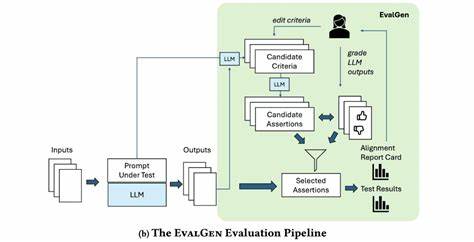
Die rasante Entwicklung von großen Sprachmodellen (Large Language Models, LLMs) hat die Art und Weise revolutioniert, wie wir mit Maschinen kommunizieren und sie für unterschiedlichste Aufgaben einsetzen. Doch die Qualität und Nutzbarkeit dieser Modelle hängen maßgeblich von der Art ab, wie ihre Ausgaben bewertet und validiert werden. Genau hier setzt EvalGen an, ein innovatives Tool, das entwickelt wurde, um die Erstellung von Evaluierungen in der LLM-Entwicklung nicht nur zu erleichtern, sondern vor allem an die individuellen Präferenzen der Entwickler anzupassen. Dieses Werkzeug verspricht einen Paradigmenwechsel im Umgang mit LLM-Eval-Designs und adressiert die zentrale Herausforderung, wie Kriterien zur Bewertung systematisch definiert und angewandt werden können. EvalGen entstand aus dem Bedürfnis heraus, die Komplexität bei der Definition von Evaluationsmetriken zu reduzieren und Entwicklern eine strukturierte, aber dennoch flexible Herangehensweise zur Verfügung zu stellen.
Die Grundidee basiert auf der Erkenntnis, dass Evaluationskriterien nicht statisch sind, sondern durch das eigentliche Bewertungsverfahren entstehen und im Iterationsprozess weiterentwickelt werden. Entwickler werden durch EvalGen dazu angeregt, zuerst qualitatives Feedback zu einigen LLM-Antworten zu geben, um daraufhin Bewertungskriterien explizit zu formulieren und iterativ soweit zu optimieren, bis sie ihren Anforderungen entsprechen. Ein Alleinstellungsmerkmal von EvalGen ist die Fähigkeit, auf einer Kriterien-basierten Ebene zu evaluieren. Anstatt nur eine pauschale Bewertung in Form von „Daumen hoch“ oder „Daumen runter“ zu vergeben, kann der Nutzer jede einzelne Bewertungskategorie definieren und auf die Ausgaben des Modells anwenden. Diese granulare Methode entspricht viel eher den realen Anforderungen an Evaluierungen, bei denen mehrere Dimensionen wie Genauigkeit, Relevanz, Kohärenz oder Stil eine Rolle spielen.
Entwickler haben die Möglichkeit, jederzeit zwischen den einzelnen Arbeitsschritten zu wechseln, ihre Kriterien anzupassen und das Tool erneut Bewertungen generieren zu lassen. Dieser flexible Workflow ist ein entscheidender Fortschritt gegenüber herkömmlichen Ansätzen. Mit der Integration von EvalGen in die ChainForge-Plattform wird der gesamte Prozess zudem visuell unterstützt, was den Einstieg und die Handhabung für Entwickler wesentlich vereinfacht. ChainForge versteht spezielle interne Strukturen wie ResponseObjects und Template-Variablen, welche es ermöglichen, Kontextinformationen nahtlos in Evaluationspromptings zu integrieren. Durch diese technische Tiefe wird sichergestellt, dass die erzeugten Evaluationsfragen und Kriterien nicht nur generisch sind, sondern eng an den eigentlichen Daten und Anwendungsszenarien anknüpfen.
Trotz seiner Leistungsfähigkeit befindet sich EvalGen derzeit noch in der Beta-Phase und bringt einige Einschränkungen mit sich. Zum Beispiel unterstützt es aktuell nur ja/nein-basierte Aussagen zur Bewertung und keine numerischen oder kategorialen Skalen. Zudem kann der Betrieb mit OpenAI's GPT-4o recht kostenintensiv werden, vor allem bei einer steigenden Anzahl von LLM-Ausgaben, die evaluiert werden sollen. Dennoch ist die Transparenz über die Anzahl der Aufrufe ein Pluspunkt, der den Nutzern ermöglicht, Kosten und Effizienz im Blick zu behalten. Auch das Sampling-Verfahren, das maximal 16 Antworten pro Zyklus analysiert, stellt einen Kompromiss zwischen Genauigkeit und Ressourcenverbrauch dar und könnte in zukünftigen Versionen weiter optimiert werden.
Die Möglichkeit, Kriterien jederzeit zu ändern und Feedback iterativ einzupflegen, reflektiert eine agile Herangehensweise, die in der Softwareentwicklung längst Standard ist, aber in der Evaluierung von KI-Ausgaben bislang wenig berücksichtigt wurde. EvalGen fördert damit eine tiefere Auseinandersetzung mit dem, was eine gute Antwort eines LLMs tatsächlich ausmacht und wie diese Qualität messbar gemacht werden kann. Dieser Prozess hilft nicht nur dabei, bessere Evaluationsmodelle zu generieren, sondern sorgt auch für eine stärkere Nachvollziehbarkeit und Validität der Bewertungen. Ein weiterer interessanter Aspekt von EvalGen ist die Offenheit gegenüber der Community. Als Open-Source-Projekt lädt es Entwickler ein, aktiv an der Weiterentwicklung mitzuwirken.
Ob es darum geht, neue Bewertungsmetriken zu integrieren, den Support für weitere LLM-Anbieter zu erweitern oder die grafische Benutzeroberfläche zu verbessern – die Partizipation der Nutzer ist Teil des Entwicklungsprozesses. Diese kooperative Haltung könnte dabei helfen, eine breite Akzeptanz und Nutzung für verschiedene Anwendungsbereiche zu erzielen. Die Relevanz von EvalGen wird auch durch die anhaltende Diskussion über „Criteria Drift“ unterstrichen. Dabei handelt es sich um das Phänomen, dass sich Bewertungsmaßstäbe im Laufe der Zeit ohne bewusste Kontrolle verändern können, was etwa bei großen und komplexen Modellen problematisch sein kann. EvalGen bietet durch seinen iterativen, feedback-getriebenen Workflow eine Option, Kriterien stabil und nachvollziehbar zu halten und so die Konsistenz der Evaluationsergebnisse langfristig zu sichern.
Dadurch, dass der Prozess von der Auswahl der Testantworten bis hin zur finalen Bewertung eng miteinander verzahnt ist, entstehen weniger Missverständnisse darüber, welche Aspekte bei der Leistungsbewertung eines Sprachmodells tatsächlich relevant sind. Entwickler sind in der Lage, EvalGen als Werkzeug zu nutzen, das nicht nur die Qualität des Modells in ihrem spezifischen Kontext erfasst, sondern auch kontinuierlich auf ihre sich verändernden Anforderungen angepasst wird. Mit Blick auf die Zukunft ist EvalGen Teil eines größeren Trends im Bereich LLMOps, der darauf abzielt, die Entwicklung, Überwachung und Bewertung von Sprachmodellen effizienter und vertrauenswürdiger zu gestalten. Tools wie LangSmith, Autoblocks.ai oder Chroma implementieren ebenfalls neue Features, basierend auf ähnlichen Ideen der maßgeschneiderten Evaluierung, aber EvalGen punktet vor allem durch seine tiefgreifende Unterstützung für iterative, kriterienbasierte Bewertung direkt in einem Visual Programming Environment.
Darüber hinaus zeigt der Erfolg von EvalGen, wie wichtig es ist, den menschlichen Faktor bei der Modellbewertung nicht zu vernachlässigen. Automatisierte Scores und standardisierte Metriken haben ihre Berechtigung, allerdings bleibt die Definition von Qualitätsmaßstäben eine zutiefst menschliche Aufgabe, die nur schwer allein durch Algorithmen zu lösen ist. EvalGen vermittelt hier einen idealen Mittelweg, indem es Menschen gezielt unterstützt und gleichzeitig die Möglichkeiten von KI nutzt, um den Prozess effizienter zu gestalten. Für Entwickler, die sich mit der Herausforderung auseinandersetzen, wie sie zuverlässig und nach ihren eigenen Ansprüchen evaluieren können, stellt EvalGen eine bahnbrechende Ressource dar. Es senkt die Einstiegshürde, ermöglicht schnelles Experimentieren mit verschiedenen Kriterien und fördert das Vertrauen in die Evaluationsprozesse.
Mit der stetigen Weiterentwicklung und dem Engagement der Community besteht großes Potenzial, EvalGen zu einem unverzichtbaren Werkzeug in der LLM-Welt zu machen. Die Verbindung von Nutzerfreundlichkeit, technischer Tiefe und Offenheit spricht sowohl Einsteiger als auch erfahrene Entwickler an. Insgesamt wirkt EvalGen wie ein Bindeglied zwischen den Anforderungen moderner KI-Produktentwicklung und den menschlichen Elementen, die für aussagekräftige Modellbewertungen unersetzlich sind. Die kommenden Monate werden zeigen, wie sich dieses vielversprechende Tool in der Praxis bewährt und welche Innovationsschübe es im Bereich der LLM-Evaluierung mit sich bringt.