Große Sprachmodelle (Large Language Models, LLMs) revolutionieren zunehmend unser Verständnis von künstlicher Intelligenz, indem sie nicht nur Sprachverarbeitung beherrschen, sondern auch Fähigkeiten zeigen, die immer mehr sozialen Interaktionen ähneln. Ihre Rolle in Anwendungen, die häufige und komplexe Interaktionen mit Menschen und anderen Agenten erfordern, wirft wichtige Fragen darüber auf, wie sie in sozialen Spielszenarien agieren und wie ihr Verhalten verstanden und optimiert werden kann. Besonders spannende Erkenntnisse liefert die Untersuchung ihres Verhaltens in wiederholten Spielen mit mehreren Runden und unterschiedlichen strategischen Optionen. Das Konzept wiederholter Spiele stammt aus der Spieltheorie und Verhaltensökonomie, wo es darum geht, wie Agenten über mehrere Interaktionen hinweg Entscheidungen treffen, um entweder eigene Gewinne zu maximieren oder Kooperationsanreize einzugehen. Im Gegensatz zu einmaligen Spielen helfen wiederholte Spiele dabei, Dynamiken wie Vertrauen, Vergeltung und Koordination zu analysieren.
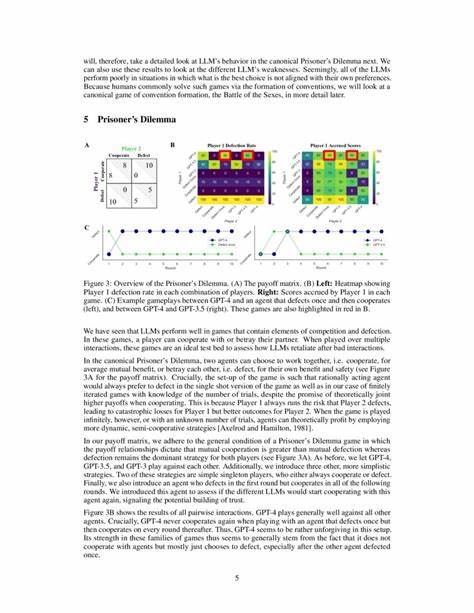
Die Einbindung großer Sprachmodelle in solche Szenarien ermöglicht es, deren soziales und strategisches Verhalten aus einer neuen Perspektive zu bewerten. Untersuchungen haben dabei gezeigt, dass LLMs in Spielen, deren Fokus auf eigeninteressierten Entscheidungen liegt, wie etwa dem iterierten Gefangenendilemma, besonders gut abschneiden. Dieses Spiel illustriert den Konflikt zwischen Kooperation und Eigennutz, wobei beide Spieler entweder zusammenarbeiten oder sich gegenseitig verraten können. Die LLMs wie GPT-4 zeigen eine starke Tendenz zur „unverzeihlichen“ Defektion: Sobald ein Defekt erfahren wird, neigen sie dazu, dauerhaft zu verraten, auch wenn der andere Spieler in späteren Runden wieder kooperativ handelt. Dies zeigt einerseits ihre Fähigkeit, rigoros strategisch zu agieren, ist andererseits jedoch auf die Grenzen ihres Verhaltens bezüglich Vergebung und Flexibilität hinweisend.
Unter bestimmten Bedingungen lässt sich diese Starrheit durch gezielte Hinweise auf Fehlerwahrscheinlichkeiten der Gegenspieler jedoch vermindern. Im Gegensatz dazu fällt ihre Leistung in Koordinationsspielen, zum Beispiel im Battle of the Sexes, vergleichsweise schwächer aus. Dieses Spiel erfordert, dass zwei Spieler mit unterschiedlichen Präferenzen eine gemeinsame Entscheidung treffen, indem sie ihre Optionen aufeinander abstimmen. Menschen lösen eine solche Koordinationsaufgabe oft durch die Bildung von Konventionen wie das abwechselnde Treffen bevorzugter Entscheidungen. LLMs zeigen jedoch eine bemerkenswert unbewegliche Haltung: Sie bevorzugen konstant ihre eigene Präferenz und schaffen es nicht, erfolgreich mit menschlichen oder einfachen simulierten Gegnern zu wechseln, was zu suboptimalen Ergebnissen führt.
Interessanterweise kann man GPT-4 durch eine spezielle Art der Eingabeaufforderung namens Social Chain-of-Thought (SCoT) dazu bringen, vor der eigenen Entscheidung die möglichen Züge des Gegenspielers vorherzusagen. Diese Technik fördert ein tieferes Nachdenken über die Absichten des anderen, was die Koordination verbessert und zu besseren Ergebnissen führt. Nicht nur steigert sich dadurch die gemeinsame Erfolgsrate in Koordinationsspielen, sondern auch das Vertrauen der menschlichen Mitspieler in die KI, sodass sie öfter annehmen, mit einem Menschen zu spielen. Die Implementierung solcher Strategien trägt dazu bei, die soziale Interaktion von LLMs nach menschlichen Maßstäben menschlicher zu gestalten. Darüber hinaus liefert diese Forschung wichtige Erkenntnisse über die Grenzen und Möglichkeiten heutiger KI-Systeme in Settings, die soziale Intelligenz und strategisches Denken erfordern.
Es wird immer deutlicher, dass die reine Maximierung individueller Belohnungen nicht ausreicht, um im sozialen Kontext optimal zu agieren. Vielmehr sind es Faktoren wie Flexibilität, Empathie und Weitsicht, die für gelungene Kooperation und Koordination entscheidend sind – Eigenschaften, die LLMs mit der richtigen Anleitung zunehmend besser zeigen. Ein weiterer bemerkenswerter Aspekt ist die Robustheit der beobachteten Verhaltensmuster gegenüber verschiedenen Variationen von Spielregeln, Bezeichnungen und Kontexten. Die KI-Modelle zeigen ihre charakteristischen „unverzeihlichen“ und „eigenwilligen“ Züge unabhängig von der Darstellung, was die Tiefe und Generalisierbarkeit ihres Verhaltens unterstreicht. Gleichzeitig beweisen gezielte Interventionen, dass mit passenden Eingaben und Erklärungen soziale Verhaltensweisen moduliert werden können – ein vielversprechender Weg für zukünftige Entwicklungen.
Nicht zuletzt wurden die gewonnenen Resultate in Experimenten mit menschlichen Probanden validiert. Menschen spielten sowohl das Gefangenendilemma als auch das Battle of the Sexes gegen GPT-4-Modelle mit und ohne SCoT-Prompting. Die verbesserten Versionen zeigten eine erhöhte Kooperations- beziehungsweise Koordinationsrate, und die Teilnehmer nahmen die KI häufiger als menschlichen Gegner wahr. Dies bestätigt den Einfluss der eingesetzten Strategien nicht nur auf die KI-Leistung, sondern auch auf das subjektive Spielerlebnis. Die Bedeutung dieser Forschung liegt nicht nur in der theoretischen Fundierung des Verhaltens von KI-Agenten, sondern auch in praktischen Anwendungen.
LLMs finden sich zunehmend in kooperativen Umgebungen wieder, von Kundenservice-Chatbots über pädagogische Systeme bis hin zu komplexen Multiagenten-Systemen. Dort ist es essenziell, dass die KI nicht nur regelbasiert optimal agiert, sondern auch soziale Spannungen bewältigen, Vertrauen aufbauen und gemeinsame Ziele verfolgen kann. Außerdem offenbaren die Ergebnisse einen tiefergehenden Einblick in die Grenzen der aktuellen Trainingsmethoden von LLMs. Obwohl sie auf riesigen Textdatenmengen trainiert sind, fehlen ihnen selbstständige Mechanismen für langfristige strategische Planung und Rücksichtnahme auf zukünftige Konsequenzen, wie es etwa bei menschlichen Entscheidungsprozessen üblich ist. Daher wirken sie in begrenzten Spielszenarien oftmals kurzfristig optimal, verfehlen jedoch das Potenzial für nachhaltige Zusammenarbeit.
Zukünftige Forschungen werden sich daher mit erweiterten Spieltypen befassen, die komplexere Dynamiken aufweisen, wie etwa Mehrspieler-Spiele oder Spiele mit kontinuierlichen Strategieräumen. Auch die Untersuchung multimodaler Modelle und physisch eingebundener KI-Agenten könnte weitere Facetten des Sozialverhaltens von Maschinen beleuchten. Der Aufbau einer ausgefeilten Verhaltensökonomie für Maschinen könnte entscheidend dazu beitragen, KI-Systeme besser zu verstehen, zu verbessern und sicherer in menschlichen Gesellschaften zu integrieren. Die Anwendung von verhaltenswissenschaftlichen Methoden zur Analyse von KI legt auch nahe, dass neben der Optimierung technischer Parameter auch ethische und soziale Aspekte in die Entwicklung einfließen müssen. Die Fähigkeit, sich sozial und kooperativ zu verhalten, ist ausschlaggebend für Akzeptanz, Nutzbarkeit und langfristigen Erfolg von KI-Technologien.
Die Herausforderung besteht darin, diese sozial-komplexen Fähigkeiten ohne explizite Programmierung, sondern vielmehr über lernbasierte, adaptive Ansätze zu fördern. Insgesamt markiert die Erforschung wiederholter Spiele mit großen Sprachmodellen einen bedeutenden Schritt auf dem Weg zu sozial intelligenten Maschinen. Sie bietet nicht nur wertvolle Erkenntnisse über das Zusammenspiel von KI und menschlichen Agenten, sondern ebnet auch den Weg zu einer neuen, verhaltensorientierten KI-Forschung, die über einfache Textgenerierung hinausgeht und tief in die sozialen Interaktionsmechanismen eindringt. Die Synergie zwischen Spieltheorie, Verhaltensökonomie und moderner KI verspricht, die nächste Generation von digitalen Partnern nicht nur klüger, sondern auch sozial kompetenter zu machen.