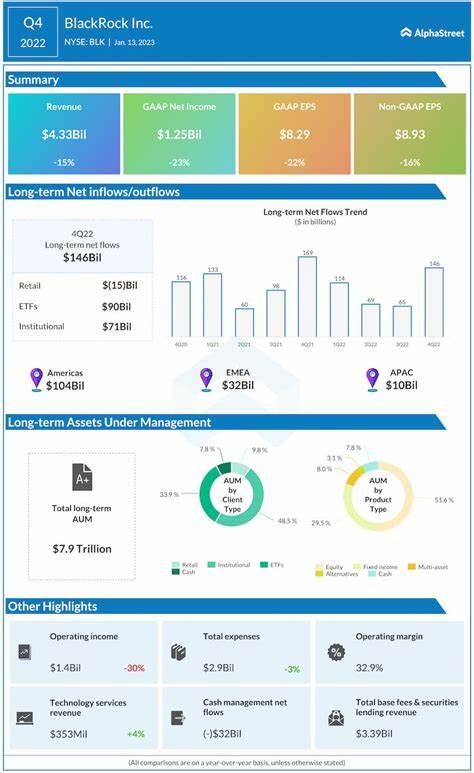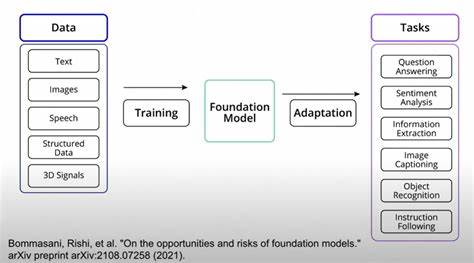
Das Konzept des Long-Tail Learning gewinnt in der heutigen Zeit immer mehr an Bedeutung, insbesondere im Bereich der künstlichen Intelligenz und des maschinellen Lernens. Long-Tail Learning befasst sich mit der Herausforderung, dass viele Datensätze oft eine stark ungleiche Verteilung von Klassen aufweisen. Während einige Klassen sehr häufig auftreten, gibt es zahlreiche Klassen mit nur wenigen Beispielen, die sogenannten Tail-Klassen. Die effektive Behandlung dieser seltenen Klassen ist entscheidend für die Leistung vieler Modelle, vor allem bei Anwendungen wie Bildklassifikation oder natürlichen Sprachverarbeitungen. In diesem Kontext spielt die Methode LIFT+ eine zentrale Rolle, die mit einer neuartigen Herangehensweise an das Fine-Tuning von Foundation-Modellen überzeugt und sowohl Genauigkeit als auch Effizienz nachhaltig verbessert.
Das Fine-Tuning hat sich als einer der erfolgreichsten Ansätze etabliert, um vortrainierte große Modelle für spezifische Aufgaben anzupassen. Doch gerade bei Long-Tail Learning wurde bisher wenig darüber gesprochen, welche Fine-Tuning Strategien wirklich effektiv sind. Die gängige Praxis, eine große Anzahl von Modellparametern intensiv anzupassen, kann nicht nur zu längeren Trainingszeiten führen, sondern auch zu einer Verschlechterung der Leistung auf seltenen Klassen. Diese Erkenntnis hat zur Entwicklung von LIFT+ geführt – einem Framework, das mit leichtgewichtigem Fine-Tuning das Potenzial von Foundation-Modellen optimal ausschöpft. Das Grundprinzip hinter LIFT+ besteht darin, nur einen minimalen Teil der Modellparameter während der Feinabstimmung zu aktualisieren.
Dieser Ansatz verhindert, dass die Modellverteilung zu stark von der ursprünglichen Trainingsverteilung abweicht, was bei starkem Fine-Tuning zu widersprüchlichen Klassenkonditionen führen kann. Gerade die Tail-Klassen profitieren von dieser stabilisierenden Wirkung, da sie sonst oft durch Überanpassung an häufige Klassen verdrängt werden. Diese insight wurde durch umfassende theoretische Analysen untermauert und anschließend in umfangreichen Experimenten validiert. Neben der minimalistischen Anpassung legt LIFT+ besonderes Augenmerk auf eine semantisch bewusste Initialisierung. Das bedeutet, dass die initialen Parameter schon so gewählt werden, dass sie wesentliche semantische Informationen aus den Daten berücksichtigen.
Dies erleichtert nicht nur die Anpassung des Modells an neue Klassen, sondern sorgt auch für eine bessere Generalisierung. Zudem integriert LIFT+ eine dezente Datenaugmentierung, die gezielte und kompakte Veränderungen in den Trainingsdaten einführt. Diese beinhalten leichte Variationen, welche die Robustheit des Modells gegenüber Datenfluktuationen erhöhen, ohne zusätzliche Trainingskomplexität zu erzeugen. Ein weiterer signifikanter Beitrag von LIFT+ ist die Einführung eines Test-Time-Ensembling. Hierbei werden während der Auswertungsphase mehrere Vorhersagen kombiniert, um eine stabilere und genauere Klassifikation zu erzielen.
Dieses Verfahren verbessert die Modellperformance ohne zusätzlichen Trainingsaufwand und zeigt besonders bei schwierigeren Long-Tail-Datensätzen deutliche Vorteile. Die Kombination all dieser Komponenten führt dazu, dass LIFT+ nicht nur deutlich schneller konvergiert, sondern auch wesentlich kompakter bleibt. So reduziert das Framework die Trainingszeit von etwa 100 auf weniger als 15 Epochen und trainiert dabei weniger als ein Prozent der Modellparameter. Diese Effizienzsteigerung bringt erhebliche Vorteile für den praktischen Einsatz, insbesondere wenn ressourcenschwache Umgebungen berücksichtigt werden müssen. Darüber hinaus belegt eine Vielzahl von Experimenten, dass LIFT+ aktuelle State-of-the-Art-Methoden in puncto Genauigkeit bei Long-Tail Learning übertrifft.
Die Forschung demonstriert die Anwendbarkeit auf diverse Datensätze und Szenarien im Bereich Computer Vision und darüber hinaus. Damit stellt LIFT+ eine wegweisende Verbesserung dar, die sowohl Wissenschaftlern als auch Entwicklern neue Möglichkeiten eröffnet, um herausfordernde Klassifikationsprobleme effizient zu lösen. In der heutigen Welt, in der große vortrainierte Modelle wie Foundation-Modelle vermehrt eingesetzt werden, stellt LIFT+ eine bedeutende Innovation dar, die den Weg zu einem ressourcenschonenderen und zugleich leistungsfähigeren Fine-Tuning ebnet. Die Veröffentlichung des Quellcodes sorgt zusätzlich für eine breite Zugänglichkeit und schnelle Adaption durch die Fachcommunity. Zusammenfassend ist LIFT+ ein fortschrittliches Framework, das durch leichtgewichtiges Fine-Tuning, semantisch bewusste Initialisierung, minimale Datenaugmentation sowie intelligentes Test-Time-Ensembling die Herausforderungen des Long-Tail Learning wirkungsvoll adressiert.
Es optimiert gleichzeitig Effizienz und Präzision, was es zu einem unverzichtbaren Werkzeug für die nächste Generation von KI-Modellen macht. Wer sich mit Deep Learning, insbesondere im Bereich unbalancierter Datensätze beschäftigt, kommt an den Erkenntnissen und Möglichkeiten von LIFT+ kaum vorbei.