursprünglich aus der Sprachverarbeitung stammt. In der Fachwelt wird häufig diskutiert, wie sich beide Modelle hinsichtlich Geschwindigkeit, Effizienz und Skalierbarkeit verhalten, insbesondere bei zunehmender Bildauflösung. Dieser Beitrag widmet sich einer ausführlichen Betrachtung dieser Aspekte und räumt mit verbreiteten Missverständnissen auf. CNNs basieren auf einem gestackten System von Faltungen, durch das ein Feature-Extractor über das Bild „slidet“.
Dabei entsteht ein zunehmend abstrahierter und meist auf geringerer Auflösung befindlicher Merkmalsraum, der als Grundlage für die jeweilige Aufgabe dient. Diese Methode zeichnet sich durch eine starke Lokalisierung der Bildinformationen aus und hat sich in vielen praktischen Anwendungen bewährt. Im Gegensatz dazu zerlegen Vision Transformers das Bild von Beginn an in kleine Patches, welche anschließend durch selbst-attentive Mechanismen miteinander interagieren. Die Quadratische Komplexität der Selbstaufmerksamkeit bei steigender Patch-Anzahl ist oft als Nachteil dieser Architektur hervorgehoben worden. Allerdings zeigen moderne Benchmarking-Studien, dass ViTs durchaus mit Bildauflösungen von bis zu 1024x1024 Pixeln effizient umgehen können – eine Größe, die für die meisten realweltlichen Anwendungen ausreichend ist.
Aktuelle Untersuchungen bestätigen, dass Vision Transformers in vielen Fällen nicht nur konkurrenzfähige Geschwindigkeiten erreichen, sondern häufig sogar schneller sind als vergleichbare CNN-Modelle, insbesondere auf moderner Hardware wie aktuellen GPUs. Dabei ist der Zusammenhang zwischen FLOPs (Floating Point Operations per Second) und tatsächlicher Geschwindigkeit nicht linear. Dies bedeutet, niedrige FLOP-Werte garantieren nicht automatisch schnellere Ausführung. Ein differenzierter Blick auf die Hardwareausnutzung und Implementierungsdetails ist maßgeblich, um die Performance realistisch einzuschätzen. Interessanterweise sind ViTs oftmals speichereffizienter als CNNs und erlauben höhere Auflösungen bei begrenztem GPU-Speicher, was auf handfestes technologisches Potenzial auch für ressourcenbegrenzte Szenarien hinweist.
Eine weitere bemerkenswerte Innovation im Kontext der ViTs ist der Einsatz von sogenannter lokaler Aufmerksamkeit. Hierbei wird der Bildraum in nicht überlappende Fenster aufgeteilt, und die Selbstaufmerksamkeit findet nur innerhalb dieser Fenster statt. Diese Methode minimiert den Rechenaufwand und reduziert den Speicherbedarf erheblich, ohne die Modellqualität signifikant einzuschränken. Lokale Aufmerksamkeit macht es möglich, vortrainierte ViT-Modelle mit niedriger Auflösung auf höhere Auflösungen zu „upcyclen“, indem das ursprüngliche Patch-Format als Fenstergröße beibehalten wird. Diese Technik hat in jüngsten Arbeiten wie ViTDet und Segment Anything Model (SAM) große Beachtung gefunden und zeigte, wie elegant man mit Transformer-Architekturen komplexe Skalierungsprobleme lösen kann.
Im Gegensatz dazu gibt es bislang keine ebenso einfache und effektive Lösung für CNNs, die vergleichbare Vorteile bei hochauflösender Bildverarbeitung bieten würde. Die häufige Fokussierung auf immer höhere Bildauflösungen wird in der Debatte oft überschätzt. Das menschliche Bedürfnis nach perfekter Bildschärfe und Detailgenauigkeit – wie etwa bei medizinischen Bildgebungsverfahren oder Satellitenbildern – spiegelt sich nicht eins zu eins in den Anforderungen an Computer-Vision-Modelle wider. Für natürliche Fotografien etwa sind Auflösungen um die 224x224 Pixel ausreichend, um hervorragende Ergebnisse zu erzielen. Für Anwendungsfälle wie das Erkennen von Text auf Fotos, Diagrammen oder Smartphone-Bildschirmen reichen 448x448 Pixel aus.
Selbst für komplexere Aufgaben wie das Verarbeiten von Desktop-Screenshots oder einseitigen Dokumenten sind Auflösungen von 896x896 Pixeln meistens hinreichend. Höhere Auflösungen erhöhen zwar die Modellkapazität und ermöglichen dadurch eine potenzielle Leistungssteigerung, allerdings wächst mit der Pixelzahl auch die erforderliche Rechenleistung erheblich – zudem steigt der Speicherverbrauch. Es ist wichtig zu verstehen, dass Leistung und Effizienz in der Computer Vision nicht allein von der reinen Auflösung abhängen. Eine Erhöhung der Auflösung erhöht ebenfalls die Modellkapazität, also die Fähigkeit des Modells, komplexere Features zu repräsentieren. Experimente zum Beispiel im Rahmen des PaliGemma-Berichts zeigen, dass ein deutlicher Teil von Leistungsverbesserungen bei größeren Bildgrößen tatsächlich auf den gestiegenen Rechenaufwand und damit auf die erhöhte Kapazität zurückzuführen ist.
Das bedeutet, oft sind auch Modellarchitektur und Rechenbudget entscheidend für den Erfolg einer Anwendung. Im Bereich Training sind die Erkenntnisse ähnlich. Obwohl Trainingsprozesse generell aufwändiger sind als reine Inferenz, zeigen Messungen, dass ViTs auch während des Trainings effizienter mit Arbeitsspeicher umgehen als CNNs. Dies kann entscheidend sein, wenn große Datensätze verwendet oder Modelle mit hohem Parameterumfang trainiert werden. Zudem eröffnen ViTs durch ihre Patch-basierte Struktur ganz neue Möglichkeiten bei Methoden wie Masked AutoEncoders oder selbstüberwachtem Lernen, die mit konventionellen CNNs schwierig oder unrealistisch umzusetzen sind.
Verschiedene Studien weisen darauf hin, dass ViTs sich auch bei Contrastive Learning oder bei Multimodal-Anwendungen wie CLIP oft besser schlagen als ihre CNN-Pendants, ohne dass die genauen Gründe dafür bis heute vollständig geklärt sind. Die Flexibilität der ViT-Architektur lässt auch bei der Integration von Verbesserungen viel Spielraum. Token-Dropping oder lokale Aufmerksamkeit sind elegante Mechanismen, die sich schnell in bestehende Modelle implementieren lassen und deutliche Effizienzsteigerungen ermöglichen. Solche Innovationen profitieren von der relativen Einfachheit des Transformer-Designs und formieren damit einen Wettbewerbsvorteil gegenüber fest etablierten CNN-Strukturen, die durch ihr komplexes Geflecht an Faltungsschichten und Pooling oft schwer skalierbar sind. Letztlich hängt die Wahl der passenden Architektur stark von den individuellen Anforderungen der Anwendung ab.
Faktoren wie Vertrautheit mit Frameworks, Zugang zu vortrainierten Gewichten oder die spezifischen Hardware-Ressourcen spielen eine große Rolle. Während CNNs nach wie vor weit verbreitet und gut untersucht sind, bieten ViTs eine spannende Alternative, die besonders auf modernen GPUs und bei höherem Auflösungsbedarf oft Vorteile bringt. Die teilweise verbreitete Skepsis gegenüber der Skalierbarkeit von ViTs ist heute nicht mehr haltbar, wenn man aktuelle Daten und Benchmarks zugrunde legt. Abschließend steht fest, dass sowohl Vision Transformers als auch Convolutional Neural Networks ihre spezifischen Stärken haben. Die Entwicklung der Hardware und neuer Algorithmen macht Vision Transformers zunehmend attraktiver für verschiedenste Einsatzszenarien.
Wer sich frühzeitig mit den Feinheiten dieser Technologie auseinandersetzt, kann Wettbewerbsvorteile gewinnen und innovative Lösungen umsetzen. Die Zukunft der Computer Vision wird vermutlich von einer Mischung beider Architekturen geprägt sein, wobei die Flexibilität und Effizienz von ViTs besonders in hochauflösenden und ressourcenintensiven Anwendungen eine immer wichtigere Rolle spielen werden.