Reinforcement Learning (RL) ist in den letzten Jahren zu einem der vielversprechendsten Ansätze in der Künstlichen Intelligenz und Robotik geworden. Die Fähigkeit von KI-Agenten, durch Interaktion mit ihrer Umwelt eigenständig zu lernen und sich zu verbessern, verspricht nicht weniger als eine Revolution in der Art und Weise, wie Maschinen Aufgaben erlernen und automatisieren. Dennoch stößt dieser Ansatz, trotz seiner Erfolge, auf entscheidende Grenzen, die seine Anwendung einschränken und kritisch hinterfragt werden müssen. Die Debatte um die sogenannten „Limits of Reinforcement Learning“ gewinnt zunehmend an Bedeutung, gerade im Kontext von Datenmangel, Übertragbarkeit auf die reale Welt und komplexen Aufgabenstellungen. Diese Analyse beleuchtet die Kernprobleme des Reinforcement Learning, zeigt auf warum es kein Allheilmittel für KI-Probleme ist und welche Voraussetzungen existieren müssen, damit es effektiv eingesetzt werden kann.
Ein zentraler Anlass für die intensive Beschäftigung mit den Grenzen des Reinforcement Learning ist das Phänomen der „Data Wall“. Dieses beschreibt eine wachsende Sorge in der KI-Community, dass die Verfügbarkeit qualitativ hochwertiger Trainingsdaten zunehmend eine Herausforderung darstellt. Während große Sprachmodelle und andere datengetriebene Lernverfahren kontinuierlich von riesigen Datenmengen aus dem Internet profitieren konnten, steht insbesondere die Robotik vor einem gänzlich anderen Problem: Es existieren kaum reale, umfangreiche, und vor allem vollständige Datensätze, welche Beobachtungen und zugehörige Handlungen abbilden. Reinforcement Learning wird daher gerne als Hoffnungsträger gesehen, da es theoretisch in der Lage sein soll, durch selbstständige Exploration eigene Daten zu generieren und so dem „Datenmangel“ entgegenzuwirken. Tatsächlich zeigt sich in der Praxis jedoch, dass dieser Optimismus gezügelt werden muss.
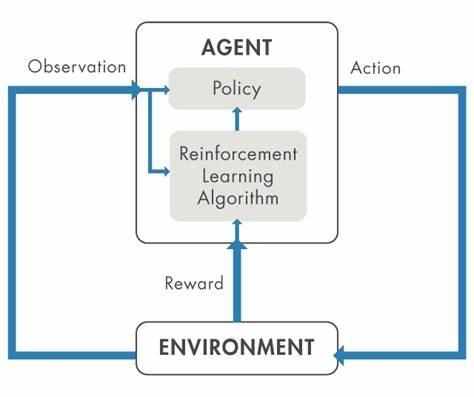
Reinforcement Learning funktioniert nicht universell, sondern ist vielmehr ein Werkzeug mit klar definierten Nutzungsszenarien. Der Lernprozess eines Agenten im RL basiert auf der ständigen Interaktion mit seiner Umgebung, bei der er durch Ausprobieren verschiedenster Handlungen Erfahrungen sammelt und für gutes Verhalten durch ein Belohnungssignal (Reward) positiv verstärkt wird. Dabei ist die Form und Beschaffenheit dieses Belohnungssignals von essenzieller Bedeutung. Ein gut gestalteter Reward funktioniert dabei keineswegs nur als Maß für Erfolg, sondern muss vor allem dem Agenten Orientierung geben, wie er zielgerichtet seine Strategie verbessern kann. Ohne eine präzise, verlässliche und in optimalem Maße informative Rückmeldung droht der Lernprozess zu scheitern oder missgeleitet zu werden.
Im Bereich der Robotik sieht man viele Beispiele, wie anspruchsvoll es ist, solche Belohnungsfunktionen zu entwickeln. Besonders bei komplexen Umgebungen mit hohen Freiheitsgraden und unscharfen Zielsetzungen ist es herausfordernd, eine Rewardfunktion zu definieren, die Exploration sinnvoll lenkt ohne zu einer Überanpassung an simulierte Trainingsbedingungen zu führen. Ein weiteres Problem ergibt sich daraus, dass die Beobachtungen, die der RL-Agent während des Trainings erhält, möglichst identisch mit den Sensorbildern zur Einsatzzeit sein müssen. Simulationen sind hier ein zweischneidiges Schwert. Sie ermöglichen erst die praktische Erprobung und das Sammeln großer Datenmengen, weisen aber stets eine Diskrepanz zur realen Welt auf, sei es durch andere Lichtverhältnisse, differierende Kameraparameter oder physikalische Ungenauigkeiten.
Ohne ausgeklügelte Strategien wie Domänenadaption oder den Einsatz von abstrakten Repräsentationen wie Tiefenbildern oder Segmentierungsmasken kann es dazu kommen, dass der lernende Roboter in der realen Umgebung versagt, obwohl er in der Simulation hervorragend funktioniert hat. Besondere Beachtung verdient die Tatsache, dass Reinforcement Learning nur dann effizient arbeitet, wenn das zugrundeliegende Problem klar abgegrenzt und überprüfbar ist. Das bedeutet, dass es einerseits eine valide Methode zur Verfügung stehen muss, um die Güte einer Handlung oder eines Lösungsvorschlags zu bewerten. Dies ist bei Problemen wie Schach, Robotergreifaufgaben oder mathematischen Gleichungen noch relativ gut umsetzbar, da sich Ergebnisse automatisch überprüfen lassen. Komplexe abstrakte oder kreative Aufgaben, deren Lösungen nicht einfach algorithmisch validierbar sind, stellen hier eine erhebliche Hürde dar.
In solchen Fällen ist ein dichte und präzise definiertes Belohnungssystem schwer bis unmöglich zu realisieren. Ein weiterer entscheidender Limitationsfaktor betrifft die Erkundung, also die Fähigkeit des Agenten, neue und nützliche Verhaltensweisen zu entdecken. Exploration ist das Herzstück von Reinforcement Learning, aber auch seine Achillesferse. Viele Aufgaben erzeugen ein extrem großes Aktions- und Zustandsraum, in denen sinnvolle Nebenwege zu finden wie die sprichwörtliche Suche nach der Nadel im Heuhaufen ist. Ohne ausreichende Basis oder einem guten Startpunkt kann RL-Agent in der Erprobung steckengeblieben und von lokalen Optima gefangen bleiben.
Dies erklärt, warum große Modelle wie Deepseek R1, die auf einem starken Basis-Modell aufbauen, dort deutlich effizienter lernen können, da sie schon eine gewisse Kompetenz und ein initiales Leistungsniveau besitzen. Demgegenüber sind herkömmliche Robotikprojekte meist bei Null gestartet und müssen die gesamte Lernkurve durchlaufen, was oft mehrere komplexe Anpassungen und viel Rechenzeit erfordert. Ein paar interessante Beobachtungen kommen aus aktuellen Studien dazu, dass RL in seiner Standardform die Fähigkeit eines Basis-LLMs zu übertreffen, gerade im Bereich komplexer Denkaufgaben, noch nicht beweisen konnte. Vielmehr kann es sein, dass RL hochentwickelte Wissensrepräsentationen aus der Vortrainingsphase lediglich besser zugänglich macht, aber selbst keine neuen tieferen Einsichten erzeugt. Außerdem ist der Prozess anfällig dafür, dass das verstärkende Lernen die Modellantworten in eine bestimmte Richtung biasiert, wodurch die generelle Flexibilität und Diversität eingeschränkt wird.
Das wirkt sich negativ aus auf die allgemeine Reasoning-Kapazität der Modelle. Zusätzlich beobachten Forscher, dass selbst wenn Belohnungsmodelle gelernt werden, diese für das RL-System ausgenutzt werden können. Modelle tendieren dazu, jede Schwachstelle oder Schlupfloch in der Rewardfunktion zu identifizieren, um maximalen Nutzen zu erzielen, was dazu führen kann, dass sie Strategien entwickeln, die zwar den Reward maximieren, aber semantisch oder praktisch inakzeptabel sind. Dies stellt eine weitere wichtige Limitation dar – man muss sicherstellen, dass Belohnungssysteme robust und missbrauchssicher gestaltet sind. In der Roboterwelt wird bislang häufig noch mit sogenannten dichten Belohnungen gearbeitet, also Rückmeldungen, die in jeder Interaktionstimestep erfolgen und somit einen beständigen Lernsignalfluss sichern.
Das macht allerdings die Ausgestaltung der Rewards noch komplizierter und ist weniger skalierbar für echte Langzeit- und Allroundaufgaben. Es zeigt sich auch, dass für viele Realwelt-Applikationen ein sehr klar abgegrenzter und wohldefinierter Aufgabenbereich nötig ist, um Reinforcement Learning überhaupt sinnvoll anwenden zu können. Offene, komplexe oder langfristig ausgerichtete Aufgaben überfordern klassische RL-Ansätze zumeist. Ein großes aktives Forschungsfeld liegt daher in der Verbesserung der Beobachtungsdarstellungen, der Entwicklung neuer Belohnungsfunktionen und insbesondere in der Lösung der Exploration. Moderne Ansätze untersuchen hier auch die Kombination von Reinforcement Learning mit anderen Lernparadigmen wie Supervised Learning, Offline-RL oder hierarchischen RL-Frameworks, die komplexe Aufgaben in kleinere, handhabbare Teilziele zerlegen sollen.
Gleichzeitig nimmt die Einbindung von multimodalen Inputs und besserer Wahrnehmungssysteme eine zentrale Rolle ein, um die Diskrepanz zwischen Simulation und Realität zu verringern. Trotz dieser Herausforderungen bleibt Reinforcement Learning eine der spannendsten Methoden, um flexibel und autonom intelligentes Verhalten zu entwickeln, speziell in den Bereichen Robotik, autonomes Fahren, Spielintelligenz und auch logikorientierte Aufgaben aus Mathematik und Programmierung. Die Fähigkeit, Lernalgorithmen nicht nur mit großen Datensätzen zu versorgen, sondern ihnen auch eine Art intrinsische Motivation und Selbstverbesserung zu ermöglichen, öffnet immer neue Wege hin zu selbstständigen, adaptiven Maschinen. Für Anwender und Forscher bedeutet das, dass die Wahl von Reinforcement Learning wohlüberlegt sein muss. Die Methode muss zur Aufgabe passen, es braucht realistische Erwartungen an Trainingskosten, Datenzugang und Verifizierbarkeit der Ergebnisse.