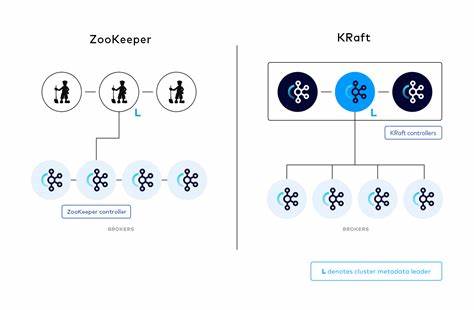
Apache Kafka hat sich in den letzten Jahren als eine der führenden Plattformen für verteilte Streaming-Daten etabliert. Ein wichtiger Meilenstein in seiner Entwicklung ist die Ablösung von ZooKeeper und die Einführung von KRaft – einer integrierten Konsensschicht, die die Steuerung und Verwaltung des Kafka-Clusters übernimmt. Diese neue Architektur verspricht einfachere Betriebsabläufe, geringere Komplexität und verbesserte Performance. Doch wie genau kommunizieren die einzelnen Komponenten in einem Kafka KRaft-Cluster und welche Vorteile bringt der Umstieg mit sich? Kafka war traditionell auf ZooKeeper angewiesen, um Metadaten wie Topic-Konfigurationen, Partitionen und Broker-Registrierungen zu verwalten. ZooKeeper galt lange Zeit als robustes und bewährtes System für verteilte Koordination.
Allerdings brachte die Abhängigkeit auch Herausforderungen bei Installation, Skalierbarkeit und Latenzen mit sich. Die Integration eines eigenen Raft-basierten Kontrollmechanismus, KRaft genannt (Kafka Raft Metadata mode), beseitigt diese Schwächen, indem sie einen dedizierten Satz von Controllern verwendet, die untereinander einen Konsens über die Cluster-Metadaten erzielen. Innerhalb eines KRaft-basierten Kafka-Clusters übernehmen Controller eine zentrale Rolle. Während Broker wie gewohnt als Schnittstelle zu Produzenten und Konsumenten fungieren sowie die Speicherung und Replikation von Nachrichten gewährleisten, sind Controller für das Metadata-Management verantwortlich. Alle Controller bilden einen sogenannten Raft-Quorum, bei dem ein Controller als Leader agiert und die anderen als Follower.
Dieses Quorum ist selbstorganisierend und sorgt dafür, dass selbst im Ausfall einzelner Knoten die Konsistenz und Verfügbarkeit der Metadaten erhalten bleiben. Die Kommunikation zwischen den Controllern folgt dem Raft-Protokoll. Anders als manche vereinfachte Darstellungen vermuten lassen, gibt es keine Push-basierten Metadatenaktualisierungen vom Leader direkt zu den Followern. Stattdessen ziehen die Follower in regelmäßigen Abständen über Pull-basierte FETCH-Anfragen die neuesten Metadaten vom Leader. Dieser Ansatz gewährleistet eine kontrollierte und konsistente Replikation der Daten, die auf bewährten Prinzipien aus dem Raft-Konsensmodell basiert.
Dies bedeutet, dass der Leader als einzige vertrauenswürdige Quelle für den aktuellen Stand der Metadaten dient und Aktualisierungen zunächst in seinem Log geführt werden, bevor sie von den Followern synchronisiert werden. Auf Seite der Broker ist die Kommunikation mit Controllern klar strukturiert: Broker interagieren ausschließlich mit dem aktuellen Controller-Leader. Dieses Modell vereinfacht die Steuerung und minimiert die Komplexität, da Broker keine Logik benötigen, um mit mehreren Controllern gleichzeitig zu kommunizieren. Broker melden sich beim Controller-Leader an und senden kontinuierlich Heartbeat-Nachrichten, um ihre Verfügbarkeit und den Betriebszustand zu signalisieren. Zusätzlich holen Broker aktiv Metadatenupdates vom Leader ab, sodass sie stets auf dem neuesten Stand bezüglich Cluster-Topologie, Partitionenzuweisungen und Konfigurationen sind.
Auch jegliche administrative Anfragen, zum Beispiel die Erstellung neuer Topics oder Änderungen an der Konfiguration, leiten Broker an den Controller weiter. Damit fungieren Broker als Vermittler zwischen Clients und der zentralen Metadata-Instanz. Die Trennung der Rollen von Controllern und Brokern sorgt für eine klare Verantwortlichkeit und verbessert die Skalierbarkeit und Ausfallsicherheit des Kafka-Clusters. Obwohl in Test- und Entwicklungsumgebungen ein einzelner Server sowohl als Broker als auch als Controller fungieren kann, empfiehlt sich für produktive Setups die dedizierte Trennung, um Performance-Engpässe zu vermeiden und eine robuste Fehlerisolierung zu gewährleisten. Neben der internen Steuerkommunikation kann Kafka auch direkt Daten unter Brokern replizieren.
Die Replikation erfolgt durch Pull-basierte FETCH-Anfragen, bei denen Replikanten regelmäßig den Zustand der primären Partition abrufen, um eine hohe Verfügbarkeit und Datensicherheit zu gewährleisten. Dieses Prinzip passt zur grundsätzlichen Philosophie von Kafka, Kontrolle und Konsistenz dezentral, aber mit klar definierten Verantwortlichkeiten zu organisieren. Ein wichtiger Punkt für Administratoren ist die Behandlung administrativer Operationen. Wenn ein Client etwa ein neues Topic anlegt, läuft der Request zunächst über einen Broker. Der Broker leitet die Anfrage an den Controller-Leader weiter, der die Metadaten entsprechend anpasst, Partitionen zuweist und Replikationsfaktoren berücksichtigt.
Nach erfolgreicher Verarbeitung aktualisiert der Controller-Leader sein Metadaten-Log, woraufhin Broker die neuen Informationen bei ihren regelmäßigen FETCH-Anfragen beziehen. Dadurch ist sichergestellt, dass die Cluster-Konfiguration immer konsistent und aktuell bleibt. Die Einführung von KRaft in Kafka bringt zahlreiche Vorteile mit sich. Zum einen entfallen die Abhängigkeiten von ZooKeeper, was die Installation vereinfacht und Wartungsaufwand reduziert. Zum anderen ermöglicht das Raft-Protokoll eine bessere Fehlertoleranz durch schnelle Leader-Wahlen und ein stärkeres konsistentes Zustandsmanagement.
Dies führt insgesamt zu einer stabileren und leichter zu skalierenden Kafka-Infrastruktur, die vor allem bei großen und dynamischen Umgebungen klare Vorzüge bietet. Um die interne Kommunikation und das Verhalten des Clusters besser zu verstehen, lohnt sich das Experimentieren mit einem eigenen KRaft-Cluster, beispielsweise in einer containerisierten Umgebung mit Docker Compose. Durch das Anpassen der Logging-Konfiguration lassen sich detaillierte Einblicke in Controller- und Broker-Transaktionen gewinnen, etwa die Registrierung von Brokern, Heartbeat-Zyklen und Metadaten-Fetch-Prozesse. Diese direkten Beobachtungen bestätigen die pull-basierten Kommunikationsmuster und verdeutlichen den genauen Ablauf administrativer Vorgänge. Auch wenn KRaft gegenüber ZooKeeper noch jung ist, gewinnt es zunehmend an Reife und findet in neuen Kafka-Versionen immer breitere Anwendung.
Entwickler und Systemadministratoren profitieren von einer stabileren Basis, die speziell auf die Anforderungen moderner Streaming- und Event-Processing-Szenarien zugeschnitten ist. Kafka in KRaft-Modus zu betreiben bedeutet für Unternehmen eine Zukunftssicherheit bei der Plattformwahl. Die klare Trennung von Metadatenverwaltung und Nachrichtenverarbeitung erlaubt es, einzelne Komponenten gezielt weiterzuentwickeln und auf Skalierung zu trimmen. Gleichzeitig reduziert die native Integration des Raft-Konsensprotokolls die Komplexität und potenzielle Fehlerquellen, die bisher durch die ZooKeeper-Abhängigkeit entstanden sind. Abschließend lässt sich festhalten, dass Kafka KRaft durch seine moderne Architektur und konsistente Kommunikationsmuster eine zeitgemäße Lösung für hochverfügbare und skalierbare Streaming-Plattformen darstellt.
Die pull-basierte Synchronisation, klare Rollentrennung und der Verzicht auf externe Koordinierungsdienste schaffen eine solide Grundlage für die nächsten Generationen verteilter Dateninfrastrukturen. Für alle, die KDE-basiertes Kafka einsetzen oder planen, bietet sich die Beschäftigung mit KRaft als lohnenswerter Schritt, um die Vorteile einer schlüssigen und leistungsfähigen Clusterverwaltung voll auszunutzen.