Die moderne Datenlandschaft stellt Unternehmen vor immense Herausforderungen, wenn es um die Verarbeitung und Analyse großer Datenmengen geht. Viele setzen weiterhin auf bewährte relationale Datenbanken wie PostgreSQL für ihre transaktionalen Workloads. Allerdings zeigt sich bei analytischen Abfragen an umfangreichen Datenbeständen schnell, dass die traditionelle Zeilenorientierung und das Multi-Version Concurrency Control (MVCC) Konzept von PostgreSQL an ihre Grenzen stoßen. Die Performance leidet häufig, was nicht nur die Analyse verzögert, sondern auch die Stabilität der produktiven Umgebung gefährden kann. Hier setzt die Kombination mit DuckDB und MotherDuck an und bietet eine ideale Lösung, um das Beste aus beiden Welten zu vereinen und so analytische Anforderungen auf ein neues Level zu heben.
PostgreSQL ist wegen seiner Stabilität und seinen vielseitigen Einsatzmöglichkeiten weit verbreitet. Seine Zeilenorientierung und MVCC sind hervorragend für transaktionale Operationen geeignet, weil sie konsistente und isolierte Datenzugriffe gewährleisten. Sobald jedoch große Datenmengen durchlaufen werden müssen, etwa bei komplexen Reporting- oder Analyse-Szenarien, zeigen sich die Schwächen im System. Die fehlende Spaltenorientierung erschwert effiziente Scans, und letztlich leidet die Geschwindigkeit signifikant. DuckDB hingegen ist eine spaltenorientierte Datenbank, die speziell für analytische Zwecke entwickelt wurde.
Sie nutzt Vektorprozessoren und moderne CPU-Architekturen effizient aus, um hochkomplexe Abfragen in kurzer Zeit zu bewältigen. Mit ihrem Design bringt DuckDB analytischen Workloads eine ganz neue Dynamik. MotherDuck erweitert diese Fähigkeiten, indem es DuckDB-Instanzen in einer serverlosen Cloud-Umgebung bereitstellt, die sich durch hohe Skalierbarkeit und vereinfachte Verwaltung auszeichnet. Die Kombination mit PostgreSQL eröffnet somit zahlreiche Möglichkeiten, die beiden Systeme sehr eng zu verzahnen und gleichzeitig eine klare Trennung in den jeweiligen Domänen zu erhalten. Die wichtigste Frage für Unternehmen lautet also: Wie kann man die Vorteile von PostgreSQL und DuckDB optimal kombinieren? Es existieren im Wesentlichen drei Wege, die sich unterschiedlich in Setup-Komplexität, Performanz und Aufwand unterscheiden.
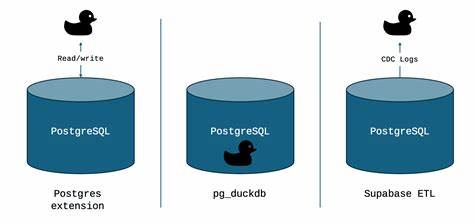
Die erste Möglichkeit ist die Nutzung der DuckDB Postgres Extension. Diese ermöglicht es, DuckDB als Client-Anwendung zu nutzen, die direkt über das PostgreSQL-Protokoll eine Verbindung zur Datenbank herstellt und dort die benötigten Daten für analytische Abfragen „zieht“. Dabei läuft DuckDB auf einem separaten System – sei es lokal, on-premise oder in der Cloud – und führt die rechenintensiven Abfragen dort aus. Diese Variante zeichnet sich durch ihre Einfachheit aus: Es sind keinerlei Änderungen am PostgreSQL-Server selbst notwendig, und die Verbindung erfolgt über Standardverbindungen mit Authentifizierung. Die größte Stärke liegt darin, dass Produktionsdatenbanken von der Belastung durch schwere Analysen entlastet bleiben.
Auch in Managed Services wie AWS RDS oder Google Cloud SQL ist dieser Zugang problemlos möglich. Allerdings kann es bei sehr großen Datenmengen zu einem Flaschenhals durch die Netzwerkübertragung kommen, da die Daten über die Verbindung ausgelesen werden müssen. Darüber hinaus ist die Möglichkeit von Pushdowns, also eine Filterung oder Projektion von Daten möglichst nahe an der Quelle, noch eingeschränkt. Das bedeutet, dass in manchen Fällen mehr Daten übertragen werden als eigentlich nötig, was die Performance beeinträchtigen kann. Dennoch eignet sich dieser Ansatz hervorragend für explorative Analysen, kleinere Tabellen oder Szenarien, in denen keine Installation zusätzlicher Erweiterungen auf dem PostgreSQL-Server möglich ist.
Eine zweite und technisch anspruchsvollere Option ist die Erweiterung pg_duckdb, die DuckDB direkt in den PostgreSQL-Server einbettet. Hierbei wird auf dem Server selbst ein DuckDB-Interpreter installiert, der analytische Abfragen innerhalb des laufenden PostgreSQL-Prozesses ausführen kann. Dies ermöglicht eine deutliche Beschleunigung analytischer Abfragen direkt am Datenspeicher. Dank der Integration können auch externe, spaltenorientierte Datenformate wie Parquet oder Iceberg nahtlos im Abfrageprozess berücksichtigt werden. Für maximale Stabilität wird dringend empfohlen, diese Erweiterung auf dedizierten Lesereplikaten statt auf den produktiven Primärsystemen einzusetzen.
Aufgrund der Ressourcenintensität von DuckDB und seiner aggressiven Nutzung von CPU und RAM kann ein einsatz auf dem Primärserver dessen Leistungsfähigkeit erheblich beeinträchtigen. Die Performancevorteile sind beeindruckend: Tests zeigen teilweise bis zu 1500-fache Beschleunigungen bei typischen Analyseabfragen gegenüber einer reinen PostgreSQL-Verarbeitung. Ein weiterer Pluspunkt ist die Fähigkeit, hybrid zu arbeiten und mittels MotherDuck Anbindungen an Cloud-Objektspeicher und skalierbare Compute-Ressourcen auf Knopfdruck verfügbar zu machen. Die dritte Option basiert auf Change Data Capture (CDC)-Technologien, insbesondere der Supabase ETL (ehemals pg_replicate). Hier wird der Fokus darauf gelegt, Datenänderungen in PostgreSQL in nahezu Echtzeit zu erfassen und kontinuierlich an eine analytische Plattform wie MotherDuck zu übertragen.
Mittels der logischen Replikation von PostgreSQL stellt dieses Verfahren sicher, dass Änderungen schnell und zuverlässig in ein anderes System repliziert werden, wodurch Analyse-Dashboards und operative Reports aktuell bleiben. Die Nutzung von CDC erfordert eine etwas komplexere Infrastruktur: Die Konfiguration der logischen Dekodierung, die Überwachung der Replikationsprozesse und die Sicherstellung der Datenkonsistenz müssen sorgfältig geplant und betrieben werden. Zudem ist ein gewisser Mehraufwand für Ressourcen im Datenbankserver erforderlich, da das Write Ahead Log (WAL) in höherem Detailgrad aufgezeichnet wird. Dennoch ist dieses Setup ideal für Unternehmen, die geringe Latenzzeiten bei der Datenverfügbarkeit brauchen und die analytische Last vollständig vom Produktionssystem trennen möchten. Beim Vergleich der Optionen zeigt sich, dass keine Einheitslösung alle Anforderungen perfekt erfüllt.
Der DuckDB Postgres Extension Ansatz eignet sich insbesondere für Anwendungsfälle mit überschaubaren Datenvolumen und einer niedrigen Komplexität der Analysen, in denen eine unkomplizierte und flexible Anbindung gefragt ist. Die pg_duckdb-Erweiterung schafft die Voraussetzung für High-Performance-Analytik direkt am PostgreSQL-Server, wobei der Betrieb auf dedizierten Replikaten eine verantwortungsvolle Infrastrukturplanung verlangt. Die CDC-basierte Supabase ETL wiederum ist die bevorzugte Wahl für Szenarien mit Echtzeitbedarfen und nahtlosem Datentransfer, bringt aber operativen Mehraufwand mit sich. Für die Praxis gilt es, neben den technischen Faktoren auch die betrieblichen Bedingungen, etwa Rechteverwaltung, Compliance, Betriebsmodelle und vorhandene Ressourcen, zu berücksichtigen. Grundsätzlich empfiehlt sich ein schrittweises Vorgehen: Bereits der Einstieg mit der einfachen DuckDB Postgres Extension kann wertvolle Erkenntnisse und Leistungsvorteile bringen, die später mit den komplexeren Varianten weiter optimiert werden können.
Im täglichen Betrieb sollten Monitoring und Ressourcenmanagement hohe Priorität genießen, um Engpässe frühzeitig zu erkennen und die Systeme stabil zu halten. Zur Unterstützung steht eine breite Dokumentation sowie aktive Community zur Verfügung. Insgesamt erlaubt die Symbiose von PostgreSQL mit DuckDB und MotherDuck es Unternehmen, die Stärken klassischer relationaler Systeme mit moderner analytischer Verarbeitung zu vereinen. Daten können dort verwaltet werden, wo sie benötigt werden, ohne dass aufwändige Datenbewegungen oder komplexe Data Warehouses unvermeidbar sind. Diese Kombination optimiert nicht nur die Performance, sondern verringert auch Komplexität und Kosten.
Unternehmen, die auf zuverlässige, schnelle und flexible Datenanalysen angewiesen sind, finden in dieser Lösung einen zukunftssicheren und skalierbaren Pfad. Die Integration von PostgreSQL mit DuckDB repräsentiert einen Paradigmenwechsel im Umgang mit Daten: weg von der silobasierten Analyse hin zu einem integrierten, effizienten System, das intuitiv bedienbar ist und die vorhandenen Ressourcen bestmöglich nutzt. So wird aus der vermeintlichen Gegnerschaft zwischen OLTP- und OLAP-Workloads ein harmonisches Zusammenspiel, das innovative datengetriebene Anwendungen und Entscheidungsfindung fördert. Wer bereit ist, in diese Technologie zu investieren und die jeweiligen Stärken gezielt einzusetzen, wird langfristig von robusteren Systemen und schnelleren Einblicken profitieren.


![No CVR or FDR on 787: Instead, Two EAFRs (Enhanced Airborne Flight Recorder) [pdf]](/images/53CC9CC7-AABA-4093-B534-D04A5A248914)



![Gemini 2.5 Technical Report [pdf]](/images/5498FD5F-E4F3-416B-AC17-F42CD147531F)
![Value-Null Antinatalism [pdf]](/images/2BFF6C48-8B0B-48AD-8ACF-121D302AE006)
