In der heutigen digitalen Welt, in der Geschwindigkeit und Effizienz von IT-Systemen entscheidend sind, wird die Betrachtung von Latenzen immer wichtiger. Dabei geht es nicht nur um die durchschnittliche Reaktionszeit, sondern in besonderem Maße um die sogenannte Tail-Latenz. Dieser Begriff beschreibt die hohen Latenzzeiten, die zwar selten auftreten, aber für die Nutzererfahrung und die Systemstabilität von großer Bedeutung sind. Obwohl diese Spitzenwerte oft nur einen kleinen Teil der Anfragen ausmachen, kann ihre Auswirkung auf komplexe Systeme gravierend sein. In modernen Architekturen, etwa bei Microservices und Service-orientierten Architekturen (SoA), besteht eine Benutzerinteraktion häufig aus vielen einzelnen Serviceaufrufen – sowohl parallel als auch in einer Kette abgearbeitet.
Dadurch wird eine seltene hohe Latenz eines einzelnen Dienstes oft zu einem großen Problem für den gesamten Ablauf, weil sie in der Summe oder als Engpass wirkt. Tail-Latenz ist häufig ein Phänomen, das auf verschiedenste Ursachen zurückzuführen ist. Dazu zählen unter anderem Ressourcenengpässe, Contentions, Garbage-Collection-Prozesse in der Laufzeitumgebung, Paketverluste im Netzwerk oder auch Hintergrundaktivitäten des Betriebssystems. Diese Ursachen haben gemeinsam, dass sie zwar selten auftreten, jedoch zu Verzögerungen führen, die um ein Vielfaches über dem normalen Durchschnitt liegen können. Wenn man sich lediglich den Durchschnittswert oder die Median-Latenz betrachtet, bleiben diese seltenen hohen Latenzspitzen oft unentdeckt oder werden unterschätzt.
Die Bedeutung der Tail-Latenz wird besonders deutlich, wenn man sich den Aufbau moderner Anwendungen vor Augen führt. Frontend-Anwendungen – sei es eine Webseite, eine mobile App oder ein anderer Client – kommunizieren meist nicht nur mit einem monolithischen Server, sondern mit vielen Backend-Diensten, die verantwortlich für unterschiedliche Funktionalitäten sind. Im Rahmen des sogenannten Parallel-Fan-Out ruft ein Frontend gleichzeitig eine Vielzahl von Backend-Diensten auf und wartet darauf, dass alle ihre Antworten liefern. Bei solchen parallelen Aufrufen bestimmt die langsamste Antwort die gesamte Reaktionszeit. Selbst wenn neun von zehn Anfragen schnell bearbeitet werden, kann eine einzige langsame Antwort den gesamten Ablauf verzögern und die Nutzererfahrung negativ beeinflussen.
Ein einfaches hypothetisches Beispiel verdeutlicht das Problem. Angenommen, jeder Dienst antwortet zu 99 Prozent der Zeit mit etwa 10 Millisekunden, in einem Prozent der Fälle dauert es aber 100 Millisekunden. Fällt die Anzahl der parallel aufgerufenen Dienste auf zehn, dann steigt die Wahrscheinlichkeit deutlich, dass eine Anfrage länger als erwartet dauert. Die seltene lange Verzögerung eines einzelnen Dienstes wird durch die Parallelität verstärkt und aus einem seltenen Ereignis wird beinahe eine Regelmäßigkeit. Neben parallelen Aufrufen gibt es auch sogenannte serielle Ketten, in denen ein Dienst einen anderen aufruft, dieser wiederum einen dritten, und so weiter.
Bei solchen Ketten summieren sich die Latenzen. Wenn ein Teil der Kette gelegentlich verzögert reagiert, erhöht sich durch die Addition der Einzellatenzen das Risiko, dass die Gesamtlatenz deutlich aus dem Rahmen fällt. Durch die Zentralen Grenzwertsatz-Theorie nähert sich die Gesamtverteilung mit wachsender Länge der Kette zwar einem Normalverteilungsmuster an, doch die Varianz der Verteilung wird durch die seltenen langen Latenzen enorm erhöht. Das bedeutet konkret, dass die Wahrscheinlichkeit für beobachtbar lange Verzögerungen im System steigt – auch wenn der Großteil der Einzellatenzen im kurzen Bereich bleibt. Ein weiterer Aspekt ist die Auswahl der Metriken zur Überwachung und Optimierung der Systemperformance.
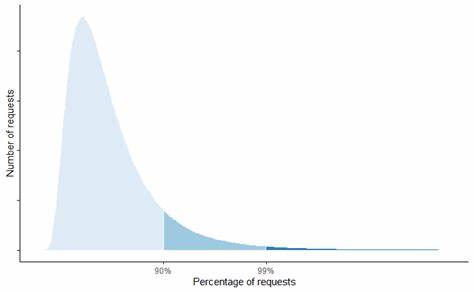
Üblicherweise wird der Mittelwert oder die Median-Latenz betrachtet, doch diese geben den tail-lastigen Charakter der Latenzverteilung nicht ausreichend wieder. Statistiken wie getrimmte oder winsorisierte Mittelwerte, die Außenseiter und extreme Werte ausschließen, können zwar eine stabilere Messgröße liefern, maskieren dabei jedoch oft die kritischen Tail-Werte, die über die Nutzererfahrung entscheiden können. Daher ist es ratsam, nicht nur auf Durchschnittswerte zu setzen, sondern explizit hohe Perzentile wie den 95., 99. oder gar 99,9.
Perzentil zu betrachten. Nur so kann man die seltenen, aber wichtigen Verzögerungen im Blick behalten. Zusätzlich sollte die End-to-End-Latenz aus Nutzersicht überwacht werden. In Systemen mit komplexen Abhängigkeiten und vielen Service-Aufrufen kann die einzelne Dienstlatenz eines Teilsystems nicht ausreichend darüber Auskunft geben, wie das Gesamterlebnis für den Benutzer aussieht. Durch die Messung an der Nutzer-Schnittstelle oder über repräsentative Anwendungsfälle lassen sich so realistischere Aussagen über die tatsächliche Performance treffen.
Die Herausforderungen durch Tail-Latenzen gewinnen mit zunehmender Verbreitung von serverlosen Architekturen und Microservices weiter an Bedeutung. Während klassische monolithische Systeme häufig leichter zu überblicken und zu optimieren sind, bestehen moderne Systeme oft aus einer Vielzahl von voneinander abhängigen Komponenten. Dies erhöht die Komplexität der Performance-Überwachung und macht ein gezieltes Management von Tail-Latenz unerlässlich. Ein ganzheitlicher Umgang mit Tail-Latenzen bedeutet daher, auf mehreren Ebenen anzusetzen: Zunächst müssen Ursachen für gelegentliche Verzögerungen systematisch erkannt und beseitigt werden. Hierbei können Optimierungen in der Ressourcenverwaltung, Verbesserung der Garbage-Collection-Strategien, effiziente Netzwerktechnologien oder ein besseres Contention-Management helfen.
Darüber hinaus ist es wichtig, dass Architekten und Entwickler bereits beim Design von Systemen Rücksicht auf die Auswirkungen von Tail-Latenzen nehmen. Beispielsweise kann die Parallelisierung von Anfragen so gestaltet werden, dass Ausreißer weniger Einfluss auf das Gesamtsystem haben. Alternativ kann das Design auf redundante Anfragen setzen oder zeitliche Puffer einbauen, die die Auswirkungen verzögerter Antworten abfedern. Auch auf die operativen Abläufe hat Tail-Latenz Auswirkungen. Monitoring-Tools müssen so konfiguriert werden, dass sie sowohl Durchschnittswerte als auch hohe Perzentile analysieren.