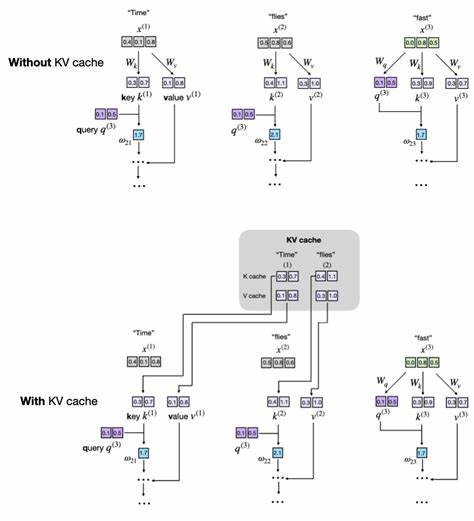
Die rasante Entwicklung von Large Language Models (LLMs) hat die Art und Weise revolutioniert, wie Maschinen natürliche Sprache verstehen und erzeugen. Doch mit wachsender Komplexität der Modelle steigen auch die Anforderungen an Rechenzeit und Speicher. Um effiziente Textgenerierung in produktiven Umgebungen zu gewährleisten, ist der Einsatz von Optimierungstechniken unerlässlich. Eine der effektivsten Methoden, um die Inferenz zu beschleunigen, ist die Implementierung des sogenannten KV Caches – ein Mechanismus, der Schlüssel- und Wertvektoren während des Decode-Prozesses speichert und so redundante Berechnungen vermeidet.Das Funktionsprinzip des KV Caches basiert auf der Architektur des Attention-Mechanismus, der das Herzstück von Transformern und damit von LLMs bildet.
Bei der autoregressiven Textgenerierung wird jeweils ein Token ausgegeben, woraufhin das Modell diesen neuen Eingabetoken zusammen mit vorherigen Tokens neu verarbeitet. Ohne Zwischenspeicherung werden dabei die Schlüssel- (Keys) und Wertvektoren (Values) für alle Tokens jedes Mal erneut berechnet. Dies führt zu einem exponentiellen Aufwand, besonders wenn die Sequenzlänge zunimmt.KV Cache löst dieses Problem, indem es die bereits berechneten Schlüssel- und Wertvektoren zwischenspeichert und bei jedem neuen Generationsschritt nur die Vektoren des zuletzt hinzugefügten Tokens ermittelt. Die so gespeicherten Vektoren werden dann bei der Berechnung der Attention Scores wiederverwendet, wodurch sich viel Rechenzeit einsparen lässt.
Gerade bei längeren Texten oder Echtzeitanwendungen führt das zu signifikanten Beschleunigungen, die für produktive Systeme unverzichtbar sind.Die Implementierung eines KV Caches bringt jedoch auch Herausforderungen mit sich. Einerseits wachsen die Zwischenspeicher mit der Länge der generierten Sequenz linear an, was zu erhöhtem Speicherverbrauch führt. Andererseits erhöht sich die Komplexität im Code, da das Management der gespeicherten Vektoren zuverlässig und synchron zur Textgenerierung erfolgen muss. Während das Caching während des Trainings nicht anwendbar ist, gestaltet es sich bei der Inferenz als äußerst sinnvoll.
Um den KV Cache praktisch umzusetzen, empfiehlt sich eine inkrementelle Vorgehensweise. In einem benutzerfreundlichen Beispiel kann man den Cache als nicht-persistente Puffer in der MultiHeadAttention-Komponente des Modells anlegen. Diese Puffer, beispielsweise mit Namen cache_k und cache_v, speichern die konkatenierten Keys und Values. Ein zusätzlicher Parameter use_cache steuert, ob beim Vorwärtsdurchlauf der Cache genutzt wird oder nicht.Die Logik besteht darin, beim ersten Aufruf die neu berechneten Keys und Values als Cache zu speichern.
Bei nachfolgenden Aufrufen werden diese aus dem Cache geladen und mit den neu berechneten Vektoren der aktuellen Tokens verkettet. Wichtig ist zudem die Möglichkeit, den Cache zurückzusetzen, um Fehlinterpretationen durch veraltete Zwischenspeicher zu vermeiden. So wird bei einem neuen Eingabetext der Cache geleert, bevor die Berechnung beginnt.Damit diese Methodik im gesamten Modell sauber funktioniert, muss der use_cache-Parameter durch alle Schichten propagiert werden. Das umfasst die Transformer-Blöcke und schließlich die gesamte GPT-ähnliche Modelleinheit, die den Fortschritt der bereits verarbeiteten Tokens mittels eines Zählers überwacht.
Dadurch werden die Positions-IDs präzise gesetzt, sodass die Abfragevektoren korrekt zu den gespeicherten Schlüssel- und Wertvektoren passen und keine Überschneidungen auftreten.Die Effekte einer solchen KV Cache-Implementierung sind beeindruckend. Selbst bei einem relativ kleinen Modell mit circa 124 Millionen Parametern kann auf einer CPU eine fünfmal schnellere Textgenerierung beobachtet werden. Diese Verbesserung ist ein überzeugender Beleg dafür, wie wichtige Optimierungen bei der Inferenz im praktischen Einsatz wirken. Allerdings muss angemerkt werden, dass solche Effizienzgewinne auf spezialisierten Hardware-Umgebungen wie GPUs oder mit noch größeren Modellen anders ausfallen können, teilweise wegen des Overheads bei Arbeitsspeichertransfers und Verwaltung.
Neben der Umsetzungslogik ist auch die Frage der Speicherverwaltung entscheidend. Ein direktes Aneinanderhängen der Key- und Value-Tensoren mittels torch.cat führt zu stetigen Neuzuweisungen und Fragmentierungen im Speicher. Für produktiveren Einsatz empfiehlt sich eine vorab reservierte Speicherstruktur, die ausreichend Platz für die maximale Sequenzlänge bereitstellt und während der Textgenerierung nur mit neuen Token-Werten aktualisiert wird. Dieses Vorgehen minimiert den Speicher-Overhead und verbessert die Laufzeitstabilität.
Gleichzeitig sollte der Speicherverbrauch überwacht und kontrolliert werden, beispielsweise durch eine Sliding-Window-Technik, die nur die letzten N Tokens in der Cache-Struktur hält. Damit lässt sich verhindern, dass der Speicher exponentiell mit der Länge des Prompt oder der generierten Sequenz wächst, was besonders bei sehr langen Texten kritisch wird. Natürlich bildet der Kompromiss zwischen Geschwindigkeit und Speicherbedarf dabei eine wichtige Abwägung für Entwickler und Betreiber von LLM-basierten Anwendungen.Das Verständnis des KV Caches ist zudem eng mit einem soliden Grundwissen über Attention-Mechanismen und Transformer-Architekturen verbunden. Wer sich mit der Funktionsweise der Multi-Head Attention, Query-Key-Value-Berechnungen und den zugrundeliegenden Matrizentransformationen auseinandersetzt, kann die Bedeutung und den Nutzen des Zwischenspeicherns besser erfassen.
Die genaue Abstimmung von Dimensionsgrößen, Sequenzlängen und Positions-Embeddings garantiert die Kohärenz der implementierten Lösung.Ein weiterer wichtiger Aspekt ist die Testbarkeit und Validierung der KV Cache-Implementierung. Ein korrekt funktionierender Cache darf keine Abweichungen in der Textgenerierung verursachen, sondern muss exakt das gleiche Ausgabeergebnis wie eine cancel-cached Version des Modells liefern. Fehler bei der Indizierung oder inkonsistente Speicherzustände können zu unerwünschten Texten oder Modellinkohärenz führen. Daher empfiehlt sich ein schrittweises Debugging und Vergleich verschiedener Implementationsstände.
Zusammenfassend lässt sich sagen, dass der KV Cache in Large Language Models ein unverzichtbares Werkzeug für effiziente Textgenerierung darstellt. Durch Speichern und Wiederverwenden von Schlüssel- und Wertvektoren lässt sich die Rechenlast während der Inferenz erheblich reduzieren, die Geschwindigkeit erhöhen und somit sowohl Kosten als auch Latenz verringern. Die Entwicklung einer solchen Implementation erfordert Sorgfalt, insbesondere im Bereich des Speicherhandlings und der Synchronisation mit der Tokenposition.Gerade für Entwickler, die eigene LLM Konzepte ohne externe Bibliotheken bauen oder das Verständnis für Transformer-Mechanismen vertiefen möchten, stellt die von Grund auf geschriebene KV Cache-Lösung einen sehr guten Einstieg dar, der anhand nahbarer Python-Beispiele das Thema greifbar macht. Trotz der Komplexität bieten sich hier spannende Lernmöglichkeiten, die das eigentliche Funktionsprinzip durch einfache Code-Strukturen erläutern.
In der Praxis sind weitere Optimierungen wie Pre-Allocation von Speicher, adaptive Fenstergrößen und Hardware-spezifische Anpassungen sinnvoll, um den KV Cache auch bei großskaligen Modellen und langen Eingaben performant einzusetzen. Dennoch verdeutlicht das Konzept in seiner Grundform bereits die Vorteile von intelligentem Speicher- und Rechenmanagement in modernen KI-Anwendungen.Für technische Führungskräfte und Entwicklerteams ist das Verständnis des KV Caches ein wichtiger Baustein, um Inferenzpipelines zu optimieren und Ressourcen effizient zu nutzen. Vor allem im Bereich der Echtzeitgenerierung von Sprache, Chatbots oder interaktiven Systemen ist eine performante Textausgabe mit minimaler Verzögerung essentiell. Die Implementierung eines KV Caches trägt somit maßgeblich zur Qualität und Skalierbarkeit moderner KI-Produkte bei.
Letztendlich ist KV Cache kein Selbstzweck, sondern ein pragmatischer Ansatz im Engineering von transformerbasierten Modellen, der dabei hilft, die Lücke zwischen theoretischen Modellen und produktiven Systemen zu schließen. Wer die zugrundeliegenden Prinzipien durchdringt und sie in eigenen Projekten anwendet, zeigt Innovation und Effizienzbewusstsein zugleich – zwei Eigenschaften, die in der heutigen KI-Landschaft unverzichtbar sind.