In der modernen Datenlandschaft wachsen unstrukturierte Daten explosionsartig, und die Methoden zur Analyse stoßen an ihre Grenzen. Bis zum Jahr 2025 wird die Welt voraussichtlich 175 Zettabyte an Daten erzeugen, wobei ungefähr 80 Prozent dieser Daten unstrukturiert sein werden. Trotz dieser enormen Datenmenge werden rund 90 Prozent der unstrukturierten Daten nie ausgewertet. Die traditionelle Suche in Datenbanken mit Methoden wie der Keyword-Suche stößt dabei zunehmend an ihre Grenzen. Die Gründe liegen darin, dass diese Verfahren speziell für strukturierte Daten wie Tabellen mit klar definierten Spalten und Zeilen entwickelt wurden.
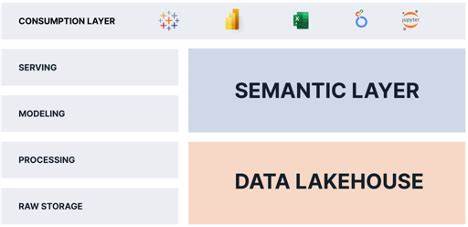
Emojis, unterschiedliche sprachliche Ausdrucksformen, Mehrsprachigkeit oder sogar Paraphrasen bleiben mit herkömmlichen SQL-Befehlen wie LIKE '%price%' unentdeckt. Genau hier setzen Vektor- und semantische Suchverfahren an, die den sogenannten Lakehouse-Ansatz revolutionieren und die Suche innerhalb unstrukturierter Daten grundlegend verändern. Dieser Ansatz ermöglicht es, große Datenmengen lokal zu belassen und direkt aus der Datenplattform heraus zu durchsuchen, ohne aufwendige Datenmigrationen in spezialisierte Silos vorzunehmen. Der Begriff Lakehouse beschreibt eine moderne Datenarchitektur, die die Vorteile von Data Lakes und Data Warehouses kombiniert. In dieser Umgebung werden strukturierte, semi-strukturierte sowie unstrukturierte Daten gemeinsam gespeichert und verarbeitet.
Die Realität zeigt jedoch, dass viele der gespeicherten Daten in einem Lakehouse in Wirklichkeit „Daten-Sümpfe“ sind: große Mengen von Text, Audio, Bildern oder anderen nicht tabellarisch organisierten Informationen, die schwer zu analysieren sind. Textfelder, die zum Beispiel in einer Kundendatenbank als „Customer Notes“ abgelegt sind, enthalten häufig ungeordnete Informationen, die mit klassischen SQL-Werkzeugen kaum nutzbar sind. Sentiment, Intention oder Sarkasmus bleiben dabei unverstanden, weil die semantische Bedeutung des Textes verloren geht. Dies schafft große analoge Blindspots, also Bereich ohne Analysepotenzial, obwohl diese Daten eigentlich wertvolle Einsichten liefern könnten. Die Problematik von traditioneller Keyword-Suche wird besonders deutlich, wenn die Suche nach bestimmten Begriffen oder Phrasen erfolgt.
Dabei wird nur eine Übereinstimmung auf Basis der exakten Token erzielt, nicht jedoch eine Bedeutungserfassung. Ein Suchbegriff wie „Enterprise Plan“ lässt sich oft nicht gut erfassen, da die dahinterliegenden Konzepte wie „Premium-Tarif“, „Garantie auf Verfügbarkeit“ oder „Weißhandschuh-Service“ unter einer anderen Wortwahl verborgen sind. Während eine reine Textsuche strikt nach Wortgleichheit sucht, kann eine semantische Suche genau diesen Zusammenhang durch eine Bedeutungssuche finden. Ähnlich verhält es sich bei Support-Anfragen: Eine Suche nach „refund frustration“ liefert mit einem klassischen System nur die exakten Treffer, während eine semantische Suche auch Tickets mit alternativen Formulierungen wie „mein Produkt entspricht nicht den Erwartungen“ oder „ich möchte mein Geld zurück“ liefert. Der Grund für diese Verbesserung liegt in der sogenannten Vektor-Einbettung, die Texte in hochdimensionale numerische Repräsentationen umwandelt.
Dadurch wird die sprachliche Bedeutung als Geometrie im Vektorraum sichtbar. Methoden wie der Kosinus-Ähnlichkeitswert messen dabei den Winkel zwischen zwei Vektoren. Ein kleiner Winkel bedeutet eine hohe semantische Nähe, unabhängig von der tatsächlichen Wortwahl. Diese Herangehensweise ermöglicht somit auch das Erfassen von Synonymen, Paraphrasen oder mehrsprachigen Ausdrücken, was bei einer klassischen Suchabfrage nicht möglich wäre. Das Lakehouse hat jedoch eine technische Herausforderung: Während analytische Datenbanken auf effiziente Ausführung von Abfragen mit Spalten- und Zeilenfiltern spezialisiert sind, sind sie nicht für die Suche basierend auf Vektorrepräsentationen ausgelegt.
Parallel dazu haben spezialisierte Vektor-Datenbanken zwar schnelle Approximate Nearest Neighbor-Suchen (ANN), jedoch arbeiten sie meist unvermittelt neben OLAP-Systemen. Dadurch entstehen oft mehrere Systeme, zwischen denen Daten kopiert und verschoben werden müssen, was zu Verzögerungen, Kostensteigerungen und Komplexität in Bezug auf Governance und Sicherheit führt. Hier setzt das Konzept der „Unify, Don’t Migrate“ Philosophie an, wie es e6data propagiert. Statt Vektor-Suche in einem eigenen System auszuführen, wird sie direkt in den vorhandenen Query-Optimierer des Lakehouses integriert. So können Vektor-Suchen dieselben Meta-Informationen, Caches, Zugriffsrechte und Analysefunktionen nutzen, die bereits für klassische SQL-Abfragen bestehen.
Die große Stärke dieses Ansatzes liegt darin, dass keine weiteren Datenkopien oder Pipelines erforderlich sind. Rechenleistung und Daten bleiben gut koordiniert beieinander und profitieren von bewährten Technologien für Skalierung, Sicherheit und Verfügbarkeit. Das Ergebnis ist eine Umgebung, in der Entwickler und Analysten SQL-Abfragen schreiben können, die traditionelle Filtermethoden mit Vektor- und semantischen Suchoperationen verbinden. Ein einfaches Beispiel zeigt, wie eine Abfrage nach Bewertungen mit der Phrase „too expensive“ herkömmlich nur wenige genaue Übereinstimmungen liefert. Mit einer Vektor-basierten Suche hingegen werden Tausende ähnlich bedeutender Kommentare gefunden, die ganz andere Formulierungen benutzen, aber von der gleichen Kundenmeinung zeugen.
Das ermöglicht tiefergehende Analysen und ein umfassenderes Kundenverständnis. Technologisch basieren diese Systeme oft auf Modellen wie SBERT oder OpenAI's „text-embedding-3-large“, die Texte in Vektoren mit mehreren hundert oder tausend Dimensionen übersetzen. Um Suchanfragen performant zu gestalten, kommen ANN-Indizes wie HNSW, SCaNN oder DiskANN zum Einsatz, welche sehr effiziente Näherungslösungen für Nachbarschafts-Suchen in hohen Dimensionen bieten. Dies sorgt für schnelle Antwortzeiten selbst bei riesigen Datenmengen. Die Suchabfragen werden dabei idealerweise zuerst durch klassische SQL-Filter vorselektiert, um den Vektorraum auf einen relevanten Bereich zu beschränken.
Insgesamt belegt die Entwicklung im Bereich der semantischen Suche im Lakehouse einen fundamentalen Wandel. Unstrukturierte Daten sind nicht länger eine Randerscheinung, sondern dominieren die Datenhaltung und müssen intelligent nutzbar gemacht werden. Technologien wie Vektor- und semantische Suche erlauben es, aus scheinbar unübersichtlichen Informationsmassen wertvolle Erkenntnisse zu gewinnen, ohne die bestehende Infrastruktur aufzugeben oder Daten mühsam zu kopieren. Damit entstehen neue Möglichkeiten in Bereichen wie Kundenservice, Marketing, Produktentwicklung und Risikomanagement, die semantische Tiefe und Kontext für fundierte Entscheidungen erschließen. Die Zukunft der Datenanalyse wird durch die Verschmelzung von klassischen SQL-Fähigkeiten mit moderner KI-basierter Vektor-Erfassung geprägt sein.