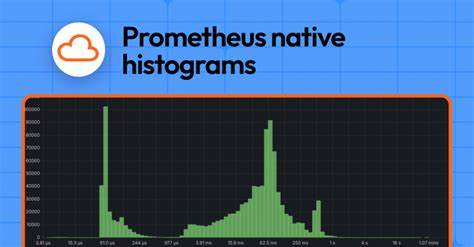
In der heutigen digitalen Welt, in der Systeme immer komplexer und datenintensiver werden, ist die zuverlässige Überwachung von Metriken essenziell, um Betriebsstabilität zu gewährleisten und Ausfallzeiten zu minimieren. Eine zentrale Herausforderung dabei ist die effiziente und skalierbare Anomalieerkennung — also das Erkennen untypischer Abweichungen in Metriken, die auf Probleme oder Ausfälle hinweisen können. Prometheus, ein weit verbreitetes Open-Source-Monitoring-System, bietet hierfür dank seiner flexiblen Abfragesprache PromQL und der Möglichkeit, individuelle Recording- und Alerting-Regeln zu erstellen, exzellente Voraussetzungen. Doch wie gelingt es, Prometheus so einzusetzen, dass Anomalien bei großen Datenmengen präzise und ressourcenschonend erkannt werden? Dieser Beitrag beleuchtet praxisnah Strategien und Frameworks für die Anomalieerkennung mit Prometheus im großen Maßstab.Der Ausgangspunkt für eine zuverlässige Anomalieerkennung ist die Definition eines baselinemodells, woran sich Anomalien messen lassen.
Im Falle von Prometheus wird hierfür häufig mit statistischen Methoden gearbeitet, die auf den historischen Messwerten der Metriken basieren. Ein bewährter Ansatz beruht auf der Verwendung des gleitenden Mittelwerts (Moving Average) als Referenzlinie und der Berechnung der Standardabweichung zur Festlegung von Vertrauens- oder Bandbreiten. Werte, die außerhalb dieser definierten Bänder liegen, werden als mögliche Anomalien interpretiert.Die Grundformel hierfür ist inspiriert vom z-Score und lautet im Wesentlichen: Mittelwert plus/minus das Vielfache der Standardabweichung, wobei diese Bänder dynamisch anhand der vergangenen Messwerte berechnet werden. Um dies mit Prometheus abzubilden, werden Recording Rules eingesetzt, die diese Berechnungen automatisch ausführen.
Eine praktische Wahl zur Berechnung des Mittelwerts ist ein einstündiges Zeitfenster, das ausreichend aktuelle Daten einbezieht und dennoch kurzfristige Entwicklungen erkennen lässt. Für die Standardabweichung bietet es sich an, einen größeren Zeitraum zu wählen, etwa 26 Stunden, um auch tägliche Schwankungen und saisonale Effekte abzudecken und somit robustere Grenzen zu schaffen.Ein wichtiger Parameter in der Formel ist der Multiplikator der Standardabweichung. Er beeinflusst die Empfindlichkeit des Systems: Ein höherer Wert führt zu breiteren Bändern, was weniger False Positives zur Folge hat, aber riskieren kann, echte Anomalien zu übersehen. Ein niedrigerer Wert erhöht die Sensitivität, birgt jedoch die Gefahr von Fehlalarmen.
In der Praxis hat sich ein Multiplikator von zwei als guter Kompromiss bewährt. Das Ganze lässt sich in Prometheus mittels einer Recording Rule abbilden, die den oberen Schwellenwert berechnet, etwa indem der Mittelwert mit dem zweifachen Wert der Standardabweichung addiert wird.Die praktische Anwendung dieses einfachen Modells bringt jedoch typische Herausforderungen mit sich, die in produktiven Umgebungen aufgetreten sind und kreative Lösungen erforderten. Eine dieser Herausforderungen sind extreme Ausreißer, durch die sich die Standardabweichung stark erhöht und die Bänder unkontrolliert ausweiten können. Infolgedessen lassen sich echte Anomalien kaum noch unterscheiden, weil das System ständig zu tolerant wird.
Hier wurde erfolgreich eine Glättungsfunktion eingeführt, die eben diese Extremwerte abfedert und so für stabilere Grenzen sorgt. Das geschieht durch eine zusätzliche Glättung der Standardabweichung über ein längeres Zeitfenster. Auf diese Weise bleibt das System sowohl sensitiv als auch robust gegenüber kurzzeitigen Spitzen.Eine weitere Schwierigkeit betrifft Phasen mit geringer Varianz. Wenn die Standardabweichung nahe null ist, werden die Bänder so eng, dass selbst kleinere Abweichungen sofort als Anomalien gewertet werden.
Das führt zu einer Flut von Fehlalarmen. Um dem entgegenzuwirken, wurde ein Filter implementiert, der Perioden mit minimaler Variabilität erkennt und diese aus der Berechnung herausnimmt. Dies erfolgt über einen Schwellenwert, der dynamisch an den beobachteten Mittelwert angepasst wird und statistisch durch den sogenannten Variationskoeffizienten skaliert wird. Dadurch passt sich die Sensitivität automatisch an die Größe und Schwankungsbreite der einzelnen Metriken an.Stabilität bei langfristigen Mustern und saisonalen Schwankungen ist eine weitere kritische Anforderung.
Cronjobs, tägliche Lastspitzen oder wiederkehrende Prozesse führen zu regelmäßigen, vorhersehbaren Ausschlägen, die nicht als Anomalien klassifiziert werden sollten. Hier wird in Prometheus mit Offset-Abfragen gearbeitet, die die Werte zu vergleichbaren Zeitpunkten in der Vergangenheit heranziehen, um die Bänder präventiv anzupassen. So können Anomalien rechtzeitig erkannt werden, ohne Fehlalarme wegen erwarteter Spitzen auszulösen. Diese zeitversetzten Abfragen erhöhen die Aussagekraft der Baseline und schaffen eine zuverlässige Grundlage für nachhaltiges Monitoring.Eine besonders elegante Lösung ist die Kombination mehrerer Bänder, um unterschiedliche Aspekte der Datenvariabilität abzudecken.
Zum Beispiel ein Band, das auf dem Mittelwert und einem konstanten Mindestabstand basiert, garantiert eine minimale Empfindlichkeitsschwelle. Daneben wirkt ein Band, das dynamisch über Standardabweichung und Glättung definiert wird. Das System wertet dann immer das Maximum der Bandschwellen als echten Grenzwert für Anomalien, was eine adaptive und flexible Erkennung ermöglicht.Für die praktische Nutzung in der eigenen Infrastruktur ist es wichtig, diese Recording Rules in Prometheus zu implementieren und die Metriken entsprechend mit Labels zu versehen, die den Typ der Metrik wie Latenz, Fehler oder Anfrageart identifizieren. Das erlaubt eine einfache Zuordnung und Verwaltung der Anomalieerkennung in vielfältigen Umgebungen.
Viele Werkzeuge, wie Grafana, können diese Daten visualisieren und mit Alerting-Regeln verknüpfen, sodass Benachrichtigungen bei Überschreitung der Schwellenwerte automatisiert erfolgen.Unternehmen, die mit Multi-Tenant- oder sehr großem Monitoring-Setup arbeiten, profitieren besonders von dieser methodisch fundierten Lösung. Da sie vollständig auf PromQL basiert und ohne externe Systeme arbeitet, ist sie performant, wartbar und skalierbar. Durch den Verzicht auf zusätzliche Werkzeuge lassen sich Betriebskosten senken, und die Integration in bestehende Prometheus-basierte Systeme gestaltet sich unkompliziert.Zusätzlich ermöglicht die offene Verfügbarkeit des Frameworks in Form von GitHub-Repositorien den direkten Einstieg.
Die Community kann von vorgefertigten Dashboards, Alerting Regeln und Beispiel-Setups profitieren und die Lösung an spezifische Anforderungen anpassen. Zudem lädt die aktive Community zum Erfahrungsaustausch ein, wodurch Best Practices schneller etabliert werden. Die Integration mit Tools wie Grafana Cloud ermöglicht eine umfassende observability-Plattform, die neben Metriken auch Logs, Traces und Profildaten zusammenführt und so die Anomalieanalyse mit Kontext versorgt.Es ist jedoch wichtig, Anomalieerkennung nicht als alleiniges Mittel zur Überwachung zu betrachten. Das Erkennen eines Ausreißers ist ein Indiz, ersetzt aber keine auf den Geschäftsanforderungen basierenden Service-Level-Objectives (SLOs).
Die Anomalieerkennung sollte vielmehr als ein Baustein in einem ganzheitlichen Monitoring- und Incident-Response-Prozess gesehen werden. So können auftretende Anomalien mit SLO-basierten Alerts verknüpft werden, um die Dringlichkeit und Schwere von Problemen besser einzuschätzen und gezielter zu reagieren.Zusammenfassend lässt sich sagen, dass Prometheus, unterstützt durch intelligentes Design von Aufzeichnungs- und Alarmregeln, eine leistungsstarke Plattform für die Anomalieerkennung bietet. Die Kombination aus statistischer Modellierung, dynamischer Anpassung und Skalierbarkeit macht es möglich, große Mengen an Monitoring-Daten effizient zu analysieren und echte Probleme schnell zu identifizieren. Organisationen, die diesen Ansatz verfolgen, schaffen die Voraussetzung für eine proaktive Fehlererkennung, die Ausfallzeiten reduziert und die Zuverlässigkeit ihrer Systeme nachhaltig verbessert.
Die stete Weiterentwicklung dieser Lösungen und die Einbindung neuer Techniken wie maschinelles Lernen werden in Zukunft weitere Fortschritte in der Anomalieerkennung bei großem Maßstab bringen. Gleichzeitig sind bewährte Verfahren, wie in diesem Framework beschrieben, eine solide Basis, um heute schon wertvollen Mehrwert aus den gesammelten Metriken zu ziehen und die Kontrolle über komplexe IT-Umgebungen sicherzustellen.


![Transportation Means on Mars [video]](/images/3E328360-9572-4ACB-873F-0C3E85ED7188)