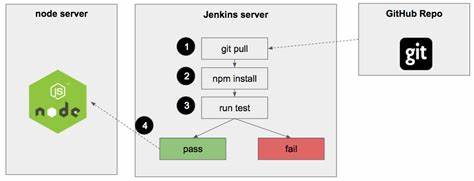
Im Zeitalter der Künstlichen Intelligenz und insbesondere der Sprache basierten Modelle gewinnen effiziente Methoden zur Datenaufbereitung zunehmend an Bedeutung. Large Language Models (LLMs) benötigen sauber strukturierte, inhaltsreiche und kontextbezogene Daten, um präzise und relevante Ergebnisse zu liefern. Während verschiedene Datenquellen genutzt werden, spielen DOCX-Dateien aufgrund ihrer weiten Verbreitung und Flexibilität eine entscheidende Rolle. Doch die Herausforderung besteht darin, diese komplexen Dokumente so zu transformieren, dass sie für LLMs optimal nutzbar sind. Die native Struktur von DOCX-Dateien, die aus vielen unterschiedlichen Elementen Besteht – von Fließtext über Tabellen bis hin zu eingebetteten Bildern und Fußnoten – erfordert spezialisierte Konverter, die weit über einfache Text-Extraktion hinausgehen.
Eine herausragende Lösung bietet der DocxConverter des Frameworks ContextGem, der speziell für die anspruchsvollen Anforderungen bei der Verarbeitung von DOCX-Dokumenten für LLMs entwickelt wurde. Dieses Tool ermöglicht die präzise Extraktion aller relevanter Komponenten eines Word-Dokuments und stellt sicher, dass die jeweiligen Kontextbezüge erhalten bleiben. So werden nicht nur der reine Text, sondern auch die hierarchische Gliederung in Absätze, Überschriften, Listen und Tabellen erkannt und mit umfangreichen Metadaten versehen, was für eine verbesserte semantische Analyse durch Machine-Learning-Modelle von großer Bedeutung ist. Die Fähigkeit des DocxConverters, selbst komplexe Strukturelemente wie verschachtelte Tabellen, Kommentare, Fußnoten, Textfelder, Kopf- und Fußzeilen sowie eingebettete Bilder ohne externe Abhängigkeiten zu verarbeiten, setzt neue Maßstäbe in dieser Domäne. Insbesondere die Erfassung von Kommentaren und deren Verknüpfung mit dem Fließtext eröffnet neue Möglichkeiten zur Kontextualisierung von Dokumentinhalten, was in vielen Anwendungsfällen wichtige Zusatzinformationen bietet, die sonst verloren gehen würden.
Die praktische Umsetzung lässt sich dabei nahtlos in bestehende Python-basierte Workflows integrieren und bietet sowohl die Konvertierung von Pfaden als auch von geöffneten Dateiobjekten an. Zusätzlich erlaubt die Funktion zur Extraktion als reiner Text in verschiedenen Formaten, darunter Markdown, eine flexible Weiterverarbeitung für unterschiedliche Anwendungszwecke. Trotz dieser leistungsfähigen Features verzichtet der DocxConverter bewusst auf die Extraktion charakterbasierter Formatierungen wie Fettdruck oder Kursivschrift, um eine konsistente Zuordnung von Bearbeitungseinheiten zu gewährleisten. Diese Abwägung unterstützt eine robuste und fehlerfreie Verarbeitung von Dokumenten, deren Struktur oft variabel und komplex ist. Es gilt auch zu beachten, dass bei außergewöhnlichen Dokumenten wie Zeichnungen oder verschachtelten Tabellen die Darstellung Herausforderungen mit sich bringen kann, weshalb manche Elemente bewusst ausgespart oder nur rudimentär behandelt werden.
Die Vorteile dieser Herangehensweise liegen auf der Hand: Eine systematische Extraktion der DOCX-Inhalte inklusive ihrer Metadaten schafft eine exzellente Datenbasis, die große Sprachmodelle nutzen können, um Texte besser zu verstehen, präzise Zusammenfassungen zu erstellen oder komplexe Fragen zu beantworten. Dies ist insbesondere im professionellen Umfeld von Bedeutung, in dem große Mengen an Dokumenten automatisiert analysiert werden müssen. Die Transformation von DOCX in ein LLM-kompatibles Format unterstützt damit digitale Transformation in Unternehmen, in Forschung und Entwicklung sowie im Bereich Wissensmanagement. Neue Anwendungen wie automatisierte Compliance-Prüfungen, intelligente Dokumentensuche oder das Extrahieren von wichtigen Insights aus Fachtexten profitieren unmittelbar von der verbesserten Aufbereitung. Wer auf bestehende open-source-Pakete zurückgreifen möchte, wird schnell mit deren Grenzen konfrontiert, da viele dieser Tools nicht alle relevanten Dokumentelemente ausreichend erfassen oder keine tiefergehende Kontextvernetzung vornehmen.
Der DocxConverter von ContextGem wurde genau für diese Herausforderungen entwickelt und bietet die notwendige Tiefe, um die komplexe Struktur von Word-Dokumenten vollständig auszuschöpfen. Die Investition in eine solche spezialisierte Lösung ermöglicht es, die hohe Qualität und Relevanz der Daten für LLM-Prozesse sicherzustellen. Abgesehen von der technischen Innovation hebt sich der Einsatz solcher Tools durch den Verzicht auf externe Abhängigkeiten hervor, was die Integration in verschiedene sichere IT-Umgebungen erleichtert und die Gesamtsystemstabilität erhöht. Auch die Möglichkeit, einzelne Komponenten der Konvertierung – wie Tabellen oder Bilder – gezielt ein- oder auszuschalten, bietet Flexibilität und Anpassungsfähigkeit an spezifische Projektanforderungen. Zusammenfassend lässt sich festhalten, dass die zielgerichtete Umwandlung von DOCX-Dateien in LLM-freundliche Formate einen entscheidenden Schritt darstellt, um die Leistungsfähigkeit moderner KI-Modelle voll auszuschöpfen.
Innovative Converter wie die Lösung von ContextGem stellen dabei nicht nur eine technische Neuerung dar, sondern leisten einen wichtigen Beitrag zur Digitalisierung und Automatisierung von Wissensarbeit. Wer sich mit der Analyse und Verarbeitung großer Dokumentenmengen befasst, sollte die Möglichkeiten, die eine solche Datentransformation bietet, unbedingt für sich nutzen, um Effizienz und Qualität nachhaltig zu steigern. Die Zukunft der Dokumentenverarbeitung liegt in tief integrierten, kontextbewussten Workflows, die intelligente Systeme mit qualitativ hochwertigen und strukturierten Daten versorgen – und genau hier setzt die Transformation von DOCX in LLM-ready Daten an.