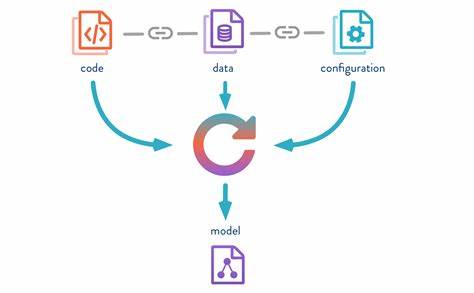
In der heutigen datengetriebenen Welt stehen Unternehmen vor der Herausforderung, riesige Datenmengen effektiv zu verwalten, zu analysieren und zu sichern. Während in der Softwareentwicklung Versionskontrollsysteme wie Git längst Standard sind, hinkt die Datenwelt in puncto Versionierung stark hinterher. Genau hier kommt Data Version Control (DVC) ins Spiel – ein Konzept und eine Sammlung von Werkzeugen, die es ermöglichen, Daten mit derselben Präzision und Nachvollziehbarkeit zu verwalten wie Quellcode. Doch was genau versteht man unter Data Version Control, warum ist sie so wichtig und wie funktioniert sie? Versionierung ist das Rückgrat jeder produktiven und kollaborativen Softwareentwicklung. Entwickler können mithilfe von Git Änderungen an ihrem Code nachvollziehen, parallel experimentieren und auf frühere Versionen zurückgreifen, wenn Fehler auftauchen.
Im Datenbereich gestaltet sich die Lage jedoch komplexer. Daten werden kontinuierlich neu generiert, stehen in vielfältigen Formaten zur Verfügung und ändern sich dynamisch. Verschiedene Mitarbeitende oder Teams arbeiten oft mit unterschiedlichen Datensätzen oder Versionen desselben Datensatzes, was zu Inkonsistenzen, Fehlern und einem Mangel an Datenintegrität führen kann. Data Version Control ist genau der Mechanismus, der diese Herausforderungen adressiert. Es handelt sich um ein System, das speziell darauf ausgelegt ist, den Überblick über Veränderungen in Datensätzen zu behalten.
Dabei wird jede Änderung protokolliert, sodass jederzeit ersichtlich ist, was wann verändert wurde und von wem. Darüber hinaus ermöglicht DVC ein einfaches Zurückrollen auf frühere Versionen, was die Fehlerbehebung deutlich vereinfacht. Für Data Scientists und Dateningenieure bedeutet das eine enorme Arbeitserleichterung und eine erhöhte Sicherheit bei Analysen und Modelltrainings. Wie funktioniert ein Data Version Control System genau? Die Grundlage bildet das Speichern aufeinanderfolgender Versionen von Datenobjekten. Anders als bei einfachen Backups wird hier ein Audit-Trail geführt, der nicht nur eine Kopie der Daten speichert, sondern auch die Metadaten, die die Veränderungen beschreiben.
Somit lassen sich selbst einzelne Datenzeilen oder Attribute in relationalen Datenbanken versionieren. Im Falle von Problemen kann man gezielt auf einen früheren Zustand zurückgreifen, ohne den gesamten Datensatz verlieren zu müssen oder komplizierte Wiederherstellungsprozesse durchlaufen zu müssen. Die Vorteile liegen auf der Hand: Versionierung erhöht die Transparenz und fördert das Vertrauen in die Datenqualität. Teams können nachvollziehen, welche Änderungen warum vorgenommen wurden. Gleichzeitig reduziert sich das Risiko, fehlerhafte Daten dauerhaft zu verwenden.
Gerade in Machine-Learning-Projekten, wo Trainingsdaten und Modellversionen eng verknüpft sind, wird die Data Version Control zum unverzichtbaren Partner, um Reproduzierbarkeit und Validität zu gewährleisten. Im Markt existieren inzwischen verschiedene leistungsfähige Werkzeuge, die Data Version Control erleichtern und je nach Anwendungsfall unterschiedliche Schwerpunkte setzen. lakeFS ist beispielsweise ein Tool, das als Datenversionierungssystem direkt auf Daten-Lakes aufsetzt. Es nutzt Git-ähnliche Funktionen wie Branching und Merging, um isolierte Datenänderungen zu ermöglichen und diese bei Bedarf in die Hauptentwicklungslinie zu integrieren. Besonders vorteilhaft ist die Kompatibilität mit vielen Cloud-Objektspeichern sowie die Integration in beliebte Datenverarbeitungsframeworks.
Dolt verfolgt einen anderen Ansatz und bietet eine versionierte relationale Datenbank mit Git-ähnlichen Operationen. Basierend auf dem innovativen Prolly-Baum erlaubt es Dolt, Versionskontrolle dort anzuwenden, wo traditionelle relationale Datenbanken im Einsatz sind. Allerdings ist diese Lösung insbesondere für unstrukturierte Daten oder sehr große Datenmengen weniger geeignet. Git LFS stellt eine Erweiterung zu Git dar und wurde ursprünglich für große Dateien in der Spieleentwicklung entwickelt. Es ermöglicht die Verwaltung großer Datenmengen, indem Dateien außerhalb des Hauptrepositories abgelegt und lediglich deren Metadaten versioniert werden.
So lässt sich der Code sauber halten, während große Daten wie Modelle oder Assets versioniert werden können. Dennoch passt Git LFS nicht optimal, wenn Daten und Code strikt getrennt bleiben sollen oder besonders große Datenmengen anfallen. Das Open-Source-Tool DVC verbindet die Vorteile eines verteilten Git-Systems mit Remote-Speichern für Daten. Indem es Metadaten-Dateien nutzt, die in Git verwaltet werden, können Teams große Datendateien sowie Machine-Learning-Modelle effizient versionieren, ohne deren Volumen direkt in das Repository zu laden. Obwohl DVC sich gut für Machine-Learning-Projekte eignet, stößt es bei relationalen Datenbankanwendungen sowie bei extrem großen Datenbeständen an seine Grenzen.
Nessie als weiteres Projekt orientiert sich an modernen Softwareentwicklungsmethoden und legt besonderen Wert auf Konsistenz und CI/CD-getriebene Prozesse in der Datenverwaltung. Nutzer können virtuelle Klone von Daten erstellen, Änderungen isoliert durchführen und diese erst dann in die Hauptdaten integrieren, wenn sie freigegeben sind. Das minimiert Risiken und unterstützt eine verlässliche Datenbasis. Die Wahl des Tools hängt stark von den spezifischen Anforderungen ab: Beinhaltet das Projekt hauptsächlich relationale Daten, liegt der Fokus auf großen Datenmengen oder sind vor allem Machine-Learning-Integrationen gefragt? Für Data Engineers und in modernen DataOps-Teams ist jedoch eines klar: Ohne Versionierung verliert man schnell den Überblick, was gravierende Folgen für die Datenqualität und letztlich auch für Geschäftsentscheidungen haben kann. Fazit: Data Version Control ist längst kein Nischenthema mehr, sondern ein entscheidender Faktor für professionelle Datenarbeit im 21.
Jahrhundert. Sie ermöglicht Transparenz, Nachvollziehbarkeit und Fehlerabsicherung in einer Welt ständig wachsender und sich wandelnder Datenbestände. Mit den passenden Tools lassen sich Workflows signifikant verbessern und ein echtes Single Source of Truth etablieren – ein unschätzbarer Vorteil in Zeiten von Big Data und KI-getriebenen Anwendungen. Der Trend geht klar dahin, Datenversionierung zum festen Bestandteil der Data Governance und des Data Engineering zu machen und damit nachhaltige Qualität und Vertrauen in alle datenbasierten Prozesse sicherzustellen.