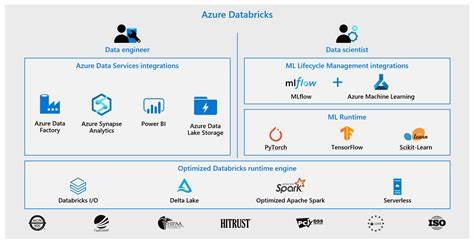
Azure Databricks hat sich als eine der führenden Plattformen für Big Data-Analyse und maschinelles Lernen etabliert. Unternehmen weltweit nutzen die leistungsfähigen Funktionen der Plattform, um Daten in Echtzeit zu verarbeiten, zu analysieren und Modelle zu trainieren. Umso gravierender sind Ausfälle wie jener, der am 28. Mai 2025 im Azure-Rechenzentrum UK South aufgetreten ist. Zwischen 09:54 UTC und 12:35 UTC kämpften viele Nutzer mit eingeschränktem Zugriff auf die Workspace-Oberfläche sowie die REST-APIs von Azure Databricks.
Laufende Jobs konnten nicht termingerecht abgeschlossen werden, was weitreichende Folgen für Unternehmen im Vereinigten Königreich und darüber hinaus hatte. Die Ursachen des Ausfalls lagen zum Teil in der zugrundeliegenden Infrastruktur, die durch den Cloud-Anbieter bereitgestellt wird. Bereits während der Störungsmeldung wurde kommuniziert, dass Azure Databricks eng mit seinem Cloud-Provider zusammenarbeitet, um geeignete Maßnahmen zur Fehlerbehebung umzusetzen. Die Komplexität der Plattform, die Komponenten wie Compute, Databricks SQL, Lakeflow, Mosaic AI, Notebooks und Unity Catalog umfasst, macht eine rasche Fehleranalyse anspruchsvoll, da zahlreiche Systeme voneinander abhängig sind. Betroffene Nutzer berichteten von Problemen mit der Benutzeroberfläche, die den regulären Zugriff auf analytische Arbeitsbereiche verunmöglichten.
Ebenso war die Nutzung der REST-APIs eingeschränkt, was Auswirkungen auf automatisierte Workflows und Integrationen hatte. Besonders kritisch war die Verzögerung und teilweise das Ausbleiben der Ausführung laufender Jobs. Unternehmen, die auf Echtzeit-Analytik und Datenpipelines angewiesen sind, mussten alternative Strategien einsetzen, um ihre Datenverarbeitungsszenarien aufrechtzuerhalten. Die Störung veranschaulicht die Herausforderungen, die moderne Cloud-gestützte Datenplattformen mit sich bringen. Trotz hoher Verfügbarkeit und Skalierbarkeit begünstigen externe Abhängigkeiten und komplexe Systemarchitekturen das Risiko von temporären Dienstunterbrechungen.
Für Unternehmen ist es deshalb essentiell, sowohl die Vorteile von Plattformen wie Azure Databricks zu nutzen als auch Pläne für den Umgang mit potenziellen Ausfällen zu entwickeln. Ein wichtiger Aspekt ist die Überwachung und Früherkennung von Unregelmäßigkeiten. Durch den Einsatz von Monitoring-Tools können Administratoren und Dateningenieure Störungen zeitnah erkennen und gegebenenfalls Gegenmaßnahmen einleiten, bevor es zu gravierenden Ausfällen kommt. In Kombination mit automatisierten Alarmsystemen lässt sich eine schnelle Reaktionszeit realisieren. Darüber hinaus empfiehlt es sich, robuste Backup- und Wiederherstellungsstrategien zu implementieren.
Daten und Konfigurationen sollten regelmäßig gesichert werden, um bei einem Ausfall Datenverlust zu minimieren und die Wiederaufnahme der Arbeit zu beschleunigen. Auch die Nutzung mehrerer Regionen oder Clouds kann eine Ausfallsicherheit erhöhen. Die Verteilung von kritischen Workloads auf unterschiedliche geografische Standorte verursacht zwar zusätzlichen Aufwand, bietet aber einen effektiven Schutz vor lokalen Infrastrukturproblemen. Das Ereignis im Rechenzentrum UK South zeigt zudem, wie wichtig eine transparente Kommunikation seitens der Plattformanbieter ist. Die Nutzer wurden während des Vorfalls mehrfach informiert – von der ersten Identifikation über die laufende Überwachung bis zur finalen Behebung und Statusmeldung.
Solche Updates erhöhen das Vertrauen der Kunden und helfen ihnen, ihre eigenen Ressourcen besser zu koordinieren. Neben technischen Lösungen müssen Unternehmen auch organisatorische Maßnahmen ergreifen. Die Schulung von Mitarbeitern im Umgang mit Störungen und die Entwicklung eines Incident-Response-Plans sind hierbei zentral. Ein klar definiertes Verfahren stellt sicher, dass im Ernstfall Verantwortlichkeiten schnell zugewiesen und Entscheidungen rasch getroffen werden können. Azure Databricks bietet eine hochmoderne Umgebung für die Datenanalyse.
Dennoch ist kein System vollkommen vor Störungen geschützt. Der Vorfall vom Mai 2025 im UK South Rechenzentrum erinnert daran, dass eine ganzheitliche Strategie, die sowohl technische als auch organisatorische Aspekte berücksichtigt, entscheidend ist, um die Auswirkungen von Ausfällen zu minimieren. Für Anwender empfiehlt es sich, die Architektur ihrer Lösungen regelmäßig zu überprüfen und gegebenenfalls anzupassen, um Redundanzen zu schaffen. Ebenso wichtig ist die Evaluierung alternativer Anbieter oder Multi-Cloud-Strategien. So können Abhängigkeiten von einzelnen Infrastrukturen reduziert werden.
Abschließend lässt sich sagen, dass der Ausfall von Azure Databricks im UK South Rechenzentrum ein mahnendes Beispiel für die Herausforderungen im Cloud-Zeitalter ist. Unternehmen müssen wachsam bleiben, um von den Vorteilen moderner Datenplattformen zu profitieren und gleichzeitig auf unerwartete Ereignisse vorbereitet zu sein. Die Kombination aus technischer Vorsorge, guter Planung und transparenter Kommunikation bildet die Basis für eine widerstandsfähige Dateninfrastruktur. Die Lehren aus diesem Vorfall bieten wertvolle Ansatzpunkte, um künftig besser auf ähnliche Situationen reagieren zu können und die digitale Transformation sicher voranzutreiben.