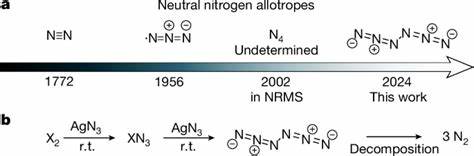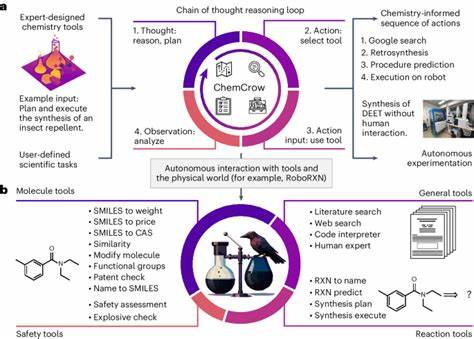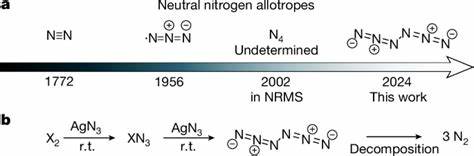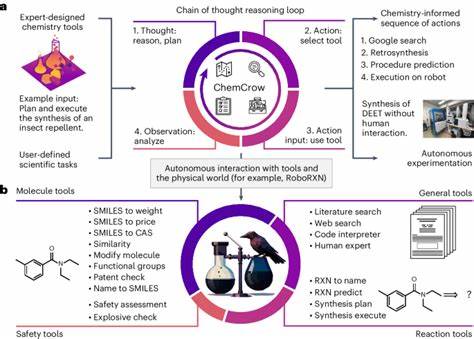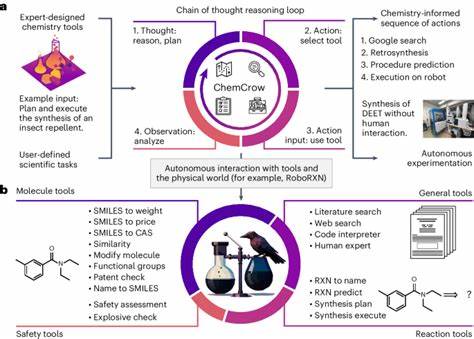
In den vergangenen Jahren hat die künstliche Intelligenz (KI) enorme Fortschritte gemacht, insbesondere im Bereich der Sprachmodelle, sogenannter Large Language Models (LLMs). Diese Modelle haben die Fähigkeit entwickelt, natürliche Sprache nicht nur zu verstehen, sondern auch komplexe Anfragen zu wissenschaftlichen Themen zu beantworten und eigenständig Schlussfolgerungen zu ziehen. Besonders spannend ist die Anwendung dieser Technologie in der Chemie, einem Fachgebiet, das neben fundiertem Faktenwissen auch hohe Anforderungen an logisches Denken und Intuition stellt. Doch wie schneiden LLMs im direkten Vergleich mit erfahrenen Chemikern ab? Und welche Auswirkungen hat das auf zukünftige Forschungs- und Bildungsprozesse? Ein aktuelles Forschungsprojekt liefert dazu aufschlussreiche Erkenntnisse. Die Grundlage für den Vergleich zwischen menschlichen Chemikern und KI-Systemen bildet ChemBench, ein umfassendes Bewertungsframework, das über 2.
700 Frage-Antwort-Paare aus unterschiedlichen Themenbereichen der Chemie umfasst. Diese Fragen variieren in Schwierigkeit, Art des erforderlichen Wissens und Grad der erforderlichen Schlussfolgerungskompetenz. Durch systematische Tests wurden verschiedenste führende große Sprachmodelle auf ihre chemischen Kenntnisse hin untersucht und in einer parallelen Studie mit menschlichen Experten verglichen. Dabei zeigte sich überraschend, dass die besten Modelle im Durchschnitt besser abschnitten als die befragten Chemiker – zumindest was die reine Korrektheit der Antworten betrifft. Diese Resultate sind zweifellos beeindruckend und werfen ein neues Licht auf die Fähigkeiten moderner KI-Systeme.
Die Modelle können ein breites Spektrum an Wissen abrufen und komplexe Zusammenhänge analysieren, ohne speziell für einzelne Fragestellungen trainiert worden zu sein. Dennoch gibt es auch deutliche Schwächen. Beispielsweise zeigen die LLMs Probleme mit elementaren Aufgaben, die tiefes Verständnis von molekularer Struktur und Chemie erfordern, wie die Interpretation von NMR-Spektren oder das korrekte Zählen von Isomeren. Hier profitieren menschliche Chemiker von ihrem intuitiven Zugang und ihrem langjährigen Erfahrungswissen. Ein weiterer wichtiger Punkt ist die Überkonfidenz, mit der manche KI-Modelle Antworten präsentieren.
Selbst wenn die Antwort falsch ist, wird diese oft mit hoher Sicherheit ausgegeben, was in sicherheitskritischen Kontexten wie der chemischen Sicherheit oder Toxikologie riskant sein kann. Solche Fehleinschätzungen unterstreichen den Handlungsbedarf bei der Entwicklung zuverlässiger KI-Systeme, die ihre Ungewissheiten auch eigenständig kommunizieren können. Inhaltlich deckt die Bewertung verschiedenste Teilgebiete der Chemie ab, von anorganischer und organischer Chemie über technische bis hin zu analytischer Chemie. Besonders ambitionierte LLMs zeigen bei traditionellen Lehrbuchfragen gute Ergebnisse, stoßen jedoch an Grenzen bei praxisorientierten oder komplexeren Aufgabenstellungen, die eine Vielzahl von Rechen-, Analyse- oder Interpretationsschritten erfordern. Das legt nahe, dass der reine Zugriff auf große Datenmengen allein nicht ausreicht; vielmehr ist ein tieferes Verständnis chemischer Prinzipien und Modelle für echte Fortschritte nötig.
Die Untersuchung zeigt außerdem, dass die Fähigkeit der Modelle stark mit deren Größe zusammenhängt. Größere Modelle schneiden in der Regel besser ab, was auf die These hindeutet, dass das weitere Skalieren der Modelle ein vielversprechender Weg zur Verbesserung ihrer chemischen Kompetenz sein könnte. Dennoch ist Skalierung allein kein Allheilmittel. Spezielle Trainingsdaten, etwa aus Fachdatenbanken wie PubChem oder Gestis, sowie optimale Integration von Werkzeugen und Suchmechanismen sind entscheidend, um Wissenslücken zu schließen. Ein interessanter Aspekt der Studie betrifft die Fähigkeit der LLMs, Präferenzen oder „chemische Intuition“ zu reproduzieren.
Im Bereich der Wirkstoffforschung beispielsweise ist es essentiell, bei der Moleküloptimierung eine gewisse Vorliebe und Einschätzung zu entwickeln, die über bloße numerische Bewertungen hinausgeht. Die Modelle konnten in Tests kaum mit den Präferenzen menschlicher Chemiker mithalten und performten teilweise nur auf Zufallsniveau. Das deutet darauf hin, dass weiteres Forschungspotential in der Einbindung von Preference Tuning besteht – also der Anpassung von Modellen an menschliche Bewertungsmaßstäbe. Die methodische Gestaltung von ChemBench ist bewusst darauf ausgelegt, realistische und offene Fragestellungen zu verwenden und nicht nur Multiple-Choice Tests, die das Spektrum chemischer Kompetenz einschränken würden. Das trägt dazu bei, dass die Ergebnisse einen realitätsnahen Eindruck vermitteln, welcher letztlich wichtig ist, wenn LLMs als „Co-Piloten“ in der chemischen Forschung eingesetzt werden sollen.
Für die Lehre im Fach Chemie hat die Studie ebenfalls weitreichende Konsequenzen. Da LLMs klassische Examensfragen oder Faktenwissen oft mit Bravour meistern, rücken kritische Denkfähigkeiten, argumentatives Vorgehen und experimentelle Reflexion in den Vordergrund. Die Ausbildung muss daher angepasst werden, um menschliche Kompetenzen zu stärken, die nicht automatisierbar sind. Risiken im Umgang mit KI in der Chemie bestehen vor allem im falschen Vertrauen auf die Antworten der Modelle, insbesondere im Kontext von Sicherheit und Toxizität. Falsche oder unvollständige Informationen können zu gefährlichen Fehlentscheidungen führen, wenn Nutzer ohne tiefgehendes Hintergrundwissen die Modelle zur Bewertung chemischer Substanzen heranziehen.
Um das zu vermeiden, sind klare Nutzungskonzepte, Validierungsprozesse sowie vertrauenswürdige Interaktionsschnittstellen nötig. Zusammenfassend offenbart die Evaluierung von LLMs im chemischen Bereich ein Bild dualer Natur. Einerseits sind diese Modelle wahre Kraftpakete mit der Fähigkeit, komplexe Fragestellungen zu beherrschen und sogar menschliche Experten zu übertreffen. Andererseits zeigen sie, dass reines Faktenwissen und skalenbasierte Leistung nicht ausreichen, um chemisches Denken und Urteilsvermögen vollständig zu ersetzen. Die Zukunft wird davon geprägt sein, wie gut es gelingt, die Stärken von Menschen und Maschinen zu vereinen.
In den kommenden Jahren werden Fortschritte in den Bereichen multimodale Modelle, die beispielsweise auch graphbasierte molekulare Darstellungen verarbeiten, sowie verbesserte Datenintegration und Tool-Augmentation entscheidend sein. Systeme, die nicht bloß Antworten liefern, sondern ihre Unsicherheiten offenlegen, Zusammenhänge transparent machen und flexibel mit Experten kommunizieren können, werden zukünftig die Forschung in Chemie und Materialwissenschaften verändern. Die Arbeit mit ChemBench zeigt zudem, wie wichtig es ist, standardisierte, breit angelegte und qualitativ hochwertige Bewertungsbenchmarks zu etablieren. Solche Rahmenwerke ermöglichen eine klare Einschätzung des aktuellen Stands der Technik, fördern die Transparenz und bieten Anhaltspunkte für gezielte Verbesserungen und Innovationen. Gleichzeitig unterstützen sie eine verantwortungsvolle Nutzung der KI in der Wissenschaft und Gesellschaft.
Abschließend wird klar: Large Language Models sind angekommen in der Welt der Chemie. Sie bieten großes Potenzial, eröffnen neue Wege zur Wissenserschließung und Forschung, setzen jedoch auch einen neuen Maßstab an wissenschaftliche Bildung und kritische Evaluation. Menschliche Expertise bleibt weiterhin unverzichtbar. Die beste Lösung wird darin liegen, Mensch und Maschine als Partner zu begreifen und gemeinsam das Unbekannte zu erkunden.