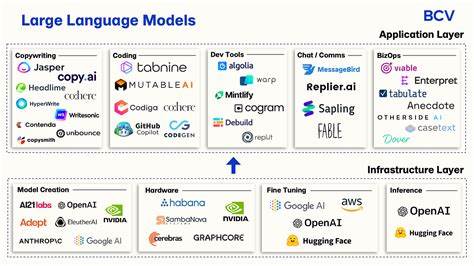
In den letzten Jahren haben große Sprachmodelle (Large Language Models, kurz LLMs) die Aufmerksamkeit in der Softwareentwicklung massiv auf sich gezogen. Mit Versprechen von enormer Produktivitätssteigerung bis hin zum automatischen Schreiben von Code wirken sie auf den ersten Blick wie ein Werkzeug, das Entwicklern die Arbeit revolutionär erleichtern könnte. Doch wie so oft stecken hinter dem Hype auch realistische Herausforderungen, die viele erfahrene Entwickler zögern lassen, sich vollkommen auf diese Technologien einzulassen. Viele Entwickler berichten von einer zwiegespaltenen Erfahrung im Umgang mit LLMs. Im Alltag sind die Modelle durchaus hilfreich, wenn es darum geht, einfache oder klar umrissene Aufgaben zu bewältigen.
Das Erstellen von Boilerplate-Code, kleine Skripts oder die Beantwortung von Fragen zu Importstrukturen oder Fehlermeldungen sind typische Beispiele, bei denen LLMs schnell und zuverlässig unterstützen können. Für weniger erfahrene Programmierer oder bei wenig vertrauten Technologien stellen sie eine Art Produktivitäts-Booster oder Lernhilfe dar, indem sie Informationen schneller zugänglich machen und mühsames Nachschlagen in Dokumentationen reduzieren. Die Grenzen beginnen dort, wo Projekte größer, komplexer und hochgradig spezifisch werden. Die Herausforderung vieler Entwickler liegt genau in diesem Bereich: komplexe Features implementieren, bestehende Systeme warten oder erweitern, die Domäne und die vielfältigen Abhängigkeiten im Blick behalten. Hier offenbart sich, warum die von manchen propagierte hundertfach höhere Produktivität oft unerreichbar bleibt.
Das Modell liefert zwar funktionierenden Code in Teilen, doch der Aufwand, diesen so anzupassen und zu iterieren, dass er den eigenen hohen Erwartungen an Wartbarkeit und Qualität genügt, ist häufig höher als es den Code selbst zu schreiben. Entscheidend für die Effektivität eines LLM in der Programmierung ist das „Kontext“-Management. Softwareprojekte bestehen aus zahllosen Dateien, Bibliotheken und Modulen, die miteinander verflochten sind. LLMs haben jedoch eine begrenzte Kontextgröße, also nur eine beschränkte Anzahl an Tokens oder Zeilen „merken“ sie sich in einem einzelnen Verarbeitungsschritt. Große Codebasen können so nur fragmentarisch gewertet werden, was dazu führt, dass wichtige Abhängigkeiten übersehen werden oder der Kontext bruchstückhaft bleibt.
Dieses Problem wird besonders spürbar, wenn Änderungen an umfangreichen Projekten umgesetzt werden sollen, bei denen eine Änderung tiefgreifende Auswirkungen haben kann. Entwickler berichten davon, dass sie LLMs oftmals „babysitten“ müssen, weil das Modell nicht automatisch versteht, welche Teile bereits erledigt sind, welche Funktionen ausgelassen wurden oder warum bestimmte Refaktorierungen vorzuziehen sind. Die Auseinandersetzungen in Entwickler-Communitys zeigen auch, dass Entwickler verschiedene Herangehensweisen und Erwartungen an KI-gestützte Programmierung haben. Die einen sehen LLMs als „Junior-Entwickler“ mit durchwachsenen Fähigkeiten, die zwar erste brauchbare Ergebnisse liefern, jedoch ständige Überwachung und Korrektur benötigen. Andere sind davon überzeugt, dass der Schlüssel zum Erfolg in der Kombination von richtigem Tooling, präzisen Prompts und einer neuen Art des Projektmanagements liegt.
Hier wird empfohlen, die Arbeit in sehr kleine Aufgaben zu unterteilen, sogenannte „Tasks“ und Umsetzungspläne mit der KI zu erarbeiten oder maßgeschneiderte „Regel-Dateien“ für das Verhalten der Modelle zu entwickeln. So lässt sich das LLM an die Besonderheiten des Projekts anpassen, und man kann zumindest teilweise den Prozess automatisieren. Doch auch mit optimaler Vorbereitung stoßen die meisten Entwickler noch auf spürbare Einschränkungen bei der Codequalität, dem Erkennen von Randfällen oder bei Sicherheitsüberlegungen. Es fehlt die echte „Agent-Fähigkeit“ – also die in sich geschlossene Kompetenz, selbstständig Zusammenhänge zu interpretieren, Lösungen zu hinterfragen oder komplexe Projekte ganzheitlich zu betreuen. Oftmals werden Funktionen oder Bibliotheken erfunden, die gar nicht existieren („Halluzinationen“).
Auch die Wiedererkennung von bereits geschriebenem Code, um ihn konsistent zu erweitern, funktioniert selten zuverlässig, was zu redundanten oder gar widersprüchlichen Änderungen führen kann. Das erhöht den Korrekturaufwand drastisch. Für viele etablierte Entwickler ist zudem der Aspekt der „Code-Eigentümerschaft“ und Verantwortung ein Hemmschuh. Sie sind es gewohnt, transparent nachvollziehbaren und wohldokumentierten Code zu schreiben, der sie selbst oder das Team langfristig nicht belastet. Code, der „nur funktioniert“ und als Zwischenprodukt gilt, ist oft nicht ausreichend.
LLM-Code, der aufgrund seines inkonsistenten Stils, fehlender Tests oder fehlender Architekturprinzipien wenig Vertrauen erzeugt, wird daher abgelehnt oder nur als erste Referenz genutzt. Interessanterweise setzen Startups und Solo-Entwickler LLMs gezielter ein, etwa um schnell erste Prototypen zu erstellen oder wiederkehrende, monotone Aufgaben zu delegieren. Sie passen ihre Arbeitsweise ganz bewusst an den LLM-Einsatz an. Dazu gehören eine modulare Architektur, eine klare Dokumentation als Grundlage und ein rigider Testprozess. So wird der LLM zu einer Art Mitentwickler, der bei eng gesteuerten Aufgabenteilen Verantwortung für den Code übernehmen kann.
Hier verspüren diese Nutzer bereits einen echten Produktivitätsgewinn, da sie selbst nicht alle Details selbst implementieren müssen und iterative Anpassungen effizienter über das LLM-Tooling erfolgen. Die Debatte um den Wert von LLMs in der Programmierung ist weiterhin sehr lebhaft. Einige Entwicklergruppen sind begeistert von den Fortschritten und sehen in LLMs Werkzeuge, die vor allem den Einstieg in neue Technologien erleichtern, den Umgang mit langweiligen Aufgaben optimieren und als hilfreicher Diskussionspartner beim Debugging fungieren. Andere bleiben skeptisch, zweifeln an der Nachhaltigkeit des Produktivitätsgewinns und weisen darauf hin, dass LLMs bisher zu oft mehr Zeit kosten, als sie einsparen, insbesondere bei anspruchsvoller Entwicklung. Eine häufig gestellte Frage lautet deshalb, ob der wahre Nutzen von LLMs gerade in der „kleinen Hilfe“ und „geduldigen Intelligenz“ liegt, nicht aber in der vollständigen Automatisierung von komplexen Entwicklungsprozessen.
Nicht zu vergessen ist die Rolle des passenden Modells und der eingesetzten Plattform. Weltweit entwickeln Unternehmen neuere und spezialisiertere LLMs, die sich in Qualität, Geschwindigkeit und Kontexthandhabung unterscheiden. Die Wahl des richtigen Modells für den jeweiligen Anwendungsfall ist für die täglichen Ergebnisse entscheidend. Bei einfachen Aufgaben reichen oft kostengünstige Modelle, während komplexere Vorhaben qualitativ hochwertige, leistungsstarke Modelle benötigen. Auch Trainingsdaten, die speziell auf firmeneigene Quellcodes oder Domänen zugeschnitten sind, können die Leistungsfähigkeit verbessern.
Aktuelle Entwicklungen gehen deshalb dahin, hybride Architekturen einzusetzen, die eine spezialisierte Suche, intelligente Kontextfilterung und fein abgestimmte Prompts kombinieren. Langfristig wird die Leistungsfähigkeit von LLMs durch den Ausbau des Kontextverständnisses und die Integration von Code-Analyse-Tools und Tests stetig wachsen. Konzeptionen wie mehrstufige Agentensysteme, die intelligent zwischen verschiedenen Abstraktionsebenen eines Softwareprojekts wechseln und aktiv selbständig ihre Arbeitsweise anpassen können, sind Gegenstand intensiver Forschung. Bis dahin gilt es für Entwickler, geduldig zu sein, LLMs als zusätzliche Assistenz im Alltag zu betrachten und die Möglichkeiten bewusst und kontrolliert einzusetzen. Die größte Herausforderung bei der Nutzung von LLMs in der Programmierung ist somit nicht die Technik allein, sondern auch eine Anpassung der eigenen Arbeitsweise, ein realistisches Erwartungsmanagement und ein gezieltes Zusammenspiel zwischen Mensch und Maschine.
Nur so können Entwickler echten Mehrwert aus den neuen Tools schöpfen und den Übergang zu einer produktiveren, von KI unterstützten Softwareentwicklung nachhaltig gestalten.