In der heutigen Welt der Softwareentwicklung sind mikroservicebasierte Architekturen und verteilte Systeme allgegenwärtig. Diese Systeme ermöglichen eine hohe Skalierbarkeit und Flexibilität, stellen Entwickler und Betreiber jedoch gleichzeitig vor neue Herausforderungen. Insbesondere das Verständnis der Abläufe über Service-Grenzen hinweg wird immer schwieriger. Klassische Logging-Methoden reichen nicht mehr aus, um komplexe Interaktionen und Fehlerquellen nachvollziehbar zu machen. Hier kommt das sogenannte Distributed Tracing ins Spiel.
Es sorgt für eine durchgängige Nachverfolgbarkeit von Benutzeranfragen und Prozessen über verschiedene Services hinweg und liefert wertvolle Einblicke in Engpässe, Fehler sowie die Service-Abhängigkeiten. Fastrace wird als moderne, performante Alternative für Distributed Tracing in Rust vorgestellt und adressiert typische Schwächen bestehender Lösungen. Das verbreitete Rust-Projekt tokio-rs/tracing gilt seit Längerem als Standardinstrument zur Anwendungstracing in der Rust-Welt. Dennoch bringt diese Lösung diverse Probleme mit sich. Insbesondere fragmentiert es das Ökosystem durch eigene Logging-Makros, wodurch die Kompatibilität mit dem klassischen Rust log-Crate eingeschränkt ist.
Bibliotheksautoren stehen vor der Wahl, entweder kompatibel mit dem breiten Ökosystem zu bleiben, was aber oft ohne Tracing-Funktionalität passiert, oder tokio-rs/tracing zu verwenden, was zu Komplexität bei Konfiguration und Feature-Flags führt. Zudem ist die Kontextpropagation für verteilte Anfragen bei tokio-rs/tracing nicht automatisiert, was in fragmentierten oder chaotischen Trace-Verläufen resultiert, wenn es zum Beispiel bei gRPC-Diensten eingesetzt wird. Legacy-Lösungen erfordern häufig manuelles Extrahieren und Übergeben von Tracing-Kontext, was zeitaufwendig und fehleranfällig ist. Fastrace setzt an genau diesen Problemen an und bietet eine durchdachte, nahtlos integrierbare Alternative. Die Lösung zeichnet sich vor allem durch ihre zero-cost-Abstraktion aus, was bedeutet, dass Tracing-Code bei deaktivierter Funktionalität komplett vom Compiler entfernt wird und somit keinerlei Laufzeitkosten verursacht.
Gerade für Bibliotheken, die oft in Performance-kritischen Pfaden agieren, ist das ein enormer Vorteil. Entwickler können tracingfähige Bibliotheken bereitstellen, ohne ihre Nutzer mit messbarem Overhead zu belasten. Erst wenn die Anwendung selbst das Tracing aktiviert, wird die Instrumentierung wirksam und liefert wertvolle Telemetriedaten. Ein weiterer Pluspunkt von Fastrace ist das kompromisslose Festhalten an Ökosystem-Kompatibilität. Während tokio-rs/tracing in gewisser Hinsicht ein eigenes Logging-Ökosystem erzwingt, integriert sich Fastrace elegant in bestehende Logging-Strukturen, insbesondere mit dem gängigen log-Crate.
Somit bleiben Bibliotheksautoren frei darin, ihre bevorzugte Logging-Lösung zu verwenden, während gleichzeitig Tracing vollumfänglich unterstützt wird. Dadurch wird auch die Wartbarkeit von Software-Projekten deutlich erleichtert, da keine zusätzlichen Brücken oder komplexe Feature-Mechanismen benötigt werden. Darüber hinaus ist die API von Fastrace besonders einfach gehalten und auf die häufigsten Anwendungsfälle optimiert. Das reduziert den Aufwand für Entwickler erheblich, da der Boilerplate-Code minimal bleibt. Mit einer einzigen Annotation können Funktionen vollständig instrumentiert werden, wie das Beispiel #[fastrace::trace] zeigt.
Das erhöht die Akzeptanz bei Teams und ermöglicht eine flächendeckende Instrumentierung von Services. Ein großer Gewinn ist die automatische Kontextpropagation über Service-Grenzen hinweg, die Fastrace durch eine Reihe von Begleit-Crates für populäre Frameworks realisiert. So werden in HTTP-Clients, gRPC-Servern und Client-Anwendungen sowie beim Datenzugriff mit Tools wie Apache OpenDAL Tracing-Kontexte nahtlos injiziert beziehungsweise extrahiert. Für Entwickler bedeutet das: Sie müssen sich nicht mehr um das manuelle Handling von Trace-Informationen kümmern, sondern profitieren direkt von lückenlosen Traces und besserer Fehlerdiagnose. Die Performance von Fastrace ist ein weiterer entscheidender Vorteil.
Sie wurde gezielt für den Einsatz in hochbelasteten, produktiven Umgebungen optimiert. Ein Beispiel ist die Nutzung bei großen Systemen wie ScopeDB, das mit petabytegroßen Observability-Datenmengen arbeitet und dort präzise Tracing-Informationen benötigt, ohne die Echtzeitfähigkeit oder Ressourcenauslastung einzuschränken. Durch den geringen Speicherverbrauch und die schlanke Implementierung eignet sich Fastrace sowohl für umfangreiche Microservice-Cluster als auch für ressourcenbeschränkte Embedded- oder Edge-Umgebungen. Die Kombination von Fastrace mit bewährten Rust-Logging-Tools wie log und logforth stellt eine Komplettlösung für Observability dar. Logforth bringt dabei industrielle Features wie Filtermöglichkeiten und die automatische Anreicherung von Log-Nachrichten mit Trace- und Span-IDs mit.
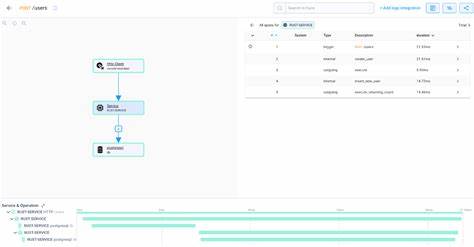
Somit werden Logs konzertiert mit Traces dargestellt, was den Kontext beim Debuggen deutlich erweitert. Anwender können in Log-Management-Systemen später nachvollziehen, welche Log-Einträge zu welchen Trace-Segmenten gehören – ohne die Entwickler müssen unterschiedliche APIs oder Makros lernen. Ein typisches Nutzungsszenario zeigt, wie einfach eine moderne Microservice-Anwendung mit Fastrace ausgestattet werden kann. Im Backend-Handler wird lediglich mit #[fastrace::trace] annotiert, um die automatische Span-Erstellung und -Verwaltung zu aktivieren. Parallel werden klassische Log-Statements via log-Crate genutzt, die dann automatisch mit dem aktiven Trace verknüpft werden.
Im weiteren Verlauf ruft die Anwendung externe Microservices per HTTP mit einer Clientbibliothek an, die automatisch das Trace-Kontext-Headerfeld injiziert. Auf der Serverseite wird der Kontext extrahiert und ein neuer Span als Teil des Gesamttraces gebildet. Diese End-to-End-Verknüpfung garantiert eine präzise Sicht auf die gesamte Anfragenkette im Monitoring-Backend. Die Entwickler von Fastrace stellen mit der optionalen Unterstützung von OpenTelemetry weitere Einstiegsmöglichkeiten bereit. So kann die Tracing-Infrastruktur in eine breite Palette von Observability-Tools eingebunden werden.
Dadurch passen sich Entwickler-Teams flexibel an bereits etablierte Monitoring-Werkzeuge an oder setzen auf Opensource-Lösungen. Abschließend repräsentiert Fastrace einen zukunftsweisenden Schritt im Bereich Distributed Tracing für Rust-Systeme. Die klare Trennung zwischen Bibliotheken und Anwendungen, die einfache API, die automatische Kontextpropagation und die Zero-Overhead-Prämisse leisten einen entscheidenden Beitrag, um mehr Transparenz in verteilte Architekturen zu bringen. Dabei ermöglicht Fastrace eine nahtlose Integration in die bestehende Rust-Ökosystem-Landschaft, ohne Entwickler mit komplexer Konfiguration oder Kompatibilitätsproblemen zu belasten. Für Unternehmen, die auf schnelle Fehlersuche und Performance-Optimierung in großflächigen, mikroservice-orientierten Umgebungen angewiesen sind, bietet Fastrace eine effektive und zukunftssichere Lösung.
Wer auf der Suche nach einer robusten und modernen Distributed Tracing-Technologie in Rust ist, sollte Fastrace definitiv in Betracht ziehen. Die Kombination aus niedrigem Overhead, hoher Performance, einfacher Bedienung und umfassender Kompatibilität macht es besonders attraktiv für professionelle Produktionsumgebungen. Die Vorteile von Fastrace tragen langfristig dazu bei, die Softwarequalität zu verbessern, Ausfallzeiten zu minimieren und Kosten durch präzise Überwachung zu senken. Mit Fastrace wird verteiltes Tracing in Rust so einfach und effizient wie nie zuvor.