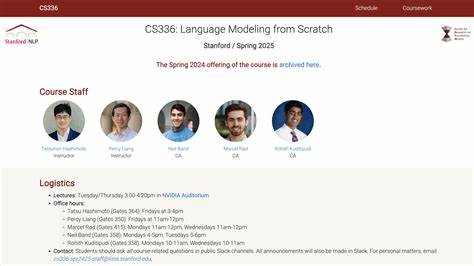
Der Kurs Stanford CS336 mit dem Titel „Language Modeling from Scratch“ bietet Studierenden die einzigartige Möglichkeit, die Welt der Sprachmodellierung ganz von Grund auf zu entdecken und zu erlernen. In einer Zeit, in der Sprachmodelle die Basis vieler Anwendungen im Bereich der natürlichen Sprachverarbeitung (Natural Language Processing, NLP) bilden, ist ein tiefgehendes Verständnis dieses Themas für angehende Wissenschaftler und Entwickler unverzichtbar. Der Kurs, der im Frühjahr 2025 angeboten wird, knüpft an eine erfolgreiche Version aus dem Frühjahr 2024 an und ist darauf ausgelegt, Studierenden nicht nur theoretisches Wissen, sondern vor allem praktische Kompetenzen im Umgang mit modernen Sprachmodellen zu vermitteln. Das erklärt die intensive Gewichtung auf Softwareentwicklung und Systemoptimierung im Kursverlauf. Was macht den Kurs so besonders? Das Konzept orientiert sich an einem Entwickleransatz, der an Betriebssystemkurse erinnert, bei denen Teilnehmer ein komplettes Betriebssystem selbst entwickeln.
Genauso führt CS336 die Studierenden durch alle Phasen der Sprachmodellentwicklung, angefangen bei der Datensammlung und -aufbereitung, der Konstruktion von Transformer-Modellen, über das Training der Modelle bis hin hin zur Evaluierung und letztlich dem Einsatz. Dieses Vorgehen vermittelt nicht nur Wissen über einzelne Bausteine, sondern ein ganzheitliches und tiefes Verständnis. Voraussetzung für die Teilnahme an diesem Kurs ist eine solide Erfahrung in Python-Programmierung, da der Großteil der Aufgaben direkt in dieser Sprache zu bewältigen ist. Der Programmieraufwand ist dabei deutlich höher als bei vergleichbaren AI-Kursen. Zudem wird von den Studierenden erwartet, dass sie sich mit Deep Learning Frameworks wie PyTorch auskennen und grundlegende Kenntnisse von Systemkonzepten, beispielsweise Speicherhierarchien, mitbringen.
Das Verständnis mathematischer Grundlagen wie Lineare Algebra und Wahrscheinlichkeitsrechnung ist ebenfalls Voraussetzung, weil diese die Basis bilden, um komplexere Modelle und Algorithmen leichter zu verstehen und umzusetzen. Besonders spannend ist die Ausrichtung auf Systeme, die es ermöglichen, Sprachmodelle effizient auf GPUs und über mehrere Maschinen hinweg zu betreiben. In der Praxis bedeutet dies, dass die Studierenden nicht nur die Modellarchitektur begreifen, sondern auch lernen, wie sich Modelle skalieren lassen und welche technischen Herausforderungen dabei auftreten. Diese Kombination aus KI-Theorie und Systemoptimierung hebt CS336 deutlich von anderen NLP-Kursen ab. Die Kursstruktur besteht aus mehreren anspruchsvollen Aufgaben, die jeweils verschiedene Aspekte der Sprachmodellierung behandeln.
Die erste Aufgabe konzentriert sich auf grundlegende Komponenten wie Tokenizer, Modellarchitektur und Optimierer. Die Teilnehmenden implementieren einen einfachen Transformer-basierten Sprachmodelltrainer, der den Einstieg erleichtert und erste praktische Erfahrungen ermöglicht. Diese Implementierung wird im weiteren Kursverlauf durch komplexere Optimierungen und Skalierung erweitert. In der zweiten Aufgabe geht es um Systemoptimierung. Teilnehmer analysieren und messen die Performance aus der ersten Aufgabe, implementieren effiziente Attention-Methoden wie FlashAttention2 in Triton und bauen eine verteilte und speichereffiziente Version ihres Trainingscodes.
Solche Kompetenzen sind in realen Anwendungen unverzichtbar, um mit den stets wachsenden Datenmengen und Modellgrößen umzugehen. Später folgt die Beschäftigung mit Skalierungsgesetzen, die beschreiben, wie sich die Leistung von Sprachmodellen beim Vergrößern der Modellgröße verändert. Die Studierenden lernen, Trainings-APIs zu verwenden, um vorherzusagen, wie ihre Modelle auf Skalierung reagieren, was ein wichtiger Schritt ist, um Ressourcen effizient einzusetzen und besser zu verstehen, wann Leistungsverbesserungen durch mehr Parameter oder Daten erzielt werden. Ein weiterer zentraler Teil des Kurses besteht in der Datenaufbereitung. Da Sprachmodelle stark von der Datenqualität abhängen, erfahren die Teilnehmenden, wie man große Rohdaten, beispielsweise den Common Crawl-Datensatz, umwandelt, filtert und dedupliziert.
Dies verbessert die Qualität der Vortrainingsdaten maßgeblich und hat einen direkten Einfluss auf die finale Leistungsfähigkeit der Modelle. Gegen Ende des Kurses stehen Themen wie Alignment und reasoning im Fokus, die aktuelle Forschungsthemen darstellen. Durch Supervised Finetuning und Reinforcement Learning wird den Modellen beigebracht, besser zu argumentieren und komplexe Aufgaben zu lösen. Optional kann man sich sogar noch mit Sicherheitstechniken und Alignmentsmethoden wie Direct Preference Optimization (DPO) befassen, um sicherzustellen, dass Modelle verantwortungsvoll und zuverlässig agieren. Neben den Kursinhalten zeichnet sich CS336 auch durch seine Struktur und organisatorische Unterstützung aus.
Die Vorlesungen finden zweimal wöchentlich im bekannten NVIDIA Auditorium statt, wobei das Kursmaterial vorausschauend digital bereitgestellt wird. Die offizielle Kommunikation und der Austausch unter Studierenden sowie mit Dozenten und Assistierenden erfolgen hauptsächlich über Slack, was eine unkomplizierte Kollaboration fördert. Das Team aus Professoren und Kursassistenten hält regelmäßige Sprechstunden an verschiedenen Tagen ab, um bei inhaltlichen Fragen oder in der Praxis auftretenden Schwierigkeiten Unterstützung zu leisten. Ein besonderes Merkmal ist die Betonung der akademischen Integrität: Eigenständigkeit wird großgeschrieben, während die Verwendung von KI-Tools wie ChatGPT zu Programmier- oder Konzeptfragen unter bestimmten Auflagen erlaubt ist, direkte Nutzung zur Lösung von Aufgaben jedoch strikt untersagt bleibt. Diese Regelung fördert tieferes Verständnis und intensive Auseinandersetzung mit dem Stoff.
Für Studierende, die zuhause mitmachen, ist es zudem möglich, über verschiedene Cloud-Anbieter wie RunPod, Lambda Labs und Paperspace GPU-Rechenleistung zu kaufen. So wird das Training großer Modelle trotz begrenzter lokaler Ressourcen ermöglicht, was für die praktische Umsetzung der Aufgaben essenziell ist. Die Organisation rund um Deadlines, Einreichung der Aufgaben über Plattformen wie Gradescope und Kulanzregelungen bei verspäteten Abgaben sind klar kommuniziert und sorgen für eine transparente und faire Kursdurchführung. Insgesamt liefert Stanford CS336 eine tiefgreifende und praxisnahe Ausbildung im Bereich moderner Sprachmodellierung, die sowohl Grundlagen als auch fortgeschrittene Themen abdeckt. Die Studenten verlassen den Kurs mit fundiertem Wissen über Transformer-Architekturen, Optimierungstechniken, Skalierungsgesetze und Datenaufbereitung, aber auch mit einem erheblichen Anteil an selbst erstelltem Code und Verständnis für Systems Engineering.
In Kombination mit den Themen rund um Alignment und sicheres AI-Verhalten bereitet der Kurs optimal auf eine Karriere in der schnell wachsenden und hochrelevanten AI-Branche vor. Für alle, die sich für zukünftige Technologien rund um Künstliche Intelligenz und Sprachverarbeitung interessieren, ist der Kurs eine wertvolle Investition in Wissen und Fähigkeiten, die vom akademischen Umfeld bis in die Industrie reichen. Stanford CS336 ist damit nicht nur ein Kurs, sondern eine umfassende Lernerfahrung, die Maßstäbe in der Ausbildung der nächsten Generation von NLP- und ML-Experten setzt.