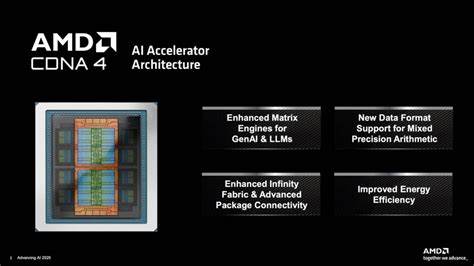
Im Juni 2025 hat AMD mit dem Instinct MI350 und der CDNA 4 Architektur einen bedeutenden Schritt in der Evolution von KI-Beschleunigern und High-Performance-Computing (HPC) gemacht. Begleitet von der Veröffentlichung des aktualisierten ROCm 7 Software-Stacks präsentiert AMD eine Lösung, die den Fokus klar auf KI-Optimierung und Effizienz legt. Die neuen Hardware- und Softwarekomponenten setzen Maßstäbe bei Leistung, Skalierbarkeit und Entwicklerfreundlichkeit und adressieren die steigenden Anforderungen moderner KI-Anwendungen und großer Rechenzentren. Das Herzstück dieser Entwicklung ist die Verwendung des OAM UBB (Universal Baseboard) Standards als Formfaktor für die AMD Instinct MI350 Plattformen. Diese Grundlage ermöglicht die Integration von acht GPUs pro Modul, wobei AMD sowohl luftgekühlte (MI350X) als auch flüssigkeitsgekühlte (MI355X) Varianten anbietet.
Besonders hervorzuheben ist die flüssigkeitsgekühlte Ausführung, die mit einer Leistung von bis zu 1,4 kW pro Modul eine beeindruckende Skalierbarkeit für große Serverumgebungen gewährleistet. Mit bis zu 128 MI355X GPUs – verteilt auf sechzehn 8-GPU-Trays – lassen sich enorme Rechenleistungen in einem Rechenzentrum realisieren, was die Anforderungen moderner KI-Workloads mehr als erfüllt. Im Vergleich zu Konkurrenzsystemen, beispielsweise dem NVIDIA GB200 NVL72 mit seinen 72 GPUs pro Rack, bietet AMD eine bisher unerreichte Skalierbarkeit und Dichte, die für große KI-Projekte, wie Training von maschinellen Lernmodellen oder Verarbeitung von großen Sprachmodellen (LLMs), essenziell ist. Die Herausforderung, solch große Systeme in bestehende Rechenzentrumsumgebungen zu integrieren, bleibt natürlich bestehen, da mit bis zu 52 U an Rack-Kapazität umfangreiche infrastrukturelle Anpassungen nötig werden. Dennoch demonstriert AMD dadurch eine klare Ambition, in den High-End-Markt der KI-Beschleuniger einzutreten und dort mitzuspielen.
Architektonisch steht bei CDNA 4 eine fundamentale Verschiebung gegenüber früheren Generationen im Vordergrund. Während die MI300 Serie noch stark auf HPC-Anwendungen mit Fokus auf FP64 (doppelgenaue Gleitkommaoperationen) ausgelegt war, rückt bei CDNA 4 ganz klar die KI-optimierte Verarbeitung, besonders im Bereich der niedrigpräzisen Datentypen, in den Mittelpunkt. Dies spiegelt sich auch in der Neugestaltung der Compute Units innerhalb des Chips wider. Der neue Compute Die, genannt XCD, wird im fortschrittlichen 3-nm-N3P Prozess gefertigt, was höhere Energieeffizienz und Leistungsdichte erlaubt. Gleichzeitig ist die Anzahl der Compute Units pro Modul mit 256 zwar etwas geringer als bei einigen Vorgängern, doch die Leistungsfähigkeit pro Einheit wurde durch optimierte Designs und erhöhte Kapazitäten signifikant gesteigert.
Ein weiterer innovativer Aspekt der MI350 ist die Modifikation beim Einsatz der I/O Die (IOD). Wo zuvor vier IOD verbaut wurden, setzt AMD beim MI350 nur auf zwei, welche durch ihre erweiterte Zuständigkeit für den Speicher- und Compute-Topologiebereich eine verbesserte Datenverteilung möglich machen. Dadurch verringert sich die interne Datenlatenz und die Infinity Fabric, die das schnelle Verbinden der einzelnen Komponenten gewährleistet, profitiert von einem effizienteren Layout. Die Integration des Infinity Cache trägt zusätzlich dazu bei, dass Daten näher an den Compute Units gehalten werden, was die Bandbreite effektiv erhöht und Flaschenhälse bei datenintensiven KI-Operationen minimiert. Die Speicherkapazität und -bandbreite sind für KI-Anwendungen von entscheidender Bedeutung und AMD hat genau hier bei der CDNA 4 Architektur signifikante Verbesserungen platziert.
Durch die Erhöhung der verfügbaren Speichermengen auf dem Beschleuniger selbst und der beschleunigten Datenübertragung zwischen Speicher und Compute Units können auch äußerst komplexe Modelle deutlich schneller trainiert und inferiert werden. Gerade bei großen Modellen mit Milliarden von Parametern, etwa in der Verarbeitung natürlicher Sprache, ist dieses Plus an nahendem Hochleistungsspeicher ein entscheidender Wettbewerbsvorteil. Ein zentrales technisches Highlight ist die Einführung neuer Datenformate zur Beschleunigung der KI-Berechnungen. Während FP64 bewusst zugunsten optimierter Niederpräzisionsformate zurückgestuft wurde, setzt AMD bei CDNA 4 verstärkt auf FP4 und FP6 Datentypen. Das besondere Augenmerk gilt dem FP6 Format, das als hochperformante Weiterentwicklung im Vergleich zu FP4 und als Alternative zu FP8 gilt.
Anstatt FP6 auf die FP8-Einheiten zu virtualisieren, hat AMD eine dedizierte FP6-Pipeline integriert, welche mit höherer Transistor-Effizienz und Leistungsfähigkeit eine bessere Unterstützung für moderne KI-Modelle bietet, die von niedrigerer Präzision profitieren, ohne große Einbußen in der Genauigkeit zu erleiden. Die Bedeutung der Software-Ebene sollte bei all den Hardware-Highlights nicht unterschätzt werden. ROCm 7, der neueste Software-Stack von AMD für HPC und KI-Beschleuniger, unterstützt den MI350 von Grund auf und soll langfristig die Entwicklererfahrung optimieren. Ziel ist es, die Installation und Nutzung von ROCm so einfach zu gestalten, dass sie sogar über eine Standard-Python-Paketinstallation wie pip realisiert werden kann. Dies erleichtert Anwendern aus Forschung, Entwicklung und Produktion den schnellen Einstieg und die Integration in bestehende KI-Workflows.
Darüber hinaus erweitert AMD den Einsatzbereich von ROCm über klassische Server hinaus auf Notebooks und Workstations. Noch im Laufe des Jahres 2025 ist geplant, ROCm mit umfassendem Support für beliebte Linux-Distributionen wie Red Hat EPEL, Ubuntu, OpenSUSE und Fedora sowie nativ unter Windows, ganz ohne den Umweg über WSL (Windows Subsystem for Linux), auszuliefern. Diese Strategie erleichtert Entwicklern und AI-Experimentatoren die Nutzung von AMD-Beschleunigern auch in flexiblen, mobilen Umgebungen, etwa mithilfe von AMD Ryzen AI MAX+ Systemen. AMD positioniert mit dem MI350 und CDNA 4 Architektur einen klaren Fokus auf die Bedürfnisse moderner KI-Anwendungen von Trainingsprozessen großer Sprachmodelle über Computer Vision bis hin zur datenintensiven wissenschaftlichen Berechnung. Die Neuerungen im Bereich Speicher, Compute Units und neuen Datenformaten sind speziell darauf ausgelegt, sowohl das Datenmanagement effizienter zu gestalten als auch die Rechenleistung pro Watt zu optimieren.
Das Zusammenspiel von Hardware und Software bei AMD zeigt auch die strategische Ausrichtung des Unternehmens: Neben der Leistung steht die Entwicklercommunity im Fokus. Die neue Devise „Developers, Developers, Developers“ unterstreicht das Bestreben, eine breite Basis an AI-Entwicklern effektiver an das AMD Ökosystem zu binden. Neben ROCm 7 wird der AI Developer Cloud Service als zentrales Element dieser Strategie angekündigt, wodurch der Zugang zu leistungsstarken AMD-basierten KI-Umgebungen vereinfacht wird. Gegenüber älteren MI300 Modellen wurde die Rechenleistung auf niedrigem Präzisionsniveau deutlich gesteigert, sodass der MI350 den speziellen Anforderungen von Deep Learning besser gerecht wird. FP8 wird zwar weiterhin unterstützt, aber als Software-Emulationsoption, da das Augenmerk immer mehr auf effizientere Formate wie FP6 gelegt wird.
Die neue Architektur ist somit auf Zukunft ausgerichtet und berücksichtigt tatsächliche Nutzungsmuster in aktuellen KI-Workloads. Zusammenfassend stellt der AMD Instinct MI350 mit der CDNA 4 Architektur und ROCm 7 einen wichtigen Meilenstein dar, der AMDs Ambitionen in der KI-Beschleunigung untermauert. Die Kombination aus erhöhter Skalierbarkeit, intelligenter Speicher- und Compute-Verteilung sowie optimierten KI-Datentypen bietet Unternehmen und Forschungseinrichtungen leistungsstarke Werkzeuge, um die Herausforderungen der nächsten Generation künstlicher Intelligenzen zu meistern. Die Integration in diverse Umgebungen von Server über Workstations bis hin zu Notebooks zeigt zudem AMDs Weitblick, die Bedürfnisse von Entwicklern und Endanwendern gleichermaßen zu bedienen. Mit wachsendem KI-Bedarf in verschiedenen Branchen dürfte die neue MI350 Plattform bei der Entwicklung leistungsfähiger KI-Anwendungen eine Schlüsselrolle spielen und AMD helfen, seine Position als innovativer Player im hart umkämpften Beschleunigermarkt weiter zu festigen.
Die ersten praktischen Tests und Reviews deuten darauf hin, dass die Kombination aus CDNA 4 Hardware und ROCm 7 Software insbesondere bei großen Modellen und datenintensiven Workloads eine hervorragende Performance liefert und gleichzeitig effizient mit Energie umgeht. In der schnelllebigen Welt der künstlichen Intelligenz bleibt AMD mit dem MI350 und ROCm 7 ein Unternehmen, das nicht nur mit seinen technischen Neuerungen überzeugt, sondern auch mit einer zukunftsorientierten Philosophie, die Entwickler, Leistung und Integration gleichermaßen in den Mittelpunkt stellt. Die kommenden Jahre werden zeigen, wie diese Technologien die Landschaft der KI-Beschleunigung nachhaltig prägen werden.