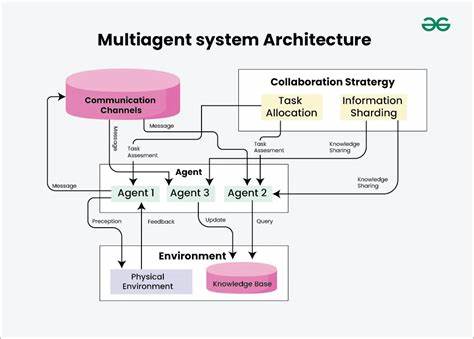
Die Entwicklung von Multi-Agenten-Systemen stellt einen bedeutenden Schritt in der Weiterentwicklung künstlicher Intelligenz dar. Statt sich auf einen einzelnen KI-Agenten zu verlassen, arbeitet eine Vielzahl spezialisierter Agenten gemeinsam, um komplexe und offene Fragestellungen zu bearbeiten. Anthropic hat mit der Integration mehrerer Claude-Agenten ein Forschungssystem geschaffen, das speziell dafür ausgelegt ist, komplexe Themen effektiver und flexibler zu erforschen. Die Entstehung dieses Systems, von der ersten Prototyp-Stufe bis hin zum produktiven Einsatz, bietet wertvolle Erkenntnisse für Entwickler und Unternehmen, die ähnliche Systeme realisieren möchten. Das Herzstück des Systems ist die Fähigkeit mehrerer Claude-Agenten, koordiniert zusammenzuarbeiten.
Ein Lead-Agent analysiert Nutzeranfragen, entwirft eine Forschungsstrategie und setzt spezialisierte Subagenten ein, die parallel unterschiedliche Aspekte der Fragestellung untersuchen. So können sie simultan Informationen aus verschiedensten Quellen zusammentragen, auswerten und an den zentralen Agenten zurückmelden, der die Ergebnisse konsolidiert und die Forschungslinie bei Bedarf anpasst. Dieses Modell entspricht dem realen Forschungsprozess, bei dem Forscher ihre Herangehensweise anhand der gewonnenen Erkenntnisse laufend neu justieren. Ein wesentlicher Vorteil des Multi-Agenten-Systems liegt in seiner Flexibilität gegenüber der Unvorhersehbarkeit von Forschungsvorhaben. In der Forschung lassen sich Abläufe und notwendige Schritte nicht starr vordefinieren, vor allem nicht bei komplexen, dynamischen Themen.
Der Einsatz individueller Agenten, die autonom, aber koordiniert agieren, ermöglicht eine parallele, unabhängige Exploration verschiedenster Facetten. Dadurch vermindert sich die sogenannte Pfadabhängigkeit, also die Gefahr, bei einem linearen Vorgehen in Sackgassen zu gelangen, erheblich. Besonders beeindruckend ist die Skalierbarkeit dieses Ansatzes. Während ein einzelner Agent bei umfangreichen Themen durch Kontext- und Tokenbegrenzungen limitiert ist, ermöglicht die Aufteilung der Arbeit auf mehrere Subagenten eine Erweiterung des verfügbaren Kontextfensters und eine größere Token-Ausnutzung. Bei Anthropic wurde festgestellt, dass das Multi-Agenten-System mit Claude Opus 4 als Lead-Agent und Claude Sonnet 4 als Subagenten die Leistung eines einzelnen Claude Opus 4 um über 90 % übertrifft.
Die breite Abdeckung durch parallele Suchvorgänge versetzt das System in die Lage, auch sehr umfangreiche Fragen schneller und präziser zu beantworten. Die Architektur basiert auf einem Orchestrator-Worker-Muster, bei dem der Lead-Agent als Koordinator fungiert und die Subagenten gezielt mit klar abgegrenzten Aufgaben betraut. Diese Subagenten agieren weitgehend autonom, verwalten ihre eigenen Suchanfragen, werten Ergebnisse aus und kommunizieren ihr „Forschungsergebnis“ an den Lead-Agenten zurück. Diese Arbeitsaufteilung optimiert das Gesamtsystem, da verschiedene Tools und Informationsquellen gleichzeitig genutzt werden können, was die Effizienz und Geschwindigkeit dramatisch erhöht. Im Gegensatz zu klassischen Retrieval-Methoden, die statisch relevante Dokumentenabschnitte abrufen und daraus Antworten generieren, verfolgt Anthropic einen dynamischen, mehrstufigen Suchansatz.
Dieser erlaubt es dem System, bei neuen Erkenntnissen flexibel die Strategie anzupassen, neue Suchwege einzuschlagen und die gefundenen Daten ständig zu überprüfen und zu interpretieren. Die so entstehenden Ergebnisse werden abschließend einem speziellen Zitationsagenten übergeben, der die Quellen sauber referenziert und die Nachvollziehbarkeit sicherstellt. Prompt-Engineering spielt im Multi-Agenten-System eine Schlüsselrolle. Die Qualität und Effektivität der Agenten wird maßgeblich von den Anweisungen bestimmt, die sie erhalten. Zunächst mussten viele typische Fehler ausgemerzt werden, wie etwa das unnötige Erzeugen zahlreicher Subagenten für einfache Aufgaben oder das ineffiziente Wiederholen identischer Suchvorgänge.
Um solche Probleme zu vermeiden, entwickelte das Team detaillierte Prompt-Strategien, die den Agenten erlauben, ihren eigenen Arbeitsaufwand an die Komplexität der jeweiligen Aufgabe anzupassen. Der Lead-Agent erhält präzise Vorgaben, wie er die Gesamtabfrage in sinnvolle Teilaufgaben unterteilt und jeder Subagent erhält klare Zielsetzungen, Ausgabefomate und Werkzeughinweise. Damit wird sichergestellt, dass Doppelarbeit vermieden wird und jeder Subagent seine Ressourcen auf einen klar abgegrenzten Forschungsbereich konzentriert. Außerdem fördert die Anleitung, breit zu starten und dann sukzessive die Suche zu präzisieren, eine zielführende Vorgehensweise, die der menschlichen Forschung nachempfunden ist. Die Werkzeuge, die den Agenten zur Verfügung stehen, werden gezielt ausgesucht und beschrieben.
Ein falsches Tool oder eine unzureichende Werkzeugbeschreibung kann sonst dazu führen, dass Agenten falsche Pfade verfolgen oder wertvolle Zeit verschwenden. Deshalb wurde der Fokus auf eine klare Zweckbestimmung jedes Tools gelegt und den Agenten beigebracht, zunächst alle verfügbaren Ressourcen einzuschätzen, bevor sie sich auf die sinnvollsten Instrumente konzentrieren. Interessanterweise ermöglicht die Kombination aus Claude 4 Modellen und selbstreflektierendem Prompt-Engineering sogar eine Selbstverbesserung der Agenten. Ein spezieller Testagent prüft Tools auf Fehler und kann deren Beschreibungen bei Bedarf selbstständig neu formulieren, was zu einer messbaren Effizienzsteigerung führt. Eine solche Feedback-Schleife erhöht die Robustheit und Anpassungsfähigkeit des Systems erheblich.
Auch die parallele Nutzung von Tools steigert nicht nur die Geschwindigkeit, sondern auch die Leistungsfähigkeit bei komplexen Recherchen. Frühe Versionen des Systems arbeiteten noch sequenziell und waren entsprechend langsam. Durch die gleichzeitige Aktivierung mehrerer Subagenten und den parallelen Einsatz mehrerer Werkzeuge können Rechercheaufträge heute in einem Bruchteil der ursprünglichen Zeit abgearbeitet werden. Die Bewertung und Qualitätssicherung der Agenten war aufgrund der Komplexität des Systems eine besondere Herausforderung. Klassische Evaluationsmethoden stoßen an Grenzen, weil Multi-Agenten-Architekturen nicht zwangsläufig den identischen Lösungsweg folgen, um zum Ziel zu gelangen.
Stattdessen muss die Bewertung berücksichtigen, ob das gewünschte Ergebnis am Ende erreicht wurde, und ob der Prozess insgesamt logisch und effizient verlief. Anthropic startete früh mit kleinen Testsätzen, um schnelle Verbesserungen unmittelbar sichtbar zu machen. Gleichzeitig wurde der Einsatz von großen Sprachmodellen als unabhängige Richter implementiert, die Forschungsoutputs anhand von Kriterien wie Fakten- und Zitationsgenauigkeit, Vollständigkeit und Werkzeugnutzung bewerten. Diese automatisierte Beurteilung erlaubt eine skalierbare Qualitätssicherung über hunderte Anfragen. Gleichzeitig bewies sich menschliches Testing als unverzichtbar, um subtile Fehler und Biases zu identifizieren, die maschinelle Evaluierungen übersehen.
So zeigte sich beispielsweise eine anfängliche Neigung der Agenten, bevorzugt sehr gut platzierte SEO-Webseiten gegenüber autoritativen wissenschaftlichen Quellen zu verwenden, was durch zielsichere Anpassungen der Prompting-Strategien korrigiert wurde. Die Zuverlässigkeit des Systems in der Produktion erfordert eine sorgfältige technische Umsetzung. Da die Agenten komplexe, lang laufende Prozesse mit hohem Statusaufwand steuern, müssen Fehler robust abgefangen und Zustände persistiert werden, damit die Arbeit nach Unterbrechungen nahtlos fortgesetzt werden kann. Herkömmliche Neustarts sind nicht praktikabel, da sie Zeitverluste und Frustration für Anwender verursachen würden. Zudem erschwert die dynamische, nichtdeterministische Natur der Agenten die Fehlersuche erheblich.
Anthropic entwickelte daher umfangreiche Monitoring- und Tracing-Werkzeuge, die die Agentenentscheidungen und Interaktionsmuster auf hoher Ebene analysieren, ohne den Inhalt der Nutzerkommunikation preiszugeben. So konnten Schwachstellen identifiziert und effizient adressiert werden. Auch die kontinuierliche Bereitstellung von Updates erfordert einen „Rainbow Deployment“-Ansatz, bei dem neue und alte Versionen parallel betrieben werden. Dies sichert ab, dass keine laufenden Arbeitsprozesse durch inkonsistente Softwarestände unterbrochen werden. Bisher erfolgt die Zusammenarbeit der Subagenten synchron, was die Abstimmung vereinfacht, aber auch den Informationsfluss verlangsamt, da der Lead-Agent auf Ergebnisse warten muss, bevor er fortfährt.
Die nächste Generation plant die Einführung asynchroner Abläufe, die paralleles und flexibleres Arbeiten ermöglichen, wenn Herausforderungen wie das Zusammenführen der Ergebnisse und die Fehlerbehandlung technisch gelöst sind. Zusammenfassend lässt sich sagen, dass die Entwicklung eines Multi-Agenten-Systems für Forschung eine umfassende Ingenieursleistung erfordert, die über das reine Modell-Training hinausgeht. Die feine Abstimmung von Architektur, Prompt-Design, Werkzeugintegration, Evaluationsmethoden und Produktionsengineering entscheidet über den Erfolg. Durch diese innovative Herangehensweise hat Anthropic eine Plattform geschaffen, die komplexe Fragestellungen schneller, flexibler und zuverlässiger als je zuvor bearbeiten kann. Die praktischen Anwendungen sind vielfältig: Von der Unterstützung bei der Entwicklung komplexer Softwaresysteme über die Erstellung professioneller und technischer Inhalte bis hin zur Analyse von Geschäftsmöglichkeiten und akademischen Forschungen.
Nutzer berichten von deutlichen Zeiteinsparungen und erheblichen Erkenntnisgewinnen durch die Fähigkeit des Systems, vernetzte Informationen zu entdecken, die sie selbst übersehen hätten. Dieser Fortschritt markiert einen wichtigen Meilenstein in der praktischen KI-Forschung und zeigt, wie verteilte Intelligenz in Form kooperierender Agenten die Art und Weise revolutioniert, wie Wissen generiert und angewandt wird. Die Erfahrungen und Prinzipien, die Anthropic auf diesem Weg gewonnen hat, bilden eine wertvolle Grundlage für die weitere Entwicklung leistungsfähiger, skalierbarer Multi-Agenten-Anwendungen.





![EDAN: Towards Understanding Memory Parallelism and Latency Sensitivity in HPC [pdf]](/images/1F5A4E42-0B4E-4B09-B14E-E9D8F568DB46)