Radix Sort stellt eine fundamentale Methode zur Sortierung großer Datenmengen auf GPUs dar und zeichnet sich durch seine Nicht-Vergleichsbasiertheit aus. Insbesondere bei diskreten Schlüsseln wie Integern, Zeichenketten oder sogar Gleitkommazahlen bietet Radix Sort eine effiziente Lösung, die bei ausreichend großen Datenvolumen meist schneller als klassische Vergleichsalgorithmen arbeitet. Es wird häufig in Anwendungen verwendet, die schnelle und zuverlässige Sortierungen benötigen, darunter beispielsweise die Konstruktion von spatialen Datenstrukturen oder Datenvorverarbeitungen in Computergraphik und Machine Learning. Maximale Performance und geringe Latenzzeiten sind hier besonders von Bedeutung, weshalb die Optimierung von GPU-Implementierungen zunehmend an Relevanz gewinnt. Grundlegend basiert Radix Sort auf der Idee, die zu sortierenden Schlüssel in einzelne Ziffern oder Bitgruppen zu unterteilen.
Durch sukzessives Sortieren von der niederwertigsten zur höchstwertigen Ziffer und der stabilen Wiedergabe der relativen Reihenfolge gleicher Werte lässt sich eine gesamte Sortierung mit mehrfachen Durchläufen elegant realisieren. Auf GPUs verläuft dieser Prozess oft in drei Kernschritten: der Zählung der Schlüsselwerte (Histogramm), dem Prefix-Scan zur Berechnung von Offsets und schließlich dem Umordnen der Daten nach den berechneten Positionen. Das Hauptproblem traditioneller GPU-Radix-Sortierungen ist jedoch die ineffiziente Nutzung des globalen Speichers. Eingabedaten werden meist mehrfach gelesen, etwa einmal beim Zählen der Bucketbelegungen und nochmals beim Reorganisieren der Schlüssel. Solche wiederholten Zugriffe auf den Speicher erhöhen die Latenz und schmälern die Gesamtperformance erheblich.
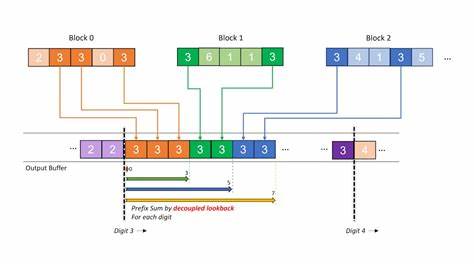
Während zusätliche Kernel-Kombinationen theoretisch den Speicherbedarf verringern können, sind diese schwer umzusetzen und oft mit komplexem Synchronisationsaufwand verbunden. Eine wesentliche Innovation zur Überwindung dieser Limitierungen ist die Entwicklung des Onesweep-Algorithmus, der die Zähl- und Umordnungsschritte intelligent zusammenführt und so den mehrfachen Speicherzugriff eliminiert. Der Kern dieses Verfahrens ist der decoupled look-back Mechanismus, der effiziente und weniger latenzbehaftete Prefix-Scans ermöglicht. Anstelle eines strikt sequentiellen Abwartens auf vorgelagerte Blöcke, können GPU-Einheiten ihre Vorläuferstatus asynchron abfragen und akkumulieren, was eine parallele Berechnung des kumulativen Offsets stark beschleunigt. Dennoch bringt der Einsatz von Onesweep eine Herausforderung mit sich: Der temporäre Speicherbedarf skaliert proportional mit der Anzahl der zu sortierenden Elemente, was bei großen Datensätzen zu einem erheblichen Overhead führt.
Hier setzt die nachfolgende Optimierung an: Durch Verwendung eines konstant großen zirkulären Puffers (Circular Buffer) lässt sich die temporäre Speicherbelegung deutlich effizienter gestalten und vom Input-Volumen entkoppeln. Ein Tail-Iterator verwaltet dabei geschickt den Bereich des Puffers, der aktuell nicht von den GPU-Blöcken zur look-back Operation genutzt wird, sodass Speicherbereiche sicher überschrieben werden können, ohne Konflikte zu erzeugen. Diese Architektur verhindert explizite Abhängigkeiten von der Eingabedatenmenge und schafft eine skalierbare, speichereffiziente Lösung. Die Implementierung eines solchen Circular Buffers erfordert detailliertes Management der Blockstatusinformationen. Neben der bloßen Summe pro GPU-Block ist zu speichern, ob ein lokaler oder prefix-Scan-Wert verfügbar ist, um korrekte Synchronisation zu gewährleisten.
Ein 64-Bit-Datentyp erlaubt die Kombination dieser Werte und deren atomare Aktualisierung innerhalb einer Instruktion, was die Konsistenz trotz paralleler Zugriffe sicherstellt. Hierbei ist der Gebrauch von Volatile-Qualifizierern unverzichtbar, um Speicheroperationen nicht durch Compiler-Optimierungen zu entfernen oder zu verzögern. Der Mehrwert dieser Vorgehensweise manifestiert sich in einer stark verringerten Speicherbandbreitennutzung. Während klassische Radix-Sort-Durchläufe typischerweise mehrfach dieselben Inputs vom globalen Speicher laden, wird bei Onesweep mit Circular Buffer nur einmal auf die Schlüssel zugegriffen, was die Zahl der Speicheroperationen von 3n auf knapp 2n (bei n Elementen) reduziert. Hinzu kommt die Verkürzung der Kernelstarts, da neben einer effizienten Prefix-Scan-Optimierung auch der Reorder-Schritt in dieselbe Ausführungseinheit integriert wird.
Weitere Performance-Verbesserungen werden durch lokale Sortierstrategien innerhalb der GPU-Blöcke erzielt. Dabei erfolgt eine feinkörnige Aufteilung der Daten auf Subgruppen, die in Zusammenarbeit eine klassische Radix-Sortierung durchführen. Dies ermöglicht besser genutzte Speicherzugriffe innerhalb der Shared Memorys und minimiert Divergenzen im Thread-Scheduling. Dabei gilt es, das Gleichgewicht zwischen parallelisierter Arbeitsteilung und Überkopf durch serielle Teilschritte zu wahren – gerade bei der lokalen Histogrammermittlung und Offset-Berechnung treten potenzielle Engpässe auf. Im Vergleich zu früheren Methoden zeigt die Kombination von Onesweep mit Circular Buffer-Techniken erhebliche Geschwindigkeitsvorteile in realen Anwendungsszenarien.
Für Entwickler bedeutet dies, dass komplexe Sortiervorgänge in Echtzeit-Rendering-Systemen, Datenanalyse-Engines oder physikbasierten Simulationen effizienter ausgeführt werden können. Die Reduktion des Speicherverbrauchs und der globale Speicherzugriffe trägt zudem zu einer besseren Energieeffizienz bei, was sich gerade in mobilen oder energie-sensiblen Systemen bezahlt macht. Dennoch sind auch Grenzen der aktuellen Implementierungen zu beachten. Beispielsweise ist die Verwaltung des Circular Buffers und die korrekte Synchronisation bei extrem großen oder verteilten Daten noch verbesserungswürdig. Fragile spin-wait Schleifen können in Konkurrenzsituationen zu Warteschleifen führen, deren Optimierung noch Forschungspotenzial bietet.
Ebenso kann die Sortierung von kleineren Datenarrays durch die aktuell für große Workloads optimierte Architektur nicht immer optimal dargestellt werden. Hier eröffnen sich Anknüpfungspunkte für künftige Entwicklungen. Zusammenfassend lässt sich festhalten, dass die Weiterentwicklung von GPU-basierten Radix Sort-Algorithmen durch den Einsatz von Onesweep und zirkulären Puffern einen signifikanten Schritt in Richtung effizientere Verarbeitung großer Datenmengen darstellt. Durch das Minimieren von Wiederholzugriffen auf den globalen Speicher und cleveres Buffer Management kann die GPU-Pipeline besser ausgelastet werden. Dies führt zu niedrigeren Latenzzeiten, erhöhter Geschwindigkeit und geringeren Speicherkosten bei der Sortierung, was gerade im Zeitalter wachsender Datenmengen eine essenzielle Grundlage darstellt.
Die Kombination aus algorithmischer Innovation, Speicheroptimierung und praktischer GPU-Programmierung zeigt eindrucksvoll, wie komplexe Berechnungsprobleme durch gezielte Maßnahmen effektiv gelöst werden können und damit moderne Anwendungen in Bildverarbeitung, Simulation und Datenanalyse nachhaltig profitierten.