OpenTelemetry hat sich in der Welt der Softwareentwicklung und des Observability-Frameworks schnell zu einem Branchenstandard entwickelt. Besonders in der Programmiersprache Go erfreut sich OpenTelemetry zunehmender Beliebtheit, denn es ermöglicht Entwicklern, umfassende Telemetriedaten wie Metriken, Logs und verteilte Traces nahtlos in ihre Anwendungen zu integrieren. Doch wie jede Form der Instrumentierung kommt auch OpenTelemetry nicht ohne Kosten. Die Frage, die sich viele Teams stellen, lautet: Wie hoch ist der tatsächliche Overhead, den OpenTelemetry in einer produktiven Go-Anwendung verursacht? Die Antwort auf diese Frage ist entscheidend, um eine ausgewogene Entscheidung zwischen umfassender Observability und der notwendigen Performance zu treffen. Die Messung und das Verständnis dieses Overheads sind daher wichtige Voraussetzungen für den effizienten Einsatz von Observability-Tools.
Eine detaillierte Benchmark-Analyse liefert hierzu wertvolle Erkenntnisse. Im Rahmen einer praxisnahen Untersuchung wurde hierfür ein einfacher Go-basierter HTTP-Server entwickelt, welcher bei jeder eingehenden Anfrage einen Zähler in einer In-Memory-Datenbank namens Valkey erhöht, einer Redis-Variante. Diese minimalistische Anwendung dient als Prototyp, um die Auswirkungen von OpenTelemetry auf diverse Leistungskennzahlen unter kontrollierten Bedingungen zu messen. Der Test verlief in zwei Phasen: Zunächst wurde die Anwendung ohne jegliche Instrumentierung betrieben, um eine reine Baseline hinsichtlich Durchsatz, Latenz und Ressourcenverbrauch zu etablieren. Anschließend wurde die OpenTelemetry SDK für Go aktiviert, um den Einfluss der Telemetrie auf die Performance direkt zu vergleichen.
Das Setup umfasste vier separate Linux-Server, jeweils ausgestattet mit vier virtuellen CPUs und 8 GB Arbeitsspeicher. Diese Verteilung stellte sicher, dass die einzelnen Komponenten Valkey, die Go-Anwendung, der Lastgenerator und das Observability-Tool Coroot auf eigenen Ressourcen liefen. Dies minimierte Störeinflüsse und ermöglichte eine präzise Messung. Der Go-Server, in einem Docker-Container mit Host-Netzwerkmodus betrieben, kommunizierte mit dem Valkey-Datenbankserver, um Netzwerk-Latenzen möglichst gering zu halten. Für die Lastgenerierung kam ein speziell entwickeltes Werkzeug namens wrk2 zum Einsatz, mit dem ein genau konfiguriertes Request-Volumen von 10.
000 Anfragen pro Sekunde über 20 Minuten simuliert wurde. Die präzise Steuerung der einzelnen Kenngrößen wie Threads, Verbindungen und Request-Rate ermöglichte eine zuverlässige Belastungssimulation. Die gewählten Parameter spiegeln realistische Szenarien in hochfrequenten Produktionsumgebungen wider und sind somit repräsentativ für den praktischen Einsatz. Das Benchmarking ohne aktivierte OpenTelemetry-Integration zeigte beeindruckende Ergebnisse: Der Server bewältigte ohne Probleme die 10.000 Requests pro Sekunde mit einer Mehrheit der Antworten unter 5 Millisekunden.
Die 95. und 99. Perzentile der Latenz lagen bei 5 beziehungsweise 10 Millisekunden, gelegentliche Ausreißer stiegen auf bis zu 20 Millisekunden. Die CPU-Auslastung hielt sich bei etwa zwei virtuellen CPUs und der Speicherbedarf war mit rund 10 Megabyte minimal. Dieses Setup zeigte ein sehr effizientes System mit geringem Ressourcenverbrauch.
Die Aktivierung von OpenTelemetry führte zu spürbaren Änderungen in den Betriebskennzahlen. Die Speicherbelegung stieg auf 15 bis 18 Megabyte, was vor allem durch den Overhead des SDK und die Hintergrundprozesse für das Handling und Exportieren von Telemetriedaten verursacht wurde. Die Erhöhung mag aus technologischer Sicht moderat erscheinen, doch kann sich bei sehr großen oder speicherintensiven Anwendungen bemerkbar machen. Besonders auffällig war die Steigerung der CPU-Last auf etwa 2,7 Kerne, was einer Zunahme von etwa 35 Prozent entspricht. Dieser Zuwachs erklärt sich durch die intensive Verarbeitung und Übertragung von Spans, die der OpenTelemetry-Trace-Pipeline innewohnen.
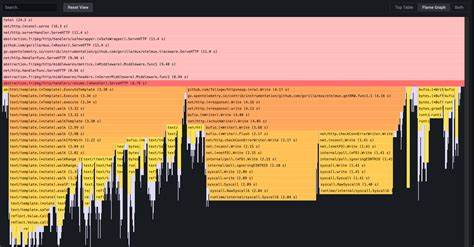
Eine tiefgehende Profilanalyse mittels eBPF-basiertem CPU-Profiler, bereitgestellt durch Coroot, verdeutlicht die Details der CPU-Zuteilung: Rund 10 Prozent der Gesamtprozessorzeit entfielen auf die Paketierung und den Export der Spans durch die Batch-Span-Processor-Komponente. Auch die Redis-Interaktionen wurden durch Trace-Hooks stärker belastet, was zu einem zusätzlichen CPU-Overhead von etwa sieben Prozent bei den Datenbankzugriffen führte. Außerdem konnten die Mehrkosten der HTTP-Handler und Middleware klar dem instrumentierten Code zugeordnet werden. Daraus wird deutlich, dass der größte Teil der Mehrbelastung nicht durch die eigentliche Business-Logik entsteht, sondern durch die Telemetrieinfrastruktur. Die Latenz verschob sich durch OpenTelemetry geringfügig nach oben.
Die Anzahl der Anfragen mit Antwortzeiten zwischen 5 und 10 Millisekunden stieg an, und das 99. Perzentil erhöhte sich von 10 auf etwa 15 Millisekunden. Trotz dieser Steigerung blieb der Gesamtdurchsatz stabil bei 10.000 Anfragen pro Sekunde. Wichtigerweise traten dabei keine Fehler oder Timeouts auf, sodass die Anwendungsqualität insgesamt erhalten blieb.
Diese Ergebnisse verdeutlichen, dass der Overhead zwar messbar ist, jedoch in den meisten Einsatzszenarien tolerierbar bleibt. Ein weiterer Faktor, der häufig vernachlässigt wird, ist der Anstieg des Netzwerkverkehrs durch die Telemetrie. Im Test erhöhte sich das ausgehende Datenvolumen auf rund vier Megabyte pro Sekunde, was umgerechnet 32 Megabit im Sekundentakt entspricht. In Umgebungen mit begrenzter Netzwerkkapazität oder strengen Datenübertragungsrichtlinien können diese Werte langfristig eine Herausforderung darstellen, insbesondere bei hohem Anfragevolumen und aktivem Full-Tracing. Alternativ zu SDK-basierter Instrumentierung gewinnt mittlerweile eBPF-basierte Observability an Bedeutung.
Diese Methode erlaubt es, Telemetriedaten auf Kernel-Ebene zu sammeln, ohne den Anwendungscode zu ändern oder dedizierte SDKs zu integrieren. Der Vorteil liegt in deutlich geringerem Overhead, da die Daten weniger invasiv aggregiert und ausgewertet werden. Agents wie der von Coroot nutzen eBPF-Techniken, um sowohl Metriken als auch Traces direkt von der Systemebene aus zu erfassen. Im praxisnahen Benchmark zeigte sich, dass Coroots eBPF-basierter Agent selbst unter dauerhafter hoher Last nur geringfügige CPU-Ressourcen beansprucht, regelmäßig unter 0,3 Kern-Auslastung auf den produktiv genutzten Nodes. Dies stellt eine sehr effiziente Lösung für produktive Umgebungen dar, bei der dennoch ein hohes Maß an Systemtransparenz gewährleistet ist.
Dabei empfehlen Experten, in besonders stark frequentierten Szenarien das Tracing via eBPF auszuschalten und sich auf Metriken zu konzentrieren. Dies minimiert den Ressourcenverbrauch zusätzlich und optimiert die Skalierbarkeit. Die Entscheidung zwischen SDK-basierter OpenTelemetry-Integration und eBPF-gestützter Instrumentierung hängt stark von den individuellen Anforderungen und Prioritäten ab. SDKs liefern eine umfassende und detaillierte Tracing-Information, die Fehlerdiagnose und Performance-Analyse enorm erleichtern. Gleichzeitig verursachen sie messbare Mehrlast auf den Ressourcen und erhöhen den Netzwerktraffic spürbar.
Für Teams, denen höchste Genauigkeit und Detailtiefe in der Observability wichtig sind, ist die SDK-Variante damit oftmals die beste Wahl. Für Umgebungen mit hohen Anforderungen an Performance und niedrigen Overhead, etwa in Adtech oder bei hochfrequenten Systemen, kann eBPF-basierte Metrik-Sammlung die bessere Alternative sein. Sie bietet eine gute Übersicht über Systemgesundheit und Interaktionen zwischen Diensten, ohne jedem einzelnen Request nachzuforschen. Das spart Ressourcen und verringert gleichzeitig die Komplexität der Betriebsumgebung. Insgesamt zeigt die Analyse, dass Observability zwar mit Kosten verbunden ist, diese Kosten jedoch kontrollierbar und oft sinnvoll investiert sind.



![The "standard" car charger is usually overkill [video]](/images/F44E99ED-9D99-4595-9C8F-0CD0F178AA25)