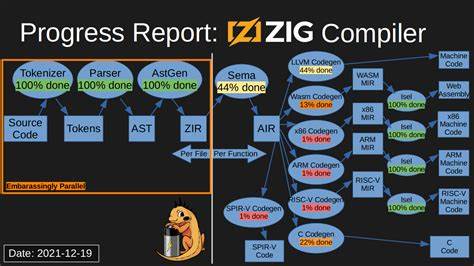
Der Zig Compiler, eine aufstrebende Programmiersprache und Compiler-Infrastruktur, hat in den letzten Jahren durch innovative Ansätze zur Codegenerierung viel Aufmerksamkeit auf sich gezogen. Eines der spannendsten jüngsten Updates betrifft die parallele selbstgehostete Codegenerierung, insbesondere im x86_64 Backend. Diese technische Neuerung hebt nicht nur die Geschwindigkeit des Compilers auf ein neues Leistungsniveau, sondern demonstriert auch den fortschrittlichen Lösungsansatz der Entwicklergemeinschaft, der sich von den konventionellen Methoden vieler etablierter Compiler abhebt. Die parallele selbstgehostete Codegenerierung im Zig Compiler ist eine Antwort auf erhebliche Herausforderungen im Bereich der Compiler-Performance. Traditionell waren viele Compiler-Teilsysteme sequenziell aufgebaut, was bedeutet, dass Codegenerierung und -verarbeitung meist auf einem einzigen Thread ablaufen.
Bei komplexen Architekturen wie x86_64 führt dies zu Engpässen, da die Vielzahl an Instruktionen und Erweiterungen das Codegenerierungsverfahren enorm verlangsamt. Die Entwickler des Zig Compilers haben daher das Ziel verfolgt, maschinenseitige Codeerstellung nicht nur von der semantischen Analyse zu trennen, sondern diese Prozesse parallel ablaufen zu lassen und die Codegenerierung auf mehrere Threads zu verteilen. In der Praxis bedeutet das, dass die Kompilierung in mehrere Phasen unterteilt ist, wobei die semantische Analyse auf einem Thread läuft, mehrere Threads parallel die Codegenerierung übernehmen und ein Linker-Thread am Ende die einzelnen Maschinencodeblöcke zu einem ausführbaren Programm zusammenfügt. Diese Trennung und parallele Ausführung bringen einen erstaunlichen Leistungsschub. Benchmarks zeigen zum Beispiel, dass der Zig Compiler sein eigenes Kompilierungsprojekt mit der neuen Architektur in etwa zehn Sekunden oder weniger fertigstellen kann, was im Vergleich zu vorherigen Versionen eine massive Verkürzung der Kompilierzeit darstellt.
Das Besondere daran ist, dass diese Verbesserungen die von LLVM inspirierte Backend-Technologie nicht betreffen, da LLVM wegen umfangreicher gemeinsamer Zustände und Abhängigkeiten immer noch auf einen einzigen Thread beschränkt bleibt. Die selbstgehosteten Backends von Zig hingegen profitieren erheblich von der Parallelisierung, weil die Codegenerierung für unterschiedliche Module isoliert betrachtet werden kann und somit eine Art „embarrassingly parallel“ Problem vorliegt – ein ideales Szenario für Mehrkernprozessoren. Ein weiterer wichtiger Fortschritt ist die neue Herangehensweise der Maschineninstruktionskodierung. Der Entwickler Jacob Young hat hierzu eine clevere Architektur eingeführt, bei der für die interne Darstellung des Mid-Level Intermediate Representation (MIR) direkt die tatsächliche Maschineninstruktionskodierung verwendet wird. Dies ermöglicht, dass die Codierung von Maschineninstruktionen nicht wie früher sequenziell auf einem Linker-Thread erfolgt, sondern verteilt über mehrere Codegenerierungs-Threads.
Dieser Paradigmenwechsel reduziert Engpässe und beschleunigt die gesamte Pipeline. Darüber hinaus besitzt das neue Backend für Aarch64, welches ebenfalls von Jacob Young entwickelt wurde und Anfang 2025 in den Main Branch aufgenommen wurde, eine signifikant vereinfachte Logik im Vergleich zum bisherigen x86_64 Backend. Es beinhaltet eine eigens angepasste zweiphasige Lebensdauernanalyse, deren zweite Phase zeitgleich den MIR rückwärts generiert. Dieses Verfahren verringert die Anzahl der notwendigen Durchläufe über die Funktionen und macht den Prozess effizienter. Zudem erlaubt es spezielle Backend-Optimierungen hinsichtlich der Lebensdauern von Werten, die vorzeitiges Entfernen nicht nötiger Instruktionen ermöglichen.
Dadurch kann auf hochkomplexes deferred value tracking verzichtet werden, das beim bisherigen x86_64 Backend nötig war. Leistungsbenchmarks untermauern den Erfolg dieses Ansatzes. Beim Kompilieren von einfachen Beispielen wie „Hello World“ verzeichnet Zig dank Parallelisierung und optimierter Backend-Architektur eine Zeitersparnis von über 30 Prozent. Für größere Projekte wie die Kompilierung des Zig Compilers selbst führt die Neustrukturierung zu einem Rückgang der Kompilierungsdauer von 13,8 auf ungefähr 10 Sekunden. Weitere Messungen verdeutlichen außerdem Einsparungen bei CPU-Zyklen, Instruktionsanzahl und Cache-Misses, was insgesamt zu effizienterer Nutzung von Rechenressourcen beiträgt.
Neben der reinen Parallelisierung wird bereits an weiteren Maßnahmen zur Verbesserung der Performance gearbeitet. Beispielsweise sollen gemäß den Entwicklungsankündigungen in Zukunft auch der Linker selbst parallelisiert und die Codeemission weiter optimiert werden. Die Kompression des verbleibenden Arbeiten am sogenannten Flush-Phase am Ende des Kompilationsprozesses soll die letzten Engpässe beseitigen und die gesamte „Build-Kette“ modernisieren. Außerdem ist die integration von inkrementeller Kompilation als langfristiges Ziel im Blick, wodurch nur noch die Teile eines Projektes neu übersetzt werden, die tatsächlich verändert wurden. Dies würde zu extrem kurzen Rebuild-Zeiten – im Millisekundenbereich – bei kleinen Änderungen führen.
Der Fokus der Entwickler liegt aber nicht nur auf der Performance im herkömmlichen Sinne. Gleichermaßen wichtig ist die Qualität des erzeugten Maschinencodes. Während die neue Architektur die Ausführungsgeschwindigkeit des Compilers selbst verbessert, ist es ebenso essenziell, dass die resultierenden Binärdateien in Sachen Geschwindigkeit und Größe überzeugen. Erste Rückmeldungen deuten an, dass die neue Backend-Architektur diesbezüglich vielversprechend ist, auch wenn die vollumfängliche Evaluierung noch aussteht. Verbesserungen bei der Codequalität könnten sogar die Linkzeit weiter verringern, was die Effizienz erneut anhebt.
Ein weiterer spannender Aspekt ist das vollständige Eigenleben des Zig Compilers. Alle aktuellen Backends sind sogenannten „selbstgehostet“. Das bedeutet, dass Zig Compiler-Code, der Maschinencode erzeugt, in Zig selbst geschrieben ist und vom Compiler selbst kompiliert wird. Dieses Vorgehen ermöglicht größere Kontrolle und Flexibilität sowie schnellere Iteration bei der Backend-Entwicklung, indem Abhängigkeiten von externen Tools wie LLVM reduziert werden. Dies ist ein wichtiger Grundstein dafür, dass so ambitionierte Parallelisierungsstrategien umgesetzt werden können.
Zusammen mit anderen technischen Innovationen, wie einer neuen Aarch64-Backend-Implementierung, die weniger Code benötigt und dadurch wartbarer ist, zeigt sich Zig als modernes System, das agil auf die Bedürfnisse moderner Hardware reagiert. Die klar formulierte Roadmap für kommende Schritte verspricht weitere Verbesserungen und eine noch stärkere Fokussierung auf effiziente und schnelle Kompilation. Abseits der technischen Details spiegeln sich die Fortschritte auch in den Metriken wider, die für Entwickler und Unternehmen relevanter denn je sind. Schnellere Kompilierungen bedeuten kürzere Entwicklungszyklen, weniger Wartezeiten und eine höhere Produktivität. Das macht Zig besonders attraktiv für jene, die performant kompilieren wollen, ohne auf die Vorteile einer modernen Sprache verzichten zu müssen.