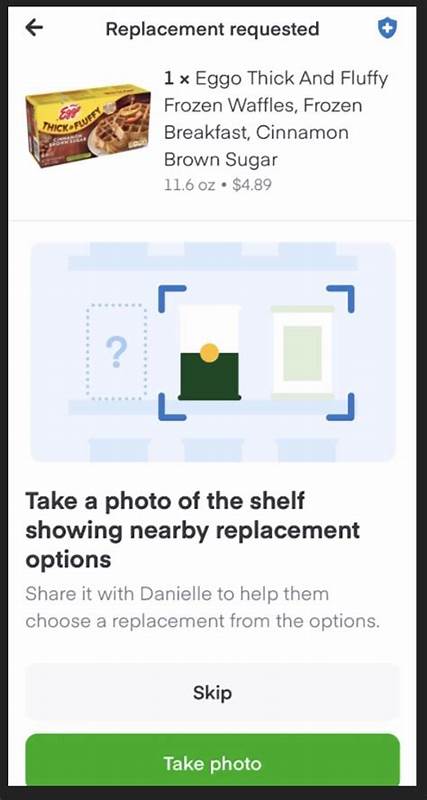
Der Online-Lebensmitteleinzelhandel verändert immer stärker die Art und Weise, wie wir unseren Alltag gestalten. Insbesondere Instacart gilt als treibende Kraft hinter der Digitalisierung von Lebensmittelbestellungen. Doch mit der bequemen Lieferung direkt vor die Haustür gehen auch Herausforderungen einher – etwa wenn Produkte während des Einkaufs ausverkauft sind. An genau diesem Punkt verwandelt Instacart künstliche Intelligenz und maschinelles Lernen in eine Lösung für Kundenunzufriedenheit und operative Komplexitäten. Das Unternehmen hat ein ausgeklügeltes System entwickelt, welches Ersatzprodukte intelligent empfiehlt und so sowohl für Endkunden als auch für die Shop-Mitarbeiter vor Ort optimale Alternativen bereitstellt.
In diesem Beitrag werfen wir einen detaillierten Blick darauf, wie Instacart die Hürden bei Ersatzartikeln mit Machine Learning meistert und damit das Einkaufserlebnis revolutioniert. Vorstellbar ist die Situation vieler Kunden: Man hat seinen Einkaufswagen sorgfältig zusammengestellt, freut sich auf die Lieferung, doch bei der Abholung stellt der Shopper fest, dass einige Produkte vergriffen sind. In früheren Zeiten hätte dies zu erheblichen Unannehmlichkeiten geführt, da Ersatzvorschläge entweder zu unpassend oder gar nicht angeboten wurden. Instacarts Lösung basiert auf einem komplexen maschinellen Lernmodell, das Ersatzprodukte vorschlägt, die nicht nur als ähnlich beurteilt werden, sondern auch die individuellen Präferenzen der Kunden berücksichtigen, um eine hohe Zufriedenheit sicherzustellen. Eine der größten Herausforderungen ist dabei die fehlende Echtzeit-Transparenz der Lagerbestände in den verschiedenen Supermärkten.
Das Modell kann somit nicht in jedem Moment genau wissen, welche Produkte tatsächlich verfügbar sind. Dennoch versucht es, mit intelligenten Vorschlagsmethoden passende Alternativen zu identifizieren, die meist auch vor Ort tatsächlich vorrätig sind. Dabei kommt ein mehrstufiger Prozess zum Einsatz: zunächst wird aus einer großen Anzahl von möglichen Ersatzprodukten eine Vorauswahl getroffen, die auf verschiedenen Kriterien wie Geschmacksprofilen, Markenähnlichkeiten oder sogar der Produktpositionierung im Laden basiert. Für diese sogenannte Candidate-Generation nutzt Instacart eine Mischung aus heuristischen Methoden, welche Historien von vorherigen Ersatzprodukten, Kategoriezugehöreigkeit sowie semantische Ähnlichkeiten zwischen Produktbeschreibungen miteinander vereinen. Dabei wird beispielsweise berücksichtigt, ob ein getrocknetes Blaubeerprodukt als Ersatz für frische Blaubeeren infrage kommt oder ob unterschiedliche Packungsgrößen noch als ähnliche Optionen durchgehen.
Es geht also nicht nur um das gleiche Produkt, sondern um intelligente Alternativen, die den Kundenwünschen möglichst nahekommen. Die technische Schwierigkeit besteht darin, diese Vorauswahl bei einem riesigen Produktkatalog schnell und präzise durchzuführen. Da es zu aufwendig ist, alle möglichen Ersatzpaare völlig zu bewerten, setzen die Algorithmen eine Kombination aus Produktnamen-Schnittmengen und Verkaufszahlen ein, um die relevantesten Kandidaten zu identifizieren. Fasst man den Prozess zusammen, ist über 95 Prozent der tatsächlich genutzten Ersatzartikel in der generierten Kandidatenmenge enthalten. Nach der Vorauswahl folgt die Rangordnung der Ersatzprodukte durch ein tiefgreifendes maschinelles Lernmodell.
Dieses wurde eigens darauf optimiert, die Wahrscheinlichkeit vorherzusagen, mit der Kunden ein vorgeschlagenes Ersatzprodukt tatsächlich annehmen. Es arbeitet mit einem „Siamese Network“, das zwei Produkte gleichzeitig verarbeitet, um Ähnlichkeiten in deren Attributen, Namen und weiteren Eigenschaften zu erfassen. Hier fließen Informationen über Marke, Größe, Einkaufsabteilung und sogar diätetische Merkmale wie vegan oder glutenfrei ein. Die Trainingsdaten stammen aus Kundenreaktionen auf Ersatzvorschläge, wobei positive Beispiele gewählt wurden, wenn der Kunde den Ersatz annahm. Negative Beispiele entstehen durch Produkte, die angezeigt wurden, aber vom Kunden abgelehnt wurden.
Dieses ausgeklügelte System ermöglicht eine stetige Aktualisierung des Modells und verbessert es kontinuierlich anhand neuer Daten und neuer Produkte. Interessanterweise kommen bei häufig gekauften Produkten, den sogenannten Kopf-Produkten, besondere Herausforderungen hinzu. Für diese wurde ein separates Engagement-Modell entwickelt, das auf umfassenden historischen Kundendaten fußt und für beliebte Artikel auf bereits bewährte Ersatzprodukte zurückgreift. Dieses System lernt gewissermaßen aus dem Gedächtnis und kompensiert so die allgemeine Verallgemeinerung des Deep-Learning-Modells. Die Kombination beider Modelle stellt eine ausgeglichene Empfehlung sicher – so wird ein hoher Anteil an Ersatzartikeln empfohlen, die sowohl gut angenommen werden als auch passgenau sind.
Ein wesentlicher Fortschritt ergab sich zudem durch die Integration von Händler-spezifischen Lagerbeständen und Präferenzen. Instacart stellte fest, dass ein einheitliches Modell über alle Händler hinweg zu Verzerrungen führte, die etwa populäre Markenartikel einseitig bevorzugten und damit häufig die exklusiven Produkte einzelner Händler benachteiligten. Die Folge waren unzufriedene Kunden, weil etwa Ersatzprodukte teurer oder für sie unbekannt waren. Durch die Umstellung auf eine modellinterne Berücksichtigung von Händler-IDs wurden Ersatzvorschläge nun an die tatsächlichen Lagerbestände und Präferenzen angepasst. So konnten deutlich mehr passende Ersatzartikel angeboten werden und die Kundenzufriedenheit stieg messbar an.
Statistische Tests bestätigten diese Verbesserungen durch signifikant weniger Ersatzprobleme pro Lieferung. Dieser Schritt ist ein eindrucksvolles Beispiel dafür, wie datengetriebene Individualisierung im E-Commerce konkrete Vorteile bringt. Der Ersatzvorschlag-Prozess ist dabei nur ein Puzzleteil im gesamten Instacart-System, das daneben auch personalisierte Empfehlungen und kontextuelle Anpassungen in der Pipeline hat. Künftige Entwicklungen versprechen noch mehr Innovationen, etwa die Nutzung von Bilddaten zur Ergänzung der Produktsignale oder eine noch tiefere Einbindung langfristiger Kundenpräferenzen und der aktuellen Einkaufssituation. So soll der Ersatzprozess nicht nur effizient, sondern auch emotional positiv wahrgenommen werden – die Frustration durch nicht verfügbare Produkte so gering wie möglich gehalten werden.
Aus Sicht der Nutzer bedeutet das mehr Verlässlichkeit und eine reibungslose, angenehme Bestellung ohne Rätselraten und Überraschungen. Für Instacart ist das ein strategischer Wettbewerbsvorteil auf einem zunehmend umkämpften Markt. Zusammenfassend zeigt das Beispiel Instacart eindrucksvoll, wie Machine Learning und datengetriebene Prozesse essenzielle Herausforderungen im Online-Handel lösen. Die Kombination aus tiefgreifendem technischem Know-how, cleveren Algorithmen und dem Fokus auf Kundenzufriedenheit schafft ein modernes Einkaufserlebnis, das allen Beteiligten zugutekommt. Für alle, die gerne bequem und flexibel Lebensmittel bestellen, ist das ein großer Schritt in Richtung Komfort und Vertrauen.
Wer weiß, vielleicht definieren bald weitere dieser intelligenten Systeme den Standard für digitalen Einzelhandel und machen aus Unsicherheiten rund um Ausverkäufe ein nahtloses Erlebnis. Bis dahin lohnt es sich, die Technik hinter solchen Lösungen zu verstehen – sie zeigt, wie künstliche Intelligenz unseren Alltag sinnvoll und praktisch ergänzt.