Die rasante Entwicklung großer Sprachmodelle (Large Language Models, LLMs) verändert viele Wissenschaftsbereiche grundlegend – so auch die Chemie. In den letzten Jahren haben Fortschritte im maschinellen Lernen dazu geführt, dass diese Modelle weit mehr leisten können als nur Sprache zu verarbeiten: Sie zeigen zunehmend ein Verständnis komplexer Fachinhalte und sind in der Lage, Aufgaben zu lösen, für die sie nicht explizit trainiert wurden. Doch wie schneiden diese Modelle im direkten Vergleich mit menschlicher Expertise in der Chemie ab? Welche Möglichkeiten und Grenzen ergeben sich bei der Nutzung von LLMs in der chemischen Forschung und Lehre? Die Antwort auf diese Fragen liefert neueste Forschungsergebnisse, die im Rahmen eines eigens entwickelten Evaluationsrahmens namens ChemBench entstanden sind. ChemBench ist eine umfangreiche Benchmark-Plattform, die mehr als 2.700 Frage-Antwort-Paare umfasst und darauf abzielt, die chemischen Wissens- und Denkfähigkeiten von führenden Sprachmodellen systematisch zu bewerten.
Dabei wurde eine Vielzahl unterschiedlichster chemischer Themenbereiche abgedeckt, von allgemeinen Grundlagen bis hin zu spezialisierten Feldern wie anorganischer oder analytischer Chemie. Die Fragen wurden manuell und halbautomatisch aus diversen Quellen zusammengestellt, darunter Universitätsprüfungen, Lehrbücher und Datenbanken. Eine der herausragenden Erkenntnisse aus der ChemBench-Studie ist, dass die besten LLMs im Durchschnitt sogar die Leistung erfahrener Chemikerinnen und Chemiker übertreffen können. Das begeisternde Ergebnis manifestiert sich vor allem bei der Bewältigung von breit gefächerten und standardisierten Wissensfragen. Dennoch offenbaren die Modelle deutliche Schwächen bei grundlegenden Aufgaben sowie eine bedenkliche Tendenz zu übermäßiger Selbstsicherheit – das heißt, sie zeigen oft eine falsche Gewissheit in ihren Antworten, auch wenn diese falsch sind.
Diese Beobachtung hat weitreichende Konsequenzen. In der chemischen Forschung und Industrie basiert der Fortschritt nicht allein auf Faktenwissen, sondern auch auf kritischem Denken, intuitivem Verständnis und der Fähigkeit, komplexe Zusammenhänge zu durchdringen und neue Hypothesen zu generieren. Während LLMs durch ihre enorme Datenbasis viele Informationen schnell abrufen können, scheinen sie im Moment noch begrenzte Fähigkeiten beim strukturierten logischen Schlussfolgern und tiefgreifender chemischer Intuition zu besitzen. Darüber hinaus ist die Qualität der Trainingsdaten maßgeblich: Die Modelle haben nicht die Fähigkeit, eigenständig neue Erkenntnisse zu generieren, sondern „lernen“ durch Mustererkennung aus den umfangreichen Textdaten, mit denen sie gefüttert wurden. Dadurch lassen sich vor allem bei komplexen Fragen oder bei besonders spezialisierten Themenbereiche weiterhin Fehler beobachten.
Eine weitere Herausforderung ist, dass die besten Ergebnisse nur durch eine Kombination von LLMs mit externen Tools erreicht werden können, etwa durch Websuche oder Zugriff auf spezialisierte Datenbanken wie PubChem. Die ChemBench-Analyse zeigt ferner, dass der Erfolg der Modelle nicht gleichmäßig über alle chemischen Teilgebiete verteilt ist. Besonders gut schneiden sie in allgemeinen und technischen Fragen ab, während analytische Chemie und insbesondere Sicherheitsthemen Schwierigkeiten bereiten. Das ist bemerkenswert, weil Kenntnisse zur Sicherheit und Toxizität von Stoffen von hoher praktischer Bedeutung sind – Fehler in diesen Bereichen können schwerwiegende Konsequenzen haben. Ein besonders spannender Teilaspekt der Untersuchung betrifft die Fähigkeit der Modelle, menschliche Präferenzen – etwa in Bezug auf Molekülattraktivität oder Synthesefreundlichkeit – zu beurteilen.
Hier liegen die Modelle noch deutlich hinter den Experten, oft kaum besser als Zufall. Dies legt nahe, dass direktes Nachahmen von Fachwissen nicht automatisch zu einer Integration von fachspezifischer Intuition führt. Ein weiteres zentrales Problem ist das mangelnde Vertrauen der Modelle in ihre eigene Korrektheit. Wünschenswert wäre, dass KI-Systeme nicht nur Ergebnisse liefern, sondern auch aussagekräftige Unsicherheitsabschätzungen – eine Eigenschaft, die bisher nur unzureichend entwickelt ist. So berichten die Modelle häufig hohe Zuversicht bei Antworten, die falsch sind, und umgekehrt – ein riskantes Verhalten, wenn Anwender sich zu sehr auf Modellantworten verlassen.
Die Forscher hinter ChemBench betonen, dass die derzeitigen Bewertungsmethoden in der Chemie – oft lediglich Multiple-Choice-Tests oder einfache Vorhersagen von Moleküleigenschaften – die tatsächlichen kognitiven Fähigkeiten, die für echte Forschung nötig sind, nur eingeschränkt abbilden. Die neuen Benchmark-Fragen umfassen daher offenere Fragen sowie komplexere Denkaufgaben, um den realen Anforderungen besser gerecht zu werden. Diese Erkenntnisse werfen auch einen neuen Blick auf die chemische Bildung und Didaktik. Die Tatsache, dass Sprachmodelle viele Fakten automatisch abrufen und reproduzieren können, veranlasst dazu, den Fokus in der Ausbildung stärker auf kritische Denkfähigkeiten, Problemlösungskompetenzen und experimentelle Kreativität zu legen. Es zeigt sich, dass reines Auswendiglernen von Fakten keine nachhaltige Kompetenz mehr darstellt, wenn KI-Systeme diese Aufgaben zukünftig übernehmen können.
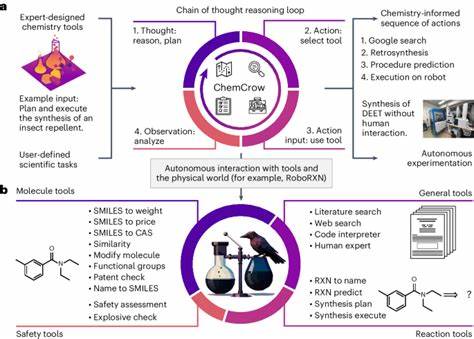
Unter Wissenschaftlern und Praktikern besteht große Zuversicht, dass LLMs als Werkzeuge den wissenschaftlichen Fortschritt durchaus beschleunigen können, etwa indem sie als chemische Copiloten fungieren. In dieser Rolle könnten sie Wissenschaftlerinnen und Wissenschaftlern dabei helfen, Informationen schneller zu erschließen, Literatur zu sichten, Reaktionswege vorzuschlagen oder Hypothesen zu generieren. Allerdings wird deutlich, dass diese Systeme nur in Kombination mit kritischem menschlichem Urteil und tiefgreifender Fachkenntnis sinnvoll eingesetzt werden können. Die Gefahr, dass Fehlinformationen – speziell zu Sicherheit und Toxikologie – unbeabsichtigte Schäden verursachen, ist gerade bei uneingeweihten Anwendern oder Laien eine wichtige Sorge. Deshalb ist die Weiterentwicklung zuverlässiger Sicherheitsmechanismen und transparenter Rückmeldungen innerhalb der Modelle unerlässlich.
In der Praxis stellen Modelle wie GPT-4 und verwandte Systeme bereits heute beeindruckende Werkzeuge dar, die auf Basis großer Textmengen Wissen konsolidieren und anwenden können. Gleichzeitig zeigt ChemBench, dass auch offene Modelle wie LLaMA sehr konkurrenzfähig sind und der Trend allgemein dahin geht, dass mit steigender Modellgröße und gezieltem Training auf fachspezifische Daten die Leistungsfähigkeit weiter wachsen wird. Ein weiterer spannender Fortschritt ist die Entwicklung sogenannter agentbasierter Systeme, die LLMs mit Zugriff auf externe Datenbanken, Tools zur Strukturvisualisierung oder Syntheseplaner verknüpfen und so eine multimodale und aktionsfähige Wissensbasis schaffen. Diese Systeme haben das Potenzial, die reine Textverarbeitung zu erweitern und praktischere Anwendungen zu unterstützen. Insgesamt beweist die ChemBench-Studie, dass wir erst am Anfang einer tiefgreifenden Transformation im Bereich der chemischen Informationsverarbeitung stehen.