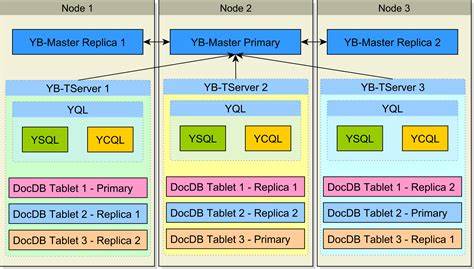
Mit dem rasanten Fortschritt im Bereich künstlicher Intelligenz gewinnen Vektorindizes zunehmend an Bedeutung. Ob bei der semantischen Suche, Empfehlungssystemen oder bei Retrieval-Augmented Generation (RAG) – die Fähigkeit, hochdimensionale Vektordaten effizient zu speichern, zu indexieren und abzufragen, bestimmt maßgeblich die Leistungsfähigkeit moderner AI-Anwendungen. In diesem Zusammenhang hebt sich YugabyteDB als eine zukunftsweisende verteilte SQL-Datenbank hervor, die eine native Vektorindizierung mit PostgreSQL-Kompatibilität bietet und damit neue Maßstäbe im Bereich skalierbarer, KI-fokussierter Datenbanken setzt. YugabyteDB basiert auf einem verteilten Datenbank-Framework, das horizontale Skalierung, Multi-Region-Replikation und hohe Ausfallsicherheit gewährleistet. Wesentlich dabei ist die Integration eines spezialisierten Vektorindex-Subsystems, das eng mit der Postgres-kompatiblen Schnittstelle verbunden ist.
Entwickler und Datenbankadministratoren können so Vektorspalten definieren, spezielle Vektorindizes erstellen und diese mittels SQL abfragen – ganz ohne sich in proprietäre APIs oder neue Werkzeuge einarbeiten zu müssen. Die Vektorindexarchitektur von YugabyteDB basiert auf dem sogenannten Vector LSM-Ansatz, einer an Log-Structured Merge Trees (LSM-Trees) angelehnten Struktur, die jedoch speziell für hochdimensionale Vektordaten konzipiert ist. Diese modulare und pluggable Architektur trennt die Vektorindexlogik von der übrigen Datenbank-Engine, wodurch flexibler Austausch und Integration verschiedener ANN-Approximate Nearest Neighbor_Backends möglich wird. Aktuell greift YugabyteDB hier auf USearch als Standard-Engine zurück, eine moderne HNSW-basierte Implementierung, die durch ihre Effizienz und Speicheroptimierung überzeugt. Die Abläufe im Vector LSM sind durchdacht und für die Anforderungen großer, verteilter Systeme optimiert.
Vektoren werden zunächst in einem In-Memory-Puffer gesammelt und dort indexiert. Sobald dieser Pufferspeicher seine Kapazitätsgrenze erreicht, erfolgt eine persistente Speicherung auf der Festplatte als unveränderliche Vektor-Chunks. Bei Suchanfragen erfolgt eine parallele Abfrage über alle im Speicher befindlichen sowie auf der Festplatte gespeicherten Indexsegmente. Die Ergebnisse werden mithilfe der Multi-Version Concurrency Control (MVCC) gefiltert, um konsistente und aktuelle Resultate auch bei parallelen Schreibvorgängen zu gewährleisten. Ein besonders cleveres Designmerkmal ist die Ko-Partitionierung der Vektorindizes mit den Haupttabellen.
Indizes und entsprechende Datensätze werden gemeinsam in den gleichen Tablets abgelegt, was erhebliche Vorteile bei Latenz und Effizienz bietet. Daten- und Indexzugriffe finden lokal statt, wodurch teure Netzwerkoperationen, etwa zur Abfrage über Shard-Grenzen hinweg, entfallen. Zudem können Filterkriterien direkt zusammengenutzt werden, sodass sowohl SQL-Predicate als auch Vektorähnlichkeitssuchen gemeinsam und performant ausgewertet werden können. Durch die Speicherung im gleichen Raft-Log für Replikation und Konsistenz entfallen komplexe Transaktionsprobleme zwischen Tabelle und Index. Durch die globale Verteilung der Daten in Form von Tablets, die jeweils einen Teil des Vektorindex beherbergen, lässt sich eine enorme Parallelität bei Suchanfragen erzielen.
Eine Anfrage wird an sämtliche Tablets gleichzeitig gesendet, die jeweils lokal die besten Treffer ermitteln. Diese Zwischenergebnisse werden anschließend aggregiert, um eine globale Top-K-Liste zu erzeugen. Dieser Ansatz minimiert Engpässe und ermöglicht eine effiziente Lastverteilung auf alle Clusterknoten – unerlässlich bei großen Vektor-Datensätzen mit Milliarden von Einträgen. YugabyteDB ist von Anfang an auf horizontale Skalierbarkeit ausgelegt. Die elastische Verwaltung der Tablets sorgt für eine automatische Ausbalancierung bei Hinzufügen oder Entfernen von Knoten.
Wachstum des Datenvolumens wird durch automatische Tablet-Splitting-Prozesse ebenso abgefangen wie die Replikation und Verteilung über verschiedene Regionen weltweit. Diese Mechanismen garantieren eine nahezu lineare Skalierung der Leistung, ohne dass manueller Eingriff oder komplexe Konfigurationen nötig sind. Neben Performance ist Ausfallsicherheit ein weiterer zentraler Fokus. YugabyteDB nutzt die Robustheit seines verteilten Konsensprotokolls (Raft), um die Integrität und Konsistenz der Vektorindizes zu sichern. MVCC sorgt für konsistente Lesevorgänge inmitten von parallelen Schreibtransaktionen, und nach Abstürzen erfolgt eine zeitlich abgestimmte Wiederherstellung über Write-Ahead-Logging (WAL).
Das Management von vektorbezogenen ID-Mappings innerhalb von RocksDB gewährleistet eine stabile Adressierung auch bei Updates und Löschungen, wodurch der Index stets valide und performant bleibt. USearch als Kern-Annäherungsengine liefert viele Vorteile. Diese moderne, C++-basierte Bibliothek zeichnet sich durch eine besonders kompakte und performante Umsetzung des HNSW-Algorithmus aus, welcher hinsichtlich Suchgeschwindigkeit teilweise um den Faktor zehn schneller ist als etablierte Alternativen wie FAISS. Möglich ist dies unter anderem durch SIMD-Optimierungen und eine schlanke Architektur ohne unnötigen Overhead. Im Unterschied zu rein im Speicher arbeitenden Engines unterstützt USearch zudem eine speicherabbildbasierte Persistenz, wodurch auch extrem große Vektorindizes ohne Speicherengpässe nachhaltig verarbeitet werden können.
Ein weiteres Highlight der Integration ist die Fähigkeit zur Prädikatspushdown-Filterung. MVCC-basierte Filter, wie beispielsweise Zeitstempel- oder Löschkriterien, werden direkt in die ANN-Suche eingespeist und dort verwendet, um unnötige Nachbearbeitungsschritte zu vermeiden und die Abfragelatenz weiter zu reduzieren. Dies erhöht die Effizienz besonders bei komplexeren Workloads, bei denen neben der reinen Vektorähnlichkeit auch klassische relationale Filter relevant sind. Darüber hinaus ermöglicht USearch eine hohe Flexibilität bei den verwendeten Distanzmetriken. Während aktuell hauptsächlich L2- und Kosinus-Abstände eingesetzt werden, ist durch die Unterstützung benutzerdefinierter, sogar kompilierter Metriken eine zukünftige Erweiterung auf spezielle Anwendungsfälle denkbar.
So könnten branchenspezifische Distanzfunktionen, etwa Haversine für geographische Daten oder Tanimoto für molekulare Strukturen, implementiert werden, wodurch YugabyteDB auch in wissenschaftlichen oder spezialisierten Industrieanwendungen punkten kann. Für Entwickler und Unternehmen, die auf die Entwicklung von KI-nativen Anwendungen setzen, bietet YugabyteDB somit ein umfassendes und robustes Fundament. Die vertraute, SQL-basierte Bedienoberfläche adressiert eine breite Nutzerschaft und integriert sich problemlos in bestehende Toolchains und Frameworks. Gleichzeitig sorgt die moderne, verteilte Vector-Indexing-Architektur für Skalierbarkeit, Zuverlässigkeit und Performance auch bei anspruchsvollsten Anforderungen im Bereich der KI-gestützten Datenverarbeitung. Fazit: YugabyteDB definiert mit seiner Vector Indexing Architecture, basierend auf der USearch-Engine, einem skalierbaren, verteilten Ansatz und tiefer PostgreSQL-Kompatibilität neu, wie produktionsreife Vektor-Datenbanken in der Praxis funktionieren.
Dies macht die Plattform nicht nur für Retrieval-Augmented Generation, semantische Suche und Recommendation Engines attraktiv, sondern auch für ein breites Spektrum an zukunftsorientierten KI-Applikationen, die eine Kombination aus Intelligenz, Geschwindigkeit und geografischer Verteilung benötigen. Dank dieser Entwicklungen bietet YugabyteDB einen mächtigen Baustein zur Realisierung skalierbarer, performanter und hochverfügbarer AI-gestützter Systeme in der Cloud-Ära.