Wikipedia gehört zu den umfangreichsten und dynamischsten Wissensquellen im Internet. Für viele Nutzer, Forscher oder Entwickler stellt sich jedoch die Frage, wie sie die riesigen Datenmengen der Wikipedia effizient herunterladen und offline nutzen können. Das Herunterladen der Wikipedia-Datenbank bietet den Vorteil, unabhängig von einer Internetverbindung auf die gesamte Wissensbasis zugreifen zu können. Dies ist besonders wertvoll für Forschung, Bildung oder den Aufbau eigener Anwendungen. Doch die Größe und Komplexität der Daten stellt zugleich eine Herausforderung dar, die mit einigen technischen Hürden verbunden ist.
Im Folgenden werden wichtige Aspekte, Methoden und Tipps erläutert, die den Download sowie die Nutzung der Wikipedia-Datenbank erleichtern. Wikipedia-Dumps: Was steckt dahinter? Die Wikimedia Foundation stellt sogenannte Dumps zur Verfügung. Diese Daten-Dumps sind Archivdateien, die den gesamten Inhalt eines Wikimedia-Projekts zum Zeitpunkt der Erstellung enthalten. Sie beinhalten alle Wikipedia-Artikel, aber auch Metadaten wie z.B.
Versionsverläufe und Verlinkungen. Für die englischsprachige Wikipedia sind die Dumps besonders umfangreich und können mehrere Terabyte umfassen, weshalb es wichtig ist, sich vorher genau zu überlegen, welche Dateien tatsächlich benötigt werden. Es gibt verschiedene Typen von Dumps. Zum Beispiel enthält ein pages-articles-Multistream-Dump nur die aktuellen Versionen der Artikel ohne Diskussions- und Benutzerseiten. Diese sind besonders beliebt, da sie einerseits eine aktuelle und saubere Datenbasis liefern und andererseits verhältnismäßig wenig Speicherplatz benötigen, verglichen mit kompletten Revisionshistorien.
Die Multistream-Version hat den großen Vorteil, dass man mit ihr gezielt einzelne Artikel herunterladen kann, ohne die gesamte Datei entpacken zu müssen. Für Nutzer, die bestimmte Daten analysieren oder offline lesen wollen, ist das immens hilfreich. Verfügbare Formate und deren Bedeutung Die Dumps werden in unterschiedlichen Formaten angeboten. Hauptsächlich finden sich XML-Dateien, die den wikicode in komprimierter Form enthalten, sowie SQL-Dateien, die für die direkte Einspielung in Datenbanksysteme wie MySQL gedacht sind. Für einzelne Zwecke sind die XML-Dumps besser geeignet, beispielsweise für Textanalysen oder das Erstellen eigener Offline-Leser, während SQL-Dumps bei der Verwendung der Daten in eigenen MediaWiki-Installationen von Vorteil sind.
Neben reinen Text-Dumps können Nutzer auch Dateien für Mediendaten (wie Bilder, Audio oder Video) herunterladen. Diese sind meist über extrahierte Mirror-Server verfügbar, da die Menge an Mediendateien sehr groß ist und regelmäßig aktualisiert wird. Dabei sollte man beachten, dass Mediendateien oft unter verschiedenen Lizenzen stehen und bestimmte Nutzungsbedingungen zu beachten sind. Technische Herausforderungen: Umgang mit großen Dateien Die Sache mit der Größe ist zentral. Ein herkömmlicher Download der vollständigen Wikipedia in XML- oder SQL-Form bedeutet oft Datenmengen in der Größenordnung von Dutzenden bis zu Hunderten Gigabyte.
Für vollständige Revisionsverläufe sogar mehrere Terabyte. Solche Dateien können auf vielen Geräten nicht ohne weiteres verarbeitet oder entpackt werden. Zudem ist es wichtig, vor dem Download sicherzustellen, dass das verwendete Dateisystem auf der Festplatte so große Dateien unterstützt. Ältere Dateisysteme wie FAT32 haben z.B.
eine Grenze von 4 GB pro Datei. Neuere Systeme wie NTFS auf Windows oder ext4 auf Linux können deutlich größere Dateien verarbeiten. Ebenso sind ältere Betriebssysteme und Programmwerkzeuge oft nicht für den Umgang mit Dateien dieser Größenordnung ausgelegt. Deshalb sollte unbedingt geprüft werden, ob die IT-Infrastruktur den Anforderungen gewachsen ist. Um den Download stabil und effizient zu gestalten, wird häufig der Einsatz von Downloadmanagern empfohlen, die Downloads anhalten und fortsetzen können.
Eine andere Möglichkeit besteht darin, die Daten via BitTorrent herunterzuladen. Dadurch wird einerseits die Serverlast gesenkt und andererseits die Chance auf erfolgreiche Downloads erhöht. Multistream-Architektur und deren Vorteile Die Multistream-Variante unterscheidet sich dadurch, dass sie mehrere sogenannte Bzip2-Streams nacheinander in einer Datei vereint. Jeder einzelne Stream enthält Daten zu 100 Artikeln und hat jeweils eine eigene Struktur. Das macht es möglich, gezielt einzelne Abschnitte der Datei zu entpacken, ohne die Komplettdatei zu bearbeiten.
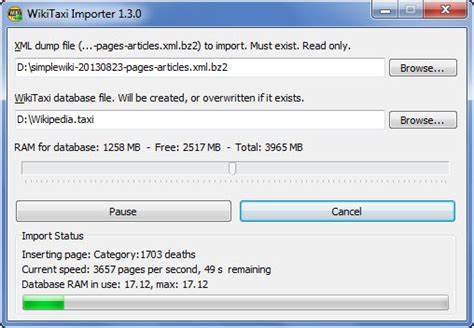
Hierfür steht auch eine Indexdatei zur Verfügung, die die Bytepositionen der einzelnen Streams aufzeigt. Viele moderne Offline-Leser und Programmbibliotheken unterstützen dieses Verfahren, was die Nutzung der Dumps deutlich praktischer macht. Gerade bei eingeschränktem Speicherplatz oder begrenzter Verarbeitungskapazität auf Endgeräten ist die Multistream-Technik ein großer Vorteil. Offline-Wikipedia-Reader: Komfortable Nutzung ohne Internet Es gibt zahlreiche Programme, die es erlauben, die Wikipedia-Dumps offline lesbar zu machen und zu durchsuchen. Bekannte Vertreter sind etwa Kiwix, XOWA, WikiTaxi oder BzReader.
Diese Leser bieten neben einem Volltext-Suchsystem auch komfortable Oberflächen und Unterstützung für diverse Medieninhalte. Für mobile Geräte wie Smartphones oder Tablets existieren spezielle Apps, die den Zugriff auf komprimierte Wikipedia-Inhalte ermöglichen. Kiwix ist hierbei das populärste Tool und unterstützt zahlreiche Sprachen und Wikimedia-Projekte. Es arbeitet mit den sogenannten ZIM-Dateien, die speziell komprimierte Versionen der Dumps darstellen und noch handlicher sind. Auch die Anzeige von Bildern und Formeln ist bestens integriert.
Für Nutzer, die gezielt Artikel offline recherchieren wollen, bietet Kiwix eine umfangreiche Auswahl und einfache Bedienung. XOWA ist eine Alternative, die den kompletten Wikipedia-Inhalt inklusive HTML-Rendering offline verfügbar macht. Das Programm ist plattformübergreifend und unterstützt erweiterte Navigation und Volltextsuche. Für Softwareentwickler ist es interessant, da sie eigene Anpassungen vornehmen können. Rechtliche und lizenztechnische Hinweise beim Download Wikipedia-Inhalte werden in der Regel unter der Creative Commons Attribution-ShareAlike 4.
0 Lizenz (CC-BY-SA) sowie der GNU Free Documentation License (GFDL) veröffentlicht. Das bedeutet, dass sie frei geteilt, genutzt und bearbeitet werden können, solange die entsprechende Lizenzbeachtung erfolgt und Autoren genannt werden. Für Bilder und andere Mediendateien gilt dies nicht unbedingt uneingeschränkt, da diese oft unterschiedliche Lizenzbedingungen haben. Nutzer sollten deshalb immer die jeweiligen Beschreibungsseiten der Mediendateien prüfen und die Lizenzvorgaben einhalten. Wichtig ist auch, dass der Download mittels Web-Crawlern oder automatisierten Bots auf der Wikipedia-Domain untersagt ist.
Das Wikipedia-Projekt bittet darum, stattdessen auf die offiziellen Dumps und APIs zurückzugreifen, um die Server nicht unnötig zu belasten und Sperrungen zu vermeiden. Werkzeuge zur Analyse und Verarbeitung der Dumps Wer die Dumps für wissenschaftliche Auswertung, maschinelles Lernen oder weitere Anwendungen nutzen möchte, findet zahlreiche Software-Bibliotheken und Tools. Beispiele sind Perl-Module zur Dump-Verarbeitung, .NET Libraries für SQL-Dumps oder auch Programme in Rust und Go, die effiziente Parsing-Methoden anbieten. Besonders bei der Verarbeitung großer Dumps empfiehlt sich der Einsatz spezialisierter Tools, die mit Multistream-Dateien umgehen können und Ressourcen schonen.
Für Datenbankanwendungen bietet sich ebenso die Möglichkeit, XML-Dumps in MySQL oder MariaDB zu importieren, um eigene Abfragen per SQL durchzuführen. Wikimedia bietet hierfür ausführliche Dokumentationen und Beispielskripte an. Fazit Das Herunterladen und Nutzen der Wikipedia-Datenbank bietet eine unschätzbare Ressource für viele Anwendungsbereiche. Die Vielfalt an verfügbaren Datenformaten, die Unterstützung durch zahlreiche Offline-Apps und die Möglichkeiten zur individuellen Datenanalyse machen die Wikipedia-Dumps äußerst vielseitig. Gleichzeitig sind die Größen der Dateien und technische Anforderungen nicht zu unterschätzen.
Vor dem Download sollte die Infrastruktur überprüft und die geeignete Dump-Version gewählt werden, um optimale Leistung und Bedienbarkeit zu gewährleisten. Ganz gleich ob für wissenschaftliche Projekte, private Archivierungen oder den Aufbau eigener Anwendungen – wer sich intensiv mit der Wikipedia-Datenbank auseinandersetzt, wird mit den richtigen Herangehensweisen durchaus erfolgreich sein und die Vorteile dieser umfangreichen Wissensdatenbank auch offline voll ausschöpfen können.