Die rasante Entwicklung von Künstlicher Intelligenz, insbesondere von großen Sprachmodellen (LLMs), hat das Potenzial, viele Bereiche unseres Lebens nachhaltig zu verändern. Von der automatisierten Textgenerierung bis hin zu komplexen Entscheidungsunterstützungssystemen vertrauen Unternehmen und Forschende gleichermaßen auf diese Technologie. Doch trotz beeindruckender Fortschritte kämpfen heutige KI-Modelle weiterhin mit einem gravierenden Problem: der Produktion von sogenannten Halluzinationen – das heißt falschen oder nicht belegbaren Aussagen, die die Modelle generieren. Um diesem Phänomen entgegenzuwirken, wurde die innovative Methode "Grounded in Context" entwickelt, die einen entscheidenden Fortschritt bei der Erkennung solcher Halluzinationen darstellt.Die Herausforderung der Halluzinationen in KI-Anwendungen ist vielschichtig.
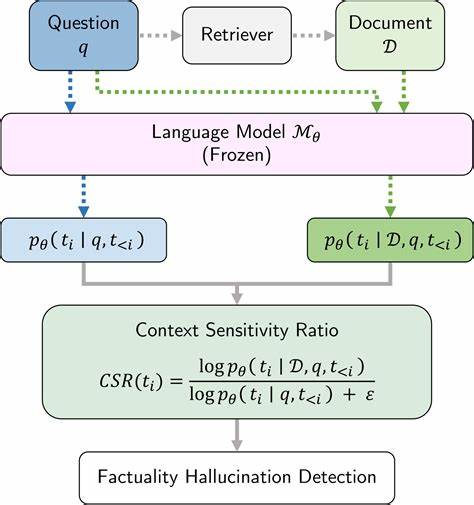
Im Kern entsteht das Problem, weil Modelle oft Antworten generieren, die zwar plausibel klingen, aber faktisch nicht korrekt sind. Gerade in Anwendungsszenarien wie der automatischen Zusammenfassung großer Textmengen, der Datenextraktion aus Dokumenten oder dem Retrieval-Augmented Generation (RAG) kann dieses Verhalten schwerwiegende Folgen haben. Eine falsche oder fehlerhafte Information kann das Vertrauen in das System untergraben oder sogar zu falschen Entscheidungen führen.Grounded in Context rückt genau hier an. Dieser Ansatz basiert auf der Kombination von Retrieval-Techniken und Natural Language Inference (NLI).
Retrieval-Methoden dienen dazu, relevante Textfragmente aus einer großen Datenbasis heranzuziehen, die als Kontext und Faktenquelle dienen. Das Modell prüft dann mittels NLI, ob die generierten Aussagen (Hypothesen) durch den extrahierten Kontext (Prämissen) gestützt werden. Dieses Prinzip ähnelt der Art und Weise, wie Menschen Fakten prüfen: Sie vergleichen eine Behauptung mit verfügbaren Informationen, um deren Richtigkeit zu bewerten.Das Besondere an Grounded in Context ist die hohe Effizienz und Skalierbarkeit im Umgang mit langen und komplexen Kontexten. Während viele Prüfsysteme von der Länge des Textes und der Rechenkapazität limitiert sind, setzt dieser Ansatz auf ein Encoder-basiertes Modell, das mit einer Fenstergröße von 512 Tokens arbeitet.
Das bedeutet, dass nur ein begrenzter Ausschnitt des gesamten Kontextes zur selben Zeit betrachtet wird. Dabei gelingt es dem System trotzdem, eine hohe Präzision bei der Erkennung von fehlerhaften Behauptungen zu erzielen.Im Rahmen von Benchmark-Tests, insbesondere in der RAGTruth-Datenbank für derartige Prüfaufgaben, erzielte Grounded in Context eine herausragende Leistung mit einem F1-Score von 0,83. Dieser Wert bestätigt nicht nur die hohe Treffsicherheit des Systems bei der Klassifizierung von Antwortlevel-Faktenkonsistenz, sondern macht es auch mit Methoden vergleichbar, die auf sehr großen und spezialisierten Modellen beruhen. Gleichzeitig übertrifft es dabei alle anderen Frameworks, die mit ähnlich großen Modellen arbeiten.
Damit wird klar, dass es möglich ist, mit moderatem Ressourcenaufwand eine zuverlässige Halluzinationserkennung in der Praxis zu etablieren.Die Grundlage dieser Technik wurzelt maßgeblich in der Architektur von Retrieval-Augmented Generation. RAG ist ein Verfahren, das die Sprachmodellgenerierung mit externem Faktenwissen kombiniert, indem relevante Dokumente oder Datenfragmente abgerufen und in den Generierungsprozess integriert werden. Grounded in Context ergänzt diesen Ansatz um eine kritische Kontrollinstanz, die die faktische Wahrhaftigkeit der generierten Inhalte überprüft, bevor sie weiterverarbeitet oder genutzt werden. Dies macht die Methode besonders geeignet für produktive Einsatzumgebungen, in denen hohe Genauigkeit und Zuverlässigkeit unabdingbar sind.
Neben der technischen Komponente liegt auch ein großer Vorteil von Grounded in Context in der Flexibilität der Anwendung. Egal ob bei Textzusammenfassungen, bei der Extraktion strukturierter Daten aus unübersichtlichen Dokumenten oder bei interaktiven Assistenzsystemen mit langen Gesprächskontexten – die Methode lässt sich leicht an verschiedene Use Cases anpassen. Das ist besonders wichtig, da viele bestehende Verfahren entweder zu spezialisiert oder zu ressourcenintensiv sind und somit in der Praxis oft nicht einsetzbar bleiben.Die Entwicklung von Grounded in Context spiegelt ein wachsendes Bewusstsein in der KI-Community wider: Die Verlässlichkeit von generierten Inhalten ist mindestens genauso wichtig wie deren kreative Fähigkeiten. In einem Zeitalter, in dem KI-gestützte Systeme immer stärker in das tägliche Leben eingreifen und Entscheidungen beeinflussen, ist der Wunsch nach nachvollziehbarer und überprüfbarer KI gestiegen.
In diesem Sinne trägt die vorgestellte Methode maßgeblich dazu bei, die Vertrauenswürdigkeit von automatisierten Systemen zu stärken und damit eine breitere Akzeptanz und Nutzung zu ermöglichen.Zukunftsperspektivisch könnten Ansätze wie Grounded in Context auch in Kombination mit anderen Techniken weiterentwickelt werden, etwa durch die Integration von multimodalen Daten oder die Einbindung von dynamischem Wissensmanagement. Auch die Erweiterung der Kontextfenster und die Verbesserung der semantischen Erkennung versprechen weitere Optimierungen. Sinnvoll wäre zudem die Kombination mit erklärbaren KI-Methoden, um den Nutzerinnen und Nutzern noch mehr Transparenz über die Entscheidungsprozesse der Modelle zu bieten.Zusammenfassend lässt sich sagen, dass Grounded in Context einen bedeutenden Schritt nach vorne im Kampf gegen KI-Halluzinationen darstellt.
Es verbindet effiziente Retrieval-Methoden mit präziser logischer Inferenz, um eine robuste Bewertung von Faktenkonsistenz zu gewährleisten. Damit bietet es eine zukunftsweisende Lösung für Unternehmen und Forschungseinrichtungen, die auf verlässliche KI-Inhalte angewiesen sind. Gerade im Zeitalter hoher Datenmengen und wachsender komplexer Anwendungen zeigt sich, wie wichtig solche kontrollierenden Modelle sind, um die vollständige Potenzialentfaltung künstlicher Intelligenz nachhaltig zu unterstützen und Risiken zu minimieren.