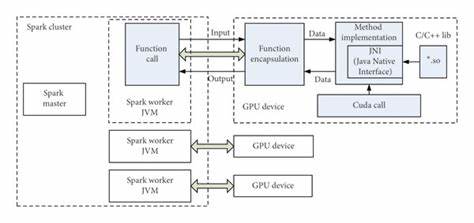
In der heutigen datengetriebenen Welt stehen Unternehmen vor der Herausforderung, immer größere Datenmengen effizient und kostengünstig zu verarbeiten. Traditionelle Ansätze stoßen hier zunehmend an ihre Grenzen, sei es in puncto Geschwindigkeit oder Kosten. Genau an diesem Punkt setzt ParaQuery an – eine innovative, vollständig verwaltete Plattform, die auf GPU-beschleunigtem Spark und SQL basiert und damit eine neue Ära der Big-Data-Verarbeitung einläutet. ParaQuery wurde im Rahmen des renommierten Y Combinator Accelerators (Batch X25) ins Leben gerufen und verspricht neben einer einfachen Bedienung vor allem erhebliche Leistungssteigerungen und Kosteneinsparungen gegenüber etablierten Lösungen wie Google BigQuery. Die Kombination aus GPU-Beschleunigung mit bewährten Spark- und SQL-Technologien bildet das Fundament für eine skalierbare und performante Datenplattform, die besonders für Startups und Unternehmen mit umfangreichen ETL-Workloads interessant ist.
Die technologische Basis von ParaQuery beruht auf modernen Grafikprozessoren (GPUs), die ursprünglich vor allem aus dem Bereich der Grafikdarstellung und KI bekannt sind. In den letzten Jahren hat sich jedoch gezeigt, dass GPUs mit ihren massiven parallelen Rechenkernen und dem hohen Speicherbandbreitenpotenzial ideal für datenintensive Workloads geeignet sind. Insbesondere bei Spark- und SQL-Abfragen mit großem Durchsatz können GPUs durch ihre Architektur deutliche Geschwindigkeitsvorteile bieten. NVIDIA hat mit dem RAPIDS-Programm und dem Spark-RAPIDS-Plugin früh erkannt, dass GPUs das Potenzial besitzen, die Datenverarbeitung effizienter zu gestalten. ParaQuery setzt genau auf diese Technologie auf, erweitert sie jedoch durch eine vollständig verwaltete Cloud-Lösung, die Nutzer von den komplexen Aufgaben der Infrastrukturverwaltung befreit.
So entfällt etwa die aufwändige Handhabung von GPU-Instanzen, Spark-Optimierungen oder die Einrichtung und Wartung spezieller Shuffle-Services – alles erfolgt automatisiert und transparent für den Anwender. Ein wichtiger Vorteil von ParaQuery ist die vollständige Kompatibilität zu Spark SQL. Das bedeutet, bestehende Workflows und Abfragen können ohne aufwändigen Migrationsaufwand genutzt werden. Unternehmen müssen also keine Anpassungen am Datenmodell oder an der Abfragesyntax vornehmen, sondern profitieren direkt von den Vorteilen der GPU-Beschleunigung. Diese nahtlose Kompatibilität ist kein Selbstverständnis, da die genaue Nachbildung der gewohnten Spark-Verhalten aufgrund verschiedener Floating-Point-Implementationen und Sonderfällen in Spark eine Herausforderung darstellt.
Im Praxiseinsatz zeigt ParaQuery beeindruckende Ergebnisse: In einem vorgestellten Benchmark konnte ein ETL-Job, der auf BigQuery 44 Minuten benötigte, mit ParaQuery in etwa 5,5 Minuten erledigt werden. Das entspricht einer etwa achtfachen Geschwindigkeit und ist dabei auch noch kosteneffizienter, da Kunden im realen Betrieb laut Aussagen des Gründers über 60 Prozent ihrer bisherigen BigQuery-Kosten einsparen konnten. Diese Kombination aus Performance und Kosteneinsparung macht das Angebot gerade für Unternehmen mit großen Datenmengen und aufwändigen Transformationsprozessen attraktiv. Ein Kritikpunkt, der häufig bei GPU-Lösungen geäußert wird, betrifft die vermeintlichen Engpässe beim Datentransfer zwischen CPU, GPU und Speichersystemen – vor allem wenn die Daten in Cloud-Objektspeichern wie Google Cloud Storage (GCS) liegen. ParaQuery entkräftet diesen Einwand mit der technischen Ausgestaltung des Systems.
Trotz der Tatsache, dass CPUs die Daten erst vom Storage holen und zu den GPUs transferieren, liegt die Bandbreite zwischen CPU und GPU so hoch, dass sie in der Praxis selten zum Flaschenhals wird. Auch der Shuffle-Prozess, bei dem große Datenmengen zwischen Rechenknoten ausgetauscht werden, wird intelligent optimiert, um Engpässe zu vermeiden. Dies gelingt unter anderem durch den Einsatz externer Shuffle-Services, die auch Spot-Instances effizient nutzbar machen. Abgesehen von Performance und Kosten ist die Benutzerfreundlichkeit ein wesentlicher Faktor. Während reine Spark-RAPIDS-Setups eine hohe Expertise in der Verwaltung von Cluster-Infrastrukturen, GPU-Konfigurationen und Spark-Tuning erfordern, bietet ParaQuery eine vollständig verwaltete Lösung.
Diese eliminiert viele Komplexitäten, mit denen Entwickler und Dateningenieure sonst konfrontiert sind. Die Plattform strebt dabei an, BigQuery in Sachen Bedienkomfort mindestens zu erreichen, bietet jedoch deutliche Vorteile hinsichtlich Kosten und Geschwindigkeit. Die Zukunft der Datenverarbeitung liegt laut ParaQuery-Gründer Win Wang in der Kombination aus hochparalleler Hardware und skalierbaren Cloud-Services. GPUs bieten ein enormes Potenzial für Workloads mit hohem Datenvolumen und komplexen Transformationen, da sie dank ihrer Architektur besonders für Bandbreiten-intensive Operationen geeignet sind. Darüber hinaus führt die kontinuierliche Verbreitung von GPU-basierten Cloud-Instanzen dazu, dass die Technologie immer verfügbarer und somit für mehr Unternehmen zugänglich wird.
Neben der Verbesserung der Hardware-Performance arbeitet ParaQuery auch an der Softwareseite, um Kompatibilität und Effizienz weiter zu erhöhen. Beispielsweise ist die Unterstützung für mehrspaltige User-Defined Functions (UDFs) geplant, die derzeit noch schwierig auf GPUs beschleunigt werden können. Hier sind anspruchsvolle Compiler-Techniken gefragt, um die Potenziale voll auszuschöpfen. Im Wettbewerb mit anderen Spielern im Bereich GPU-beschleunigter Datenplattformen hebt sich ParaQuery durch den Fokus auf Spark-Kompatibilität und einfache Bedienbarkeit ab. Während einige Projekte auf proprietäre Engines oder fragmentierte Ökosysteme setzen, bleibt ParaQuery bei bewährten Standards und ermöglicht so eine schnelle Integration und Migration.
Interessant ist auch die mögliche Ausweitung der GPU-Beschleunigung auf verschiedene Hardware-Anbieter. Während NVIDIA momentan marktführend mit CUDA und RAPIDS ist, schreitet die Entwicklung bei AMD und anderen Herstellern voran. ParaQuery plant, durch Open-Source-Beiträge und die Nutzung von Hardware-Abstraktionsschichten wie HIP eine plattformunabhängige Lösung anzubieten, die auch alternative GPU-Architekturen unterstützt. Insgesamt zeigt das Konzept von ParaQuery, wie sich moderne Hardwaretechnologien mit Cloud-Infrastruktur und bewährten Big-Data-Frameworks zu einer leistungsfähigen und wirtschaftlichen Lösung verknüpfen lassen. Für Unternehmen mit anspruchsvollen Datenanforderungen bietet das Potenzial, ETL-Prozesse drastisch zu beschleunigen und gleichzeitig Kosten signifikant zu senken.
Abschließend lässt sich festhalten, dass der Markt für Big-Data-Analytik weiterhin dynamisch ist und GPU-Beschleunigung zunehmend an Bedeutung gewinnen wird. ParaQuery steht hierbei beispielhaft für eine neue Generation von Datenplattformen, die Leistung, Einfachheit und Kosteneffizienz miteinander verbinden und so den Umgang mit Daten für Unternehmen aller Größenordnungen neu definieren können. Mit innovativen Ansätzen zur Nutzung hochparalleler Hardware und intelligentem Cloud-Management ist ParaQuery ein spannender Trendsetter auf dem Weg in die Zukunft moderner Datenverarbeitung.