Programmiersprachen haben sich seit den Anfängen der Computertechnik kontinuierlich weiterentwickelt. Dabei zeigt sich ein bemerkenswerter Trend: Viele der neuen oder verbesserten Sprachen verzichten bewusst auf bestimmte Features, die früher als notwendig galten. Die Erkenntnis dahinter ist klar – weniger ist oft mehr. Das bedeutet konkret, dass durch das Weglassen redundanter oder problematischer Sprachfeatures die Qualität von Programmen steigt, die Fehlerrate sinkt und Entwickler leichter verständlichen Code schreiben können. Zu Beginn der Computerära war Programmieren eine äußerst komplexe und fehleranfällige Tätigkeit.
Programme wurden in Maschinen- oder Assemblersprache geschrieben, wo jede einzelne Anweisung direkt auf den Prozessor zugeschnitten war. Zwar konnten so alle möglichen Anweisungen ausgeführt werden, doch die Fehleranfälligkeit war immens. Entwickler mussten praktisch unendlich viele Wege kennen, wie ein Programm inkorrekt sein konnte – von einfachen Syntaxfehlern bis hin zu schwerwiegenden Systemabstürzen. Das führte schnell zu der Einsicht, dass Abstraktion notwendig ist, um den Entwicklungsprozess sicherer und effizienter zu gestalten. Die Einführung höherer Programmiersprachen stellte einen gewaltigen Fortschritt dar.
Sprachen wie C ermöglichten es, komplexe Logiken auf einem höheren Abstraktionsniveau auszudrücken. Dabei ging der radikale Schritt einher, nicht mehr jede Art von Maschinenbefehl direkt auszusprechen, sondern nur noch sinnvolle, validierte Anweisungen zuzulassen. Dies bedeutete, dass trotz der potenziellen Einschränkung des Ausdrucksspektrums das Programmieren deutlich sicherer und übersichtlicher wurde. Es gab weniger Möglichkeiten, versehentlich unbrauchbaren oder schädlichen Code zu schreiben. Die Wahl, nicht alle Maschinenbefehle direkt verfügbar zu machen, hob die Wahrscheinlichkeit eines Fehlers erheblich.
Ein historisch und kulturprägender Meilenstein in dieser Debatte war Edsger Dijkstra mit seinem Aufsatz "Go To Statement Considered Harmful" im Jahr 1968. Er stellte die These auf, dass das GOTO-Statement, welches aus jedem Punkt im Programm an einen beliebigen anderen springen kann, nicht nur die Lesbarkeit erschwert, sondern auch einen massiven Fehlerquell darstellt. Die darauf folgende Diskussion führte dazu, dass moderne Programmiersprachen wie Java oder JavaScript heute komplett auf GOTO verzichten. Interessanterweise konnten alle gültigen und sinnvollen Programme auch ohne dieses Feature ausgedrückt werden. Die Entfernung dieses Features schränkte also nicht die Ausdrucksfähigkeit ein, sondern reduzierte die Komplexität und Fehleranfälligkeit des Codes.
Dieses Prinzip zieht sich wie ein roter Faden durch verschiedene Language-Design-Entscheidungen. So sind heute Funktionen zur Fehlerbehandlung wie Exceptions weit verbreitet. Sie sollen gegenüber alten Fehlercodemustern Vorteile bieten. Doch auch Exceptions sind im Kern nichts anderes als versteckte Sprungbefehle, vergleichbar mit GOTO, die Fehler in einen besonderen Kontrollfluss zwingen. Kritiker argumentieren, dass diese Form der Fehlerbehandlung zu unübersichtlichen und schwer nachvollziehbaren Programmen führen kann.
Ein moderner Ansatz ist stattdessen die Nutzung sogenannter Summentypen, die Erfolge und Fehler als Teil eines konsistenten Typsystems abbilden. Dieser Ansatz ist composable und vermeidet implizite Kontrollflussbrüche, was die Lesbarkeit und Wartbarkeit verbessert. Ein weiterer kritischer Punkt sind Zeiger, wie sie in älteren Sprachen wie C und C++ vorzufinden sind. Zeiger ermöglichen direkte Manipulationen am Speicher, was hohe Flexibilität bietet, aber auch eine Vielzahl an Fehlern einschleust – unter anderem Speicherlecks und unkontrollierte Zugriffe. Moderne Sprachen verzichten ganz oder teilweise auf Rohzeiger beziehungsweise kapseln deren Funktionalität.
Java und JavaScript etwa arbeiten komplett ohne Zeiger, C# erlaubt sie zwar theoretisch, aber typischerweise sind sie nicht notwendig. Stattdessen werden Referenzen und Wertübergaben abstrahiert, was ähnliche Funktionalitäten ermöglicht, jedoch mit deutlich weniger Risiken. Auch die Vielfalt der numerischen Datentypen wird in der komplexen Softwarentwicklung zunehmend kritisch betrachtet. Während in frühen Computerzeiten die Auswahl an beispielsweise 8-Bit-, 16-Bit- oder Gleitkommatypen technisch notwendig war, sind solche Detailoptimierungen auf heutigen Systemen meist überflüssig. Entwickler verlieren oft Zeit damit, den passenden numerischen Datentyp zu finden, was sich langfristig negativ auf die Produktivität auswirkt.
Sprachen wie JavaScript sind ein Beispiel für einen radikalen Ansatz: Sie nutzen nur einen einzigen Zahlentyp. Obwohl JavaScript in dieser Hinsicht nicht perfekt ist, zeigt das Konzept, wie Vereinfachung zu einem klareren und leichter verständlichen Code führen kann. Ein besonders verbreitetes und schwieriges Problem sind Nullwerte. Tony Hoare bezeichnete Nullzeiger als seine "Milliarden-Dollar-Fehler". Das Konzept, dass ein Wert entweder vorhanden oder nicht vorhanden sein kann, ist durchaus sinnvoll und in funktionalen Sprachen wie Haskell und F# als Option oder Maybe etabliert.
Entscheidend ist, dass Nullable-Werte explizit und nicht standardmäßig erlaubt sind. Bei Sprachen wie Java oder C# hingegen kann praktisch jede Referenz null sein, was zu einer Vielzahl von Fehlern führt. Die bewusste Vermeidung von Nullzeigern reduziert Defekte enorm und verbessert die Programmsicherheit. Mutation, also das Verändern von Variablenwerten während der Programmausführung, ist eine weitere Quelle zahlreicher Fehler. Obwohl es ursprünglich sehr natürlich erschien, weil Computerregister dynamisch Daten verändern, erschwert dies das Nachvollziehen von Programmlogik erheblich.
In großen Systemen mit vielen Variablen und komplexen Methodenaufrufen ist es schwierig festzustellen, wann welcher Zustand sich geändert hat. Sprachen wie Haskell zeigen, dass auch komplexe Programme ohne implizite Zustandsänderungen auskommen können. Dieser Paradigmenwechsel verlangt zwar eine gewisse Umstellung, führt aber zu sichererem und besser wartbarem Code. Gleiches gilt für das Konzept der Referenzgleichheit, das in objektorientierten Sprachen wie C# und Java üblich ist. Ob zwei Variablen gleich sind, hängt häufig davon ab, ob sie auf dieselbe Speicheradresse zeigen, nicht ob sie dieselben Werte enthalten.
Das ist oft kontraintuitiv und führt nicht selten zu Fehlern. Würde man stattdessen strukturelle Gleichheit als Standard nehmen und Referenzgleichheit nur für Spezialfälle anbieten, könnte man viele dieser Probleme vermeiden. Vererbung ist ein weiteres Sprachfeature, das bislang als Herzstück objektorientierter Programmierung galt, heute aber oft kritisch hinterfragt wird. Schon die Gang of Four empfahlen, Komposition der Vererbung vorzuziehen, da Komposition vielseitiger ist und flexiblere Strukturen ermöglicht. Tatsächlich lässt sich in vielen Projekten ganz auf Vererbung verzichten und stattdessen mit Interfaces oder Funktionen arbeiten.
Das Ergebnis sind oft modularere und besser testbare Programme. Interfaces bieten in stark typisierten Sprachen Möglichkeiten zur Polymorphie. Doch auch hier zeigt sich, dass Single-Member-Interfaces, also solche mit nur einer operationellen Methode, oft vollständig durch Funktionen oder Delegates ersetzt werden können, was den Code klarer und schlanker macht. Funktionale Sprachen sind hier seit jeher Vorreiter, was zeigt, dass man sehr viel mit einfachen funktionalen Bausteinen ausdrücken kann. Reflection, also das Inspektieren und Manipulieren von Programmcode zur Laufzeit, ist ein mächtiges Werkzeug für Meta-Programmierung.
Doch es ist auch eine komplexe und potenziell unsichere Funktion. In homoikonischen Sprachen – in denen Programme als Datenstrukturen vorliegen – brauchen Entwickler oft kein Reflection, da sich der Code auf natürliche Weise analysieren und ändern lässt. Reflection wird somit als redundantes Feature angesehen, wenn die Sprache selbst Metaprogrammierung von Grund auf unterstützt. Auch zyklische Abhängigkeiten zwischen Modulen oder Klassen werden als Problem erkannt. Sprachen wie C# und Java erlauben solche Zyklen oft unbewusst und führen so zu starkem Kopplungsverhalten, das die Wartbarkeit massiv erschwert.
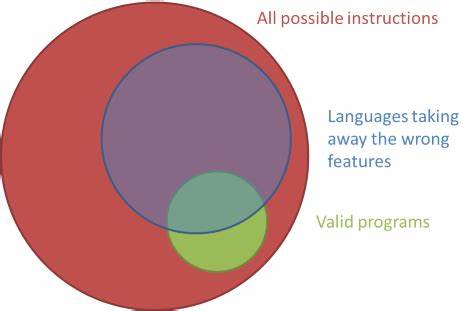
Sprachen wie F# gehen einen anderen Weg und verbieten zyklische Abhängigkeiten auf Modulebene strikt, was zu klareren, entspannteren Abhängigkeitsstrukturen führt. Das gemeinsame Prinzip hinter all diesen Beispielen ist eindeutig. Durch das Entfernen problematischer Features entsteht ein sichereres und übersichtlicheres System. Es geht dabei nicht darum, die Ausdruckskraft der Sprache einzuschränken oder vollständige Programme unmöglich zu machen. Im Gegenteil, es geht darum, Sprache so zu gestalten, dass nur sinnvoller und fehlerarmer Code entstehen kann und unnötige Fehlerquellen gar nicht erst existieren.
Der Ausspruch von Antoine de Saint Exupéry bringt es auf den Punkt: "Perfektion ist erreicht, nicht wenn man nichts mehr hinzufügen kann, sondern wenn man nichts mehr weglassen kann." Natürlich ist diese Reduktion kein Selbstzweck. Es ist entscheidend, die richtigen Features zu entfernen, nicht wahllos. Einige Sprachfeatures können in bestimmten Kontexten unverzichtbar sein oder besondere Aufgaben erleichtern. Dennoch sollte jedes neue Sprachdesign hinterfragen, ob ein Feature wirklich notwendig ist oder vermieden werden kann, weil es eher Probleme schafft als löst.
Der ideale Weg führt zu einer Sprache, die Turing-vollständig ist und nahezu beliebige Programme ausdrücken kann, aber gleichzeitig menschliche Fehlerquellen minimiert. Solch eine Sprache verzichtet auf GOTO, Exceptions, rohe Zeiger, unnötig viele Zahlentypen, Nullwerte als Standard, implizite Mutation, Referenzgleichheit als Standard, klassische Vererbung, übermäßige Interfaces, Reflection zur Laufzeit und zyklische Abhängigkeiten. Die Zukunft der Programmiersprachen könnte also darin liegen, immer mehr dieser problematischen Features zu entfernen und dafür einfache, klare Alternativen anzubieten. Es wird dabei weiterhin verschiedene Sprachen geben, die jeweils Spezialfälle abdecken und unterschiedliche Ansätze verfolgen – denn nicht jede Sprache ist für jedes Problem optimal. Doch der Trend zu minimalistischeren, klarer strukturierten und dadurch sichereren Sprachen wird sich fortsetzen.
Für Entwickler bedeutet dieses Wissen, dass es sinnvoll ist, neue Sprachparadigmen offen anzunehmen und sich auch mit funktionaler Programmierung, Immutability und starken Typensystemen auseinanderzusetzen. Dies führt nicht nur zu robusterem Code, sondern fördert auch ein besseres Verständnis der zugrunde liegenden Softwarestrukturen. Insgesamt zeigt sich: Weniger Sprachfeatures bedeuten nicht weniger Möglichkeiten, sondern mehr Klarheit, weniger Fehler und nachhaltigere Softwareentwicklung. Das Konzept von "Less is more" im Bereich der Programmiersprachen ist also kein Trend, sondern eine notwendige Entwicklung hin zu besseren Werkzeugen für Softwareentwickler weltweit.