Sudoku ist weltweit eines der bekanntesten Logikrätsel, das seit Jahrzehnten große Beliebtheit genießt. Doch über die klassische Variante hinaus haben sich kreative Sudoku-Abwandlungen entwickelt, die nicht nur Hobbyspieler fordern, sondern auch als anspruchsvolle Testfelder für künstliche Intelligenz (KI) dienen. Das Sudoku-Bench Leaderboard steht dabei im Mittelpunkt einer spannenden Forschungsinitiative, die darauf abzielt, die kreativen und reasoning-fähigen Eigenschaften von großen Sprachmodellen und KI-Systemen zu evaluieren. Diese Plattform misst die Leistungsfähigkeit von KI-Modellen anhand speziell entworfener Sudoku-Varianten, die klassische Logik mit ungewöhnlichen Regeln und visuellen Elementen kombinieren. Das Resultat ist eine anspruchsvolle Benchmark, die weit über das herkömmliche Lösen von Sudoku-Puzzles hinausgeht und sowohl innovative Denkstrategien als auch ein umfassendes Verständnis der Rätselmechanismen fordert.
Die Kernidee des Sudoku-Bench liegt darin, Künstliche Intelligenz daran zu messen, ob sie in der Lage ist, auf eine Art und Weise zu denken, die menschliche kreative und adaptive Denkprozesse imitiert. Statt reiner Brute-Force-Algorithmen, die einfach alle möglichen Kombinationen durchprobieren, verlangt Sudoku-Bench von den Modellen sogenanntes Meta-Reasoning, bei dem die KI eigene Problemlösungsstrategien auswählen muss. Sudoku-Varianten beinhalten oft spezielle Einschränkungen, wie etwa Anti-Knight-Regeln oder thermometrische Anordnungen, die das Lösen erschweren und das analytische Vermögen der Modelle auf die Probe stellen. Die auf Sudoku-Bench präsentierten Aufgaben sind daher ein idealer Prüfstein für fortgeschrittene KI-Systeme, da sie Kreativität, Flexibilität und logisches Denken erfordern – Fähigkeiten, die über das reine Ausführen vorprogrammierter Abläufe hinausgehen. Das Leaderboard segmentiert die Bewertung in verschiedene Kategorien, die sich nach der Art der Interaktion zwischen Modell und Benutzer richten.
Bei der Single-Shot-Konfiguration versucht das LLM (Large Language Model), ein komplettes Sudoku in einem einzigen Schritt vollständig und korrekt zu lösen. Diese Herangehensweise stellt eine außerordentliche Herausforderung dar, da hier alle Platzierungen in einem Zug richtig sein müssen, ohne iterative Korrekturen. Die Multi-Step-Konfiguration ermöglicht hingegen eine schrittweise Problemlösung, bei der das Modell in mehreren Runden einzelne Zellen ausfüllt und dabei Rückmeldungen über vorherige Eingaben erhält. Dieses Vorgehen gleicht eher einem Dialog, wie er zwischen Menschen beim gemeinsamen Rätseln entstehen kann, und erlaubt eine tiefere Analyse der Denkprozesse innerhalb des Modells. Die Leistung der Modelle wird hauptsächlich anhand zweier Kennzahlen beurteilt.
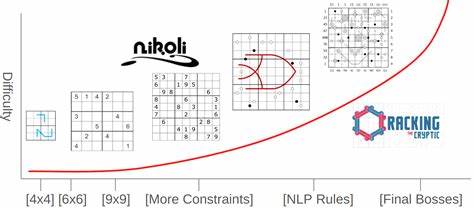
Die Average Solve Rate (ASR) definiert den Anteil der Rätsel, die ein Modell vollständig und korrekt lösen konnte. Dies ist die wichtigste Metrik zur Beurteilung der Gesamtfähigkeit des Systems. Ergänzt wird dies durch die Average Correct Placements (ACP) in Multi-Step-Szenarien, welche angibt, wie viele korrekte Zellen das Modell im Durchschnitt setzen konnte, bevor es einen Fehler machte oder die Interaktion endete. Diese differenziertere Messgröße zeigt auf, wie stabil und präzise das Modell durch komplexe Lösungsprozesse navigieren kann. Das Sudoku-Bench enthält insgesamt 100 variierende Puzzles, die von kleinen 4x4-Gittern bis hin zu klassischen 9x9-Feldern reichen.
Die Vielfalt in den räumlichen Größen und Spielmechaniken sorgt für eine breit angelegte Prüfung der KI-Modelle. Hierbei setzen führende Forschungsteams auf die Plattform, um ihre neuesten Entwicklungen zu testen und ihre Systeme mit Mitbewerbern zu vergleichen. Die aktuell auf dem Leaderboard führenden Modelle stammen größtenteils von Sakana AI, deren Forschung sich auf die Verbesserung von reasoning-basierten Fähigkeiten konzentriert. Jeffrey Seely, Yuki Imajuku, Tianyu Zhao, Edoardo Cetin und Llion Jones sind die federführenden Wissenschaftler hinter dieser Initiative, die bereits im Mai 2025 als technischer Bericht veröffentlicht wurde. Ihr Werk dient mittlerweile als Referenzpunkt für die KI-Forschung im Bereich kreativer Problemlösung und erweitert das Verständnis dafür, wie Maschinen durch innovative Aufgaben menschliches Denken imitieren können.
Die Dashboard-Auswertungen zeigen ein klar definiertes Leistungsgefälle zwischen den verschiedenen Modellen. Bekanntlich treten klassische Sprachmodelle wie GPT-4 oder Claude 3.7 Sonnet zwar mit basalen Fähigkeiten an, erreichen jedoch in vielen der Pivot-Puzzles erheblich geringere Werte bezüglich ASR und ACP. Im Gegensatz dazu haben speziell angepasste Modelle wie O3 Mini High oder Gemini 2.5 Pro bei kleineren 4x4 Sudoku-Varianten bereits hohe Erfolgsraten vorzuweisen, während größere und komplexere 9x9-Rätsel nach wie vor eine große Herausforderung darstellen.
Die Besonderheit bei Sudoku-Bench ist, dass die Bewertung ohne den Einsatz von externen Werkzeugen oder Codeausführung stattfindet. Das ist ein Novum im Bereich der KI-Tests, da sich viele andere Benchmarks auf Kombinationen aus Modell und Programmausführung verlassen, um Lösungen zu validieren. Sudoku-Bench setzt bewusst auf die rohe Denkfähigkeit der KI-Inferenz, um echtes reasoning und kreative Problemlösung zu fördern. Das macht die Herausforderung sowohl für bestehende als auch für zukünftige Modelle einzigartig. Die technische Tiefe der Sudoku-Varianten umfasst zahlreiche innovative Regeln und visuelle Anweisungen.
So gibt es Puzzles mit Anti-Knight-Bestimmungen, die verhindern, dass gleiche Zahlen in einem Springerzug entfernt platziert werden dürfen, oder „Thermometer“-Konstellationen, bei denen die Zahlen auf dem Thermometer von der Glühbirne bis zur Spitze streng aufsteigend sein müssen. Weitere komplexe Regeln wie Kropki-Punkte, die Verhältnisse und Reihenfolgen zweier benachbarter Zellen vorschreiben, oder sogenannte „Renban“-Linien, welche aus zusammenhängenden, nicht wiederholten Ziffern bestehen müssen, sorgen für vielfältige und anspruchsvolle Szenarien. Darüber hinaus tragen spezielle Linienfarben dazu bei, dass verschiedene Regeln gleichzeitig operieren. Beispielsweise kennzeichnen violette Linien Renban-Sektionen, grüne Linien markieren Bedingungen zum Zahlenabstand, und hellgraue Linien zeigen Thermometer an. Zudem veranschaulichen unterschiedliche Symbole wie Kreise, Pfeile und Texteigenschaften auf dem Sudoku-Brett spezielle Zusatzregeln oder Behinderungen.
Diese Kombination aus visuellen und mathematischen Einschränkungen bietet eine Multidimensionalität, die weit über ein herkömmliches Sudoku hinausgeht. Highlight-Puzzles im Benchmark stellen oft Beispiele für besonders komplexe Regelwerke dar. So fordert das „Zeeta-Moth“-Puzzle ganz unterschiedliche Einschränkungen, von Summenregelungen über Increment-Steps entlang Thermometern bis hin zu speziellen Entropielinien, die unterschiedliche Wertebereiche abdecken müssen. Andere Puzzles wie „Dyscalculia“ oder „Matty Didn’t Call You Back Because He Had The Wrogn Number“ liefern Narrative und spielerische Variationen mit absichtlich fehlerhaften Regeln, die das reasoning der Modelle zusätzlich auf die Probe stellen. Diese breite Mischung aus regulären, modifizierten und kreativen Regeln macht Sudoku-Bench nicht nur zu einem Test von diverses Logikkompetenzen, sondern auch zu einem Experimentierfeld für Forscher, die neue Methoden des maschinellen Lernens und des Natursprachverständnisses vereinen wollen.
Beispielsweise werden Multimodale Ansätze untersucht, bei denen visuelle und textuelle Informationen gemeinsam verarbeitet werden, um komplexere Schlussfolgerungen zu generieren. In der KI-Forschung ergibt diese Benchmark wertvolle Einsichten darüber, wie gut heutige Systeme kontextuelle Restriktionen interpretieren, Zwischenlösungen ableiten und Fehlerhandhabung implementieren können. Die Ergebnisse legen nahe, dass trotz beachtlicher Fortschritte in der Sprachverarbeitung insbesondere bei größeren Gittern die Herausforderungen der vollständigen und fehlerfreien Lösung weiterhin beträchtlich sind. Dies inspiriert zu neuen Ansätzen in der Modellarchitektur, Trainingsmethodik und Datenaufbereitung. Auch für Entwickler und Anwender außerhalb der akademischen Welt birgt Sudoku-Bench relevante Erkenntnisse.
KI-Modelle, die auf dieser Benchmark gute Leistung erzielen, haben ein Potenzial, in komplexeren Planungsaufgaben, Entscheidungsfindungen und kreativen Problemlösungen eingesetzt zu werden. Beispielsweise könnte die Fähigkeit zur detailgenauen Iteration im Multi-Step-Modus als Vorlage dienen für Anwendungen in interaktiven Lernumgebungen oder intelligenten Assistenzsystemen. Die offene Natur des Sudoku-Bench-Projektes ermöglicht es zudem der Community, selbst an der Weiterentwicklung der enthaltenen Puzzles und Bewertungssysteme teilzunehmen. Über die bereitgestellten GitHub-Repositorien und zugehörige Dokumentationen können neue Spielsituationen entwickelt, bestehende Algorithmen evaluiert und gemeinschaftlich Innovationen vorangetrieben werden. Diese Partizipation fördert eine Gesamtdynamik, die sowohl Vielfalt als auch Qualität der Benchmarks erheblich verbessert.