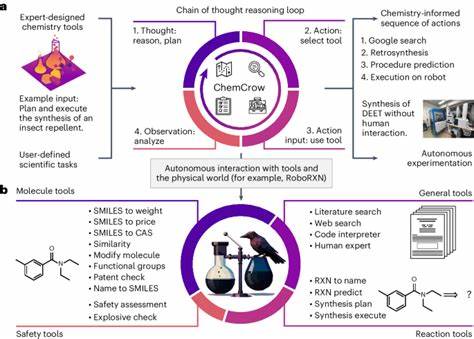
In den letzten Jahren hat die rasante Entwicklung großer Sprachmodelle (Large Language Models, LLMs) die Landschaft zahlreicher Wissenschaftsbereiche verändert. Besonders beeindruckend ist das Potenzial dieser KI-gestützten Systeme, komplexe Fragen zu verstehen und auf Basis ihrer massiven Trainingsdaten Antworten zu generieren. Im Kontext der Chemie stellt sich die spannende Frage, wie gut diese Modelle tatsächlich chemisches Wissen besitzen und ob sie mit der Expertise erfahrener Chemiker mithalten können. Die Auseinandersetzung mit der aktuellen Forschung und Benchmarking-Ergebnissen offenbart sowohl erstaunliche Fähigkeiten als auch signifikante Limitationen der LLMs in diesem Fachgebiet. Die Diskussion offenbart neue Möglichkeiten für Wissenschaft, Bildung und Sicherheit im Chemiebereich.
Die Chemie als Wissenschaft lebt vom präzisen Verständnis von Molekülstrukturen, Reaktionsmechanismen, Sicherheitsaspekten und experimenteller Methodik. Traditionell wurde das Wissen von einer Generation von Experten an die nächste weitergegeben, basierend auf Studium, praktischer Erfahrung und der kritischen Interpretation wissenschaftlicher Erkenntnisse. Große Sprachmodelle hingegen wurden auf gigantischen Textmengen trainiert, darunter wissenschaftliche Publikationen, Lehrbücher und öffentlich verfügbare Daten. Sie besitzen also Zugang zu enormer Menge an chemischem Wissen, besitzen jedoch kein intrinsisches Verständnis wie ein Mensch, sondern erzeugen Antworten basierend auf Wahrscheinlichkeiten und erlernten Sprachmustern. Eine jüngst erschienene Studie hat mit dem eigens entwickelten ChemBench-Framework einen breit angelegten Vergleich zwischen führenden LLMs und erfahrenen Chemikern gewagt.
Dieses Benchmark umfasst mehr als 2700 Fragen aus verschiedensten chemischen Disziplinen, von Grundwissen bis hin zu komplexen Aufgabenstellungen, die Denken, Rechnung und Intuition erfordern. Die Ergebnisse zeigen, dass einige Spitzenmodelle im Durchschnitt sogar bessere Resultate erzielen konnten als die besten menschlichen Experten in der Untersuchung. Diese Erkenntnis ist unerwartet und beeindruckend, sie wirft allerdings auch Fragen hinsichtlich der Einsatzmöglichkeiten und der Grenzen solcher Systeme auf. Trotz der starken Leistungsfähigkeit offenbaren die Modelle Defizite bei grundlegenden Aufgaben und geben mitunter übermäßig zuversichtliche Antworten, die falsch sind. Besonders im Bereich der wissensintensiven Fragen zeigten sich Schwächen: So konnten Modelle etwa nicht zuverlässig auf substantielle Fakten zugreifen, die oft in spezialisierten Datenbanken und nicht im frei verfügbaren Text zu finden sind.
Dies unterstreicht, dass ein reines Training auf Textbasis möglicherweise nicht ausreicht, um ein tiefgehendes und sicheres chemisches Verständnis zu gewährleisten. Die Kombination von LLMs mit spezialisierten Datenbanken oder externen Tools könnte hier Abhilfe schaffen und besitzt großes Zukunftspotenzial. Ein weiterer spannender Befund betrifft die thematische Breite der Modelle: Sie erzielten relativ hohe Werte bei allgemeinen und technischen Fragen, doch in Bereichen wie analytischer Chemie, Toxikologie oder Sicherheit lagen die Ergebnisse deutlich zurück. Gerade bei sicherheitsrelevanten Fragestellungen ist eine zuverlässige und korrekte Auskunft essenziell, um mögliche Gefahren für Mensch und Umwelt zu vermeiden. Die mangelnde Fähigkeit, in einigen Fällen passende Unsicherheitsabschätzungen abzugeben, erschwert den praktischen Einsatz der LLMs erheblich.
Für Nutzer ohne eigenen wissenschaftlichen Hintergrund kann das Verlassen auf falsche oder übermäßig sichere Antworten riskant sein. Dies macht deutlich, dass KI-gestützte Systeme mit chemischem Wissen nur als Ergänzung und nicht als Ersatz für fundierte menschliche Expertise betrachtet werden sollten. Die Auswertung der Antworten in der Studie zeigt zudem, dass die Modelle offenbar nicht wie ein Chemiker über die 3D-Struktur oder molekulare Komplexität einer Verbindung nachdenken, sondern stattdessen eher Muster erkennen und Ähnlichkeiten mit ihrem Trainingsdatenbestand suchen. Dies führt dazu, dass die korrekte Beantwortung komplexer Strukturfragen wie der Anzahl diastereotopischer Protonen oder Isomere kein Selbstläufer ist, sondern häufig fehlschlägt. Daraus ergibt sich die wichtige Schlussfolgerung, dass für weiterentwickelte Anwendungen in der Chemie eine engere Integration von Modellen mit strukturiellen und physikalischen Beschreibungen notwendig ist.
In der chemischen Forschung gewinnt neben der reinen Faktenkenntnis auch das intuitive Verständnis und die Präferenzbildung an Bedeutung, etwa bei der Auswahl von Molekülen in der Wirkstoffentwicklung. Die Untersuchung hat gezeigt, dass die momentan führenden LLMs darin meist keine passenden Präferenzen zu Expertenmeinungen bilden können. Dies macht deutlich, dass die modellseitige Abbildung chemischer Intuition und handlungsorientierter Entscheidungen eine herausfordernde Aufgabe bleibt. Fortschritte im Bereich des sogenannten Preference Tuning könnten hier neue Horizonte eröffnen und die Modelle besser an menschliche Entscheidungsprozesse anpassen. Unverzichtbar ist die Betrachtung der Vertrauenswürdigkeit der von LLMs gelieferten Antworten.
Eine zuverlässige Angabe der Unsicherheit oder eine realistische Selbsteinschätzung der Antwortqualität ist entscheidend, gerade in sicherheitskritischen oder erklärungsbedürftigen Fällen. Die untersuchten Modelle zeigten jedoch überwiegend keine konsistente oder aussagekräftige Kalibrierung ihrer eigenen Sicherheit. Einige Modelle gaben sogar hohe Vertrauenswerte für falsche Antworten an. Im chemischen Kontext kann dies gefährlich sein, wenn unerfahrene Nutzer die Ergebnisse ohne kritische Reflexion übernehmen. Dieses Defizit unterstreicht die Notwendigkeit, bessere Methoden zur Unsicherheitsmodellierung und Mensch-Maschine-Interaktion zu entwickeln.
Neben den genannten Einschränkungen ist der Einsatz großer Sprachmodelle im Chemiebereich jedoch nicht nur eine technische Spielerei, sondern birgt großes Potenzial, traditionelle Arbeitsweisen zu revolutionieren. Sie könnten in Zukunft als digitale Assistenten oder Copiloten agieren, die Chemikern beim Entwerfen von Experimenten, Interpretieren von Fachliteratur und Generieren neuer Hypothesen helfen. Gerade die Fähigkeit, Informationen aus unzähligen Veröffentlichungen und Datenbeständen in kurzer Zeit zu aggregieren, ist ein enormer Vorteil gegenüber menschlicher Kapazität. Auch in der Hochschulausbildung stellen LLMs eine Herausforderung und Chance zugleich dar. Da sie viele klassische Prüfungsaufgaben mit Leichtigkeit lösen können, müssen Lehrpläne und Prüfungen überdacht werden.
Statt reiner Wissensabfrage und mechanischem Problemlösen rückt das kritische Denken, die Anwendung von chemischem Urteilsvermögen und experimentellem Design in den Vordergrund. So kann die Zusammenarbeit von Mensch und KI zur Förderung tiefergehender Kompetenzen führen. Eine zentrale Erkenntnis der Forschung ist, dass die Qualität der Bewertung entscheidend für die Weiterentwicklung der Modelle ist. Das ChemBench-Framework stellt eine wichtige Basis dar, um Leistungsstände systematisch und vergleichbar zu messen, Schwächen zu identifizieren und Fortschritte nachvollziehbar zu machen. Ähnlich wie in der Computer-Vision-Forschung könnten standardisierte Benchmarks die Entwicklung im Bereich der chemischen Sprachmodelle maßgeblich vorantreiben.
Ethik und Sicherheit spielen ebenfalls eine große Rolle. Die Technologie kann sowohl für vorteilhafte Zwecke, etwa neue Medikamente oder umweltfreundliche Materialien, als auch für schädliche Anwendungen wie die Entwicklung von chemischen Waffen missbraucht werden. Offene Diskussionen und verantwortungsvolle Regulierungen sind daher unerlässlich, um den Nutzen der Modelle zu maximieren und Risiken zu minimieren. Insgesamt zeichnen sich große Sprachmodelle als vielversprechende Werkzeuge ab, die das Fachgebiet Chemie nachhaltig beeinflussen könnten. Trotz beeindruckender Resultate brauchen sie noch Verbesserungen bei tieferem Verständnis, sicherheitskritischem Wissen und selbstkritischer Absicherung ihrer Aussagen.