In der Welt der Programmiersprachen und der Compilerentwicklung spielt das Parsing eine zentrale Rolle. Parsing beschreibt den Prozess, bei dem Quelltext in eine für den Computer verständliche Struktur, meist einen Syntaxbaum, überführt wird. Unter den verschiedenen Parsing-Techniken nimmt die Top-Down-Operatorpräzedenz, vorgestellt von Vaughan Pratt im Jahr 1973, eine herausragende Stellung ein. Diese Methode verbindet die Eleganz einer rekursiven Abstiegsmethode mit der Effektivität der Operatorpräzedenz und präsentiert sich als einfach zu implementieren, flexibel und leistungsfähig. Trotz ihres Potenzials wird sie in der heutigen Praxis noch immer kaum genutzt, wobei moderne dynamische Sprachen wie JavaScript nun die perfekte Umgebung für ihren Einsatz bieten.
Das Grundprinzip der Top-Down-Operatorpräzedenz beruht darauf, dass jedes Token im Quelltext – seien es Operatoren, Literale oder Bezeichner – als eigenständiges Objekt behandelt wird, das über spezifische Methoden verfügt, um sich selbst zu interpretieren und in den Syntaxbaum einzufügen. Hierbei sind besonders die Methoden nud (null denotation) und led (left denotation) entscheidend. Kräht ein Token zum Beispiel von sich aus etwas über seine Bedeutung ohne Bezug auf ein vorangehendes Token aus, verwendet es die nud-Methode. Umgekehrt nutzt ein Operator, der eine Verknüpfung zwischen einem linken Operand und einem rechten herstellt, die led-Methode. Zusammen mit sogenannten Bindungsstärken (binding powers) wird so festgelegt, wie stark ein Operator mit seinem linken oder rechten Nachbarn verbunden ist – das heißt, wie die Klammerung der Ausdrücke erfolgt.
Eine der größten Herausforderungen beim Parsing ist die richtige Behandlung von Operatorpräzedenz und Assoziativität. Während klassische Methoden wie das Bottom-Up-Parsing mit Lookahead-Mechanismen oder das LL/LR-Parsing durchaus effektiv sind, wirken sie oft umständlich beziehungsweise schwer wartbar, insbesondere wenn man dynamische und erweiterbare Sprachen entwickeln möchte. Pratt's Technik löst diese Probleme elegant, indem sie Operatoren und Bezeichner als Objekte behandelt, die ihre Parsingregeln selbst mitbringen. So entsteht ein flexibles System, in dem neue Operatoren oder Sprachkonstrukte mit minimalem Aufwand hinzugefügt werden können. Ein weiterer Vorteil ist die Effizienz.
Da die Bindungsstärken direkt in den Token-Objekten gespeichert sind, kann der Parser schnell entscheiden, wann er stoppen oder weiter einlesen muss, um die korrekte Struktur zu erfassen. Dieses Vorgehen kombiniert die Einfachheit eines rekursiven Abstiegparsers mit der Leistungsfähigkeit der Operatorpräzedenzgrammatik. Ein Bereich, in dem die Top-Down-Operatorpräzedenz besonders glänzt, ist die Arbeit mit dynamischen Sprachen – also solchen, deren Syntax und Semantik zur Laufzeit erweitert oder verändert werden können. JavaScript etwa ist eine dynamische, funktionale und objektorientierte Sprache mit C-ähnlicher Syntax, die von Haus aus gut auf die Methode von Pratt passt. Douglas Crockford hat 2007 in seinem Kapitel „Top Down Operator Precedence“ aus „Beautiful Code“ eindrucksvoll gezeigt, wie man in JavaScript einen simplifizierten Parser für einen Teil der Sprache erstellen kann, der auf dieser Parsingtechnik basiert.
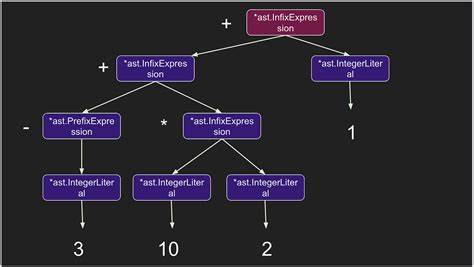
JavaScript profitiert davon, dass seine Tokens als Objekte mit Prototypen existieren und somit direkt aus der Sprachelemente abgeleitet werden können. Symboltabellen werden genutzt, um bekannte Tokens wie Operatoren und Schlüsselwörter zu verwalten. Tokens besitzen Methoden wie nud und led, welche es erlauben, sie beim Einlesen korrekt in den Syntaxbaum einzuordnen. Durch den Einsatz von Bindungsstärken können Konstrukte wie Zuweisungen, Operatoren mit unterschiedlicher Priorität, Funktionsaufrufe, Objektattribute, Schachtelungen und sogar ternäre Operatoren sauber analysiert werden. Der Parser arbeitet dabei in einer Schleife, die zunächst das aktuelle Token mit seiner nud-Methode interpretiert – für Literale, Variablen und Präfixoperatoren – und danach per led-Methode die folgenden Operatoren mit ihren rechten Operanden einbindet, solange deren Bindungsstärke größer als die eingehende ist.
So ergibt sich ein klar strukturierter Baum, der die präzise Hierarchie der Ausdrücke widerspiegelt. Die Einbindung von Scopes (Gültigkeitsbereichen) verleiht dem Parser zusätzliche Fähigkeit zur Semantikprüfung und Namensauflösung. Scope-Objekte können verschachtelt werden und kontrollieren, welche Namen an welcher Stelle gültig sind. Dies erlaubt es, Variablen zu definieren, reservierte Wörter zu behandeln und Konflikte transparent zu machen. Durch die Möglichkeit, eigene Operatoren, Statements und Konstanten über flexible Definitionen hinzuzufügen, wie es im Vortrag von Crockford gezeigt wird, kann die Sprache auf einfache Weise erweitert werden.
Ein Entwickler könnte somit seine eigene DSL (Domain Specific Language) oder Erweiterungen für JavaScript kreieren, ohne komplexe Parsingmechanismen neu erfinden zu müssen. Damit die Parsingtechnik auch Statements und nicht nur Ausdrücke verarbeiten kann, werden Tokens über eine weitere Methode std (statement denotation) ausgestattet. So lassen sich klassische Steuerstrukturen wie if, while, return oder var deklarieren und auswerten. Die Trennung zwischen Ausdruck und Anweisung wird somit sauber abgebildet und erlaubt pragmatische Fehlermeldungen und Kontrollflussbehandlung. Ein besonders gutes Beispiel für die Stärke des Parsers liegt in der Art, wie Funktionen analysiert werden.
Die Parserimplementation erlaubt Funktionsdeklarationen sowohl mit optionalem Namen als auch mit parametrischem Scope und einem Block aus Anweisungen. Die verschachtelte Scope-Verwaltung sorgt dafür, dass Variablen und Parameter korrekt registriert werden, was einer echten Interpretationsumgebung sehr nahe kommt. Die Fähigkeit, Objektnotationen und Array-Literale zu parsen, runden die Anpassungsfähigkeit des Parsers ab. Solche Sprachkonstrukte sind in modernen Web- und Skriptsprachen unverzichtbar und benötigen häufig eine saubere und effiziente Verarbeitung, die hier mit minimalem Aufwand erreicht wird. Trotz dieser vielen Vorteile wurde die Top-Down-Operatorpräzedenz viele Jahre in der praktischen Compilerentwicklung vernachlässigt.
Die Gründe hierfür liegen unter anderem in der damals vorherrschenden Dominanz der BNF-Grammatiken und der damit verbundenen Parsergeneratoren, die Automata-Theorie als Grundlage nutzen. Pratt selbst bemerkte, dass sein Verfahren eher auf dynamische und funktionale Sprachen zugeschnitten ist – also wenig zu klassischen statischen Sprachen passt. Gleichzeitig hatte die Lisp-Community, aus deren Umfeld Pratt’s Ansatz stammt, wenig Interesse an komplexer Syntax, da dort Code und Daten weitgehend identisch sind. Eine reichere Syntax wurde hier immer als unnötig angesehen, was das Interesse an dieser Parsingtechnik ebenfalls dämpfte. Mit dem Aufstieg von JavaScript und ähnlichen dynamischen Sprachen, aber mit der Erwartung einer C-ähnlichen Syntax, ergibt sich heute ein ganz anderes Bild.
Entwickler suchen flexible und erweiterbare Parsingmethoden, die leicht anpassbar sind und trotzdem effizient bleiben. Die Top-Down-Operatorpräzedenz erfüllt diese Anforderungen hervorragend. Zusammengefasst bietet dieses Parsingverfahren eine elegante, performante und intuitive Methode, komplexe Sprachsyntax zu verarbeiten. Es nutzt Objektorientierung und funktionale Programmierprinzipien, um Tokens und Symbole als aktive Teilnehmer des Parsingprozesses einzusetzen. Gerade in modernen JavaScript-Engines und Interpretermodulen könnte es eine Schlüsselrolle spielen.