Die rasante Entwicklung großer vortrainierter Sprachmodelle hat die Sprachverarbeitung in den letzten Jahren revolutioniert. Transformer-basierte Modelle wie GPT, BERT und ihre zahlreichen Nachfolger ermöglichen heute beeindruckende Resultate in einer Vielzahl von natürlichen Sprachverarbeitungsaufgaben. Allerdings sind diese Modelle sehr umfangreich und ressourcenintensiv. Das Feintuning – also die Anpassung eines solchen Modells auf eine spezifische Aufgabe – erfordert erhebliche Rechenleistung, Speicher und Zeit. Hier setzt der innovative Ansatz der «Selective Adapter Freezing»-Methode, kurz SAFE, an und bietet eine vielversprechende Lösung für die Herausforderung des effizienten Feintunings großer Sprachmodelle mit begrenzten Ressourcen.
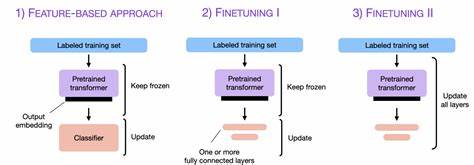
Adapter-Tuning hat sich in den vergangenen Jahren als eine effektive Technik etabliert, um beim Feintuning den Ressourcenaufwand deutlich zu reduzieren. Dabei werden kleine, spezialisierte Module, sogenannte Adapter, in die vortrainierten Modelle eingefügt. Statt das komplette Modell zu verändern, werden nur diese Adapter trainiert, während der Großteil der ursprünglichen Modellparameter fixiert bleibt. Dies führt bereits zu einer deutlich geringeren Anzahl an zu trainierenden Parametern und damit zu einer geringeren Speicher- und Rechenbelastung. Dennoch sind auch herkömmliche Adapter-Tuning-Methoden nicht frei von Nachteilen.
Sie können immer noch signifikanten Speicherbedarf verursachen, insbesondere wenn viele Adapter im Modell integriert sind und alle gleichzeitig trainiert werden. Die bahnbrechende Erkenntnis bei SAFE ist, dass nicht alle Adapter im Modell denselben Beitrag zur Anpassung auf eine neue Aufgabe leisten. Untersuchungen zeigen, dass einige Adaptermodule einen größeren Einfluss auf die Performance des Feintunings haben, während andere kaum wichtige Hinweise zur Verbesserung der Modellgenauigkeit liefern. SAFE nutzt genau diese Differenz aus und führt einen selektiven Prozess ein: Weniger wichtige Adapter werden gezielt früh im Trainingsprozess eingefroren. Durch dieses «Einfrieren» bleibt ihr Zustand unverändert, wodurch der Bedarf an Rechenressourcen und Speicherplatz reduziert wird.
Adapter, die dagegen als besonders wichtig eingestuft werden, bleiben weiterhin trainierbar und können so den Großteil der Anpassung übernehmen. Dieses selektive Einfrieren bietet mehrere Vorteile. Zum einen reduziert SAFE den Speicherverbrauch signifikant. Laut Ergebnissen aus Experimenten kann der Speicherbedarf teilweise um über 40 Prozent gesenkt werden. Geringerer Speicherbedarf bedeutet nicht nur, dass günstigere Hardware verwendet werden kann, sondern auch dass größere Modelle mit begrenztem Equipment trainiert werden können.
Zum anderen führt die reduzierte Anzahl gleichzeitig trainierter Parameter zu geringerer Rechenzeit. Dies verkürzt die Zeitspanne, die benötigt wird, um ein Modell für eine bestimmte Aufgabe anzupassen – ein wichtiger Faktor in der Forschung und Entwicklung sowie im produktiven Einsatz. Darüber hinaus zeigt SAFE eine interessante Nebenwirkung auf den Lernprozess selbst. Durch das Einfrieren von Teilen der Adapter entsteht eine Art Regularisierung. Das Modell wird dadurch vor Überanpassung geschützt, was in der Fachsprache bedeutet, dass es nicht zu stark auf die Trainingsdaten optimiert wird und dadurch schlechter auf neue, unbekannte Daten generalisiert.
Diese Regularisierung führt zu einer Glättung der Verlustlandschaft, was wiederum dazu beiträgt, dass das Modell stabilere und robustere Lösungen findet. In der Praxis bedeutet dies eine verbesserte Generalisierungsfähigkeit und oft auch eine höhere Gesamtleistung auf verschiedenen Testdatensätzen. Die Umsetzung von SAFE erfolgt iterativ und clever. Während des Feintunings wird die Relevanz oder Wichtigkeit der einzelnen Adaptermodule kontinuierlich bewertet. Modelle und auch praktische Beispiele zeigen, dass eine schrittweise Einfrierung der weniger wichtigen Adapterbereiche möglich ist, ohne dass die Gesamtleistung darunter leidet.
Dieser dynamische Prozess stellt sicher, dass Ressourcen immer dort konzentriert werden, wo sie den größten Mehrwert bieten. Dies unterscheidet SAFE von starren Methoden, die entweder alle Adapter gleichzeitig trainieren oder alle einfrieren und somit weniger flexibel und effizient sind. Ein weiterer Aspekt, der SAFE besonders attraktiv macht, ist die universelle Anwendbarkeit auf verschiedene Arten von Sprachmodellen. Da Adapter allgemein als modulare Erweiterungen konzipiert sind, kann die selektive Einfrierungsstrategie bei Modellen unterschiedlicher Größe und Architektur problemlos implementiert werden. Ob BERT-ähnliche Modelle für Klassifizierungsaufgaben, GPT-ähnliche Modelle für generative Anwendungen oder auf spezielle Domänen zugeschnittene Sprachmodelle – die Prinzipien von SAFE lassen sich vielfältig nutzen.
In der Praxis hat diese Methode das Potenzial, die Kosten für das Feintuning großer Sprachmodelle erheblich zu senken. Gerade für Unternehmen und Forschungseinrichtungen mit begrenzten Ressourcen ist dies ein wichtiger Faktor. Die Möglichkeit, durch selektives Einfrieren von Adaptermodulen Trainingszeiten zu verringern und gleichzeitig den Speicherbedarf zu reduzieren, eröffnet neue Chancen, um maßgeschneiderte KI-Anwendungen effizienter und nachhaltiger zu realisieren. Ein weiterer Vorteil von SAFE liegt in der verbesserten Stabilität des Trainingsprozesses. Indem unnötige Parameterupdates durch das Einfrieren eingeschränkt werden, verbleibt das Modell in einer konvergenteren und glatteren Optimierungsebene.
Dies erleichtert die Feinabstimmung vor allem bei sehr großen Modellen, die sonst anfällig für instabile Lernverläufe oder Überanpassungen sein können. Trainer und Entwickler profitieren so von einer verlässlicheren und vorhersehbareren Performanceentwicklung. Darüber hinaus fördert die SAFE-Methode den bewussteren Umgang mit Modellkapazität. Oftmals wird bei modernen Sprachmodellen einfach versucht, alle Parameter zu nutzen, anstatt gezielt nur die wirklich wichtigen Teile zu trainieren. SAFE zeigt, dass gezielte Selektion nicht nur die Effizienz erhöht, sondern auch die Ergebnisse verbessert.
Das gibt wertvolle Impulse für weitere Forschung im Bereich ressourceneffizientes maschinelles Lernen und nachhaltige KI-Entwicklung. Nicht zuletzt spielt SAFE auch eine Rolle im Kontext von grüner KI. Die Reduktion notwendiger Rechenressourcen und die Verkürzung der Trainingszeit helfen dabei, den Energieverbrauch beim Training großer Modelle deutlich zu verringern. Dies ist angesichts steigender Umweltbedenken bezüglich des CO2-Fußabdrucks von KI-Systemen besonders relevant. Eine adaptive, selektive Anpassung von Modellen mittels SAFE entspricht somit nicht nur wirtschaftlichen, sondern auch ökologischen Interessen.
Die Zukunft des Feintunings von Sprachmodellen könnte mit Methoden wie Selective Adapter Freezing deutlich nachhaltiger, zugänglicher und performanter gestaltet werden. Forschungsarbeiten, die diese Neuentwicklung beschreiben, zeigen bereits beeindruckende Ergebnisse hinsichtlich der Reduktion von Speicher-, Rechen- und Zeitaufwand verbunden mit stabileren und robusteren Modellen. In der Praxis könnten bald zahlreiche Anwendungen von automatischer Textgenerierung über maschinelle Übersetzung bis hin zu spezielleren Nischenanwendungen von den Vorteilen dieses Ansatzes profitieren. Abschließend lässt sich festhalten, dass Selective Adapter Freezing einen wichtigen Schritt Richtung ressourceneffizientes und leistungsstarkes Feintuning großer Sprachmodelle darstellt. Indem nur die bedeutenden Adapter trainiert und weniger relevante frühzeitig eingefroren werden, entsteht ein ausgeglichener Kompromiss aus Sparsamkeit und präziser Anpassung.
Maschinelles Lernen und KI werden so einem breiteren Nutzerkreis zugänglich gemacht, der nicht über Hochleistungsrechner verfügt, und gleichzeitig leistet SAFE einen Beitrag zu nachhaltigerem Unternehmertum und verantwortungsvoller KI-Forschung. Wer sich mit der Optimierung moderner Sprachmodelle beschäftigt, sollte diese vielversprechende Methodik unbedingt im Blick behalten.