In der Welt des maschinellen Lernens und der künstlichen Intelligenz nimmt die Rolle von Reinforcement Learning (RL) eine immer bedeutendere Stellung ein. RL ist eine Methode, bei der Agenten durch Versuch und Irrtum lernen, auf eine optimale Weise in einer Umgebung zu agieren, um ein definiertes Ziel zu erreichen. Trotz der enormen Fortschritte in diesem Bereich stehen Entwickler und Forscher oft vor komplexen Herausforderungen, wenn es darum geht, RL-Agenten effektiv zu trainieren und zu optimieren. Hier setzt ART an – ein neues Open-Source-RL-Framework, das speziell entwickelt wurde, um die Trainingsprozesse von Agenten zu vereinfachen und zu verbessern. ART, kurz für Agent Reinforcement Trainer, hebt sich durch eine innovative Herangehensweise an den Trainingsprozess hervor.
Während viele bestehende Bibliotheken den Fokus auf isolierte RL-Algorithmen legen, integriert ART das Training in die reale Codebasis der Nutzer und automatisiert gleichzeitig die komplexen Trainingsschleifen im Hintergrund. Dies ermöglicht Entwicklern, Agenten im Anwendungskontext auszuführen und gleichzeitig von den leistungsstarken RL-Algorithmen zu profitieren, ohne sich in den technischen Details des Trainingsprozesses zu verlieren. Das Herzstück von ART bildet der GRPO-Algorithmus, der für Generative Reinforcement Policy Optimization steht. Dieser moderne Ansatz im Bereich des Reinforcement Learning erlaubt es Modellen, aus ihren eigenen Erfahrungen heraus stetig zu lernen und sich zu verbessern. Durch den Einsatz von GRPO gelingt es ART, auch komplexe Aufgabenstellungen anzugehen, bei denen herkömmliche RL-Methoden an ihre Grenzen stoßen.
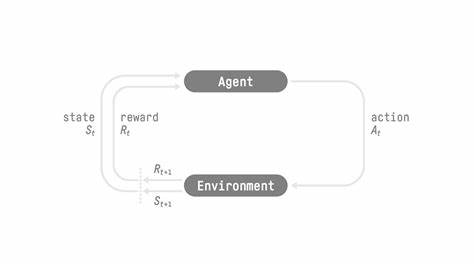
In Verbindung mit der modularen Architektur, die eine saubere Trennung von Client und Server vorsieht, bietet ART sowohl Flexibilität als auch Skalierbarkeit in der Trainingsumgebung. Ein besonders bemerkenswertes Merkmal von ART ist die Art und Weise, wie der Trainingszyklus gestaltet ist. Der Prozess beginnt mit der Inferenzphase, in der der Agent in der tatsächlichen Umgebung arbeitet und verschiedene Szenarien durchläuft. Jede Interaktion wird dabei detailliert dokumentiert und in sogenannten Trajektorien gespeichert. Diese Trajektorien erfassen alle Kommunikationselemente zwischen System, Nutzer und Agent, sodass das Modell nicht nur einzelne Aktionen, sondern gesamte Abläufe analysieren und bewerten kann.
Sobald eine Reihe von Trajektorien gesammelt ist, kommt die Trainingsphase zum Tragen. Die gesammelten Daten werden an den ART-Server übermittelt, der die GRPO-Optimierung vornimmt. Während dieser Phase ist die Inferenz vorübergehend pausiert, um eine konsistente und fokussierte Aktualisierung des Modells zu gewährleisten. Nach Abschluss des Trainings lädt der Server das aktualisierte Modell und setzt die Inferenz wieder fort. Dieser zyklische Ablauf ermöglicht es Agenten, sich kontinuierlich zu verbessern und mit jeder Iteration präzisere und effizientere Entscheidungen zu treffen.
Die Integration von ART in bestehende Projekte gestaltet sich dank der OpenAI-kompatiblen Client-Schnittstelle besonders anwenderfreundlich. Entwickler können ihre Anwendungen nahtlos mit ART verbinden und so die Vorteile eines spezialisierten RL-Trainings nutzen, ohne große Umstellungen im eigenen Code vornehmen zu müssen. Darüber hinaus unterstützt ART eine breite Palette von vLLM- und HuggingFace-kompatiblen Sprachmodellen, was den Einsatz in diversen Anwendungsfeldern deutlich erleichtert. ART hat bereits in mehreren praxisnahen Projekten seine Wirksamkeit unter Beweis gestellt. Verschiedene Beispielnotebooks zeigen, wie leistungsstark dieses Framework ist.
So konnte beispielsweise ein Agent basierend auf dem Qwen 2.5 Modell in Spielen wie 2048, Tic Tac Toe und Codenames trainiert werden und erzielte dabei beeindruckende Ergebnisse. Ebenso wird gerade an weiteren Anwendungsfällen gearbeitet, die den Einsatz von ART über Spielumgebungen hinaus auf komplexe textbasierte Problemlösungen und agentenbasierte Aufgaben ausweiten. Die Entwicklergemeinschaft hinter ART ist aktiv und engagiert, was eine kontinuierliche Weiterentwicklung des Frameworks sicherstellt. Benutzer werden ermutigt, sich an der Entwicklung zu beteiligen, Feedback zu geben und durch Beiträge zur Verbesserung beizutragen.
Mit einer offen zugänglichen Codebasis unter der Apache-2.0-Lizenz bietet ART ein hohes Maß an Transparenz und ermöglicht umfangreiche Anpassungen an spezifische Anforderungen. Ein weiterer Punkt, der ART besonders interessant macht, ist die Möglichkeit, RL in realweltlichen Anwendungen einzusetzen, ohne dabei das Rad neu erfinden zu müssen. Das ART•E Agent Projekt demonstriert beispielhaft, wie es gelingt, komplexe Aufgaben wie die E-Mail-Recherche mithilfe von RL-Modellen zu automatisieren und dadurch Effizienzsteigerungen zu erreichen. Solche Anwendungsbeispiele zeigen, dass ART nicht nur für akademische Zwecke geeignet ist, sondern auch in unternehmerischen Kontexten echten Mehrwert schafft.
Die Kombination aus modernster Forschung, praktischer Anwendbarkeit und einer benutzerfreundlichen Architektur macht ART zu einem vielversprechenden Werkzeug in der KI-Community. Es adressiert eine Lücke zwischen theoretischen RL-Algorithmen und der realen Integration solcher Systeme in produktive Umgebungen. Unternehmen, Entwickler und Forscher können durch den Einsatz von ART Vorteile in Bereichen wie Automatisierung, Datenanalyse und intelligenten Assistenzsystemen realisieren. Zusammenfassend lässt sich sagen, dass ART ein Meilenstein in der Weiterentwicklung von RL-Frameworks darstellt. Es bietet eine flexible, leistungsfähige und offene Plattform, die es ermöglicht, Agenten effizient zu trainieren und das Beste aus modernen Sprachmodellen herauszuholen.
Die klare Trennung zwischen Client und Server, die Nutzung des GRPO-Algorithmus und die Unterstützung vielfältiger Modelle machen ART zu einem unverzichtbaren Tool, um die nächste Generation intelligenter Agenten zu entwickeln und in der Praxis einzusetzen. Für all jene, die die Zukunft der KI aktiv mitgestalten möchten, könnte ART der Schlüssel sein, um komplexe Herausforderungen zu meistern und innovative Lösungen zu realisieren. Die offene Verfügbarkeit sowie umfangreiche Dokumentation und Beispiele ermöglichen einen schnellen Einstieg und eine unkomplizierte Integration in bestehende Systeme. So öffnet ART die Tür zu einer neuen Ära effektiven und praktikablen Reinforcement Learning Trainings.



![Oracle-guided Harnessing for Auto-generating C API Fuzzing Harnesses [pdf]](/images/9559D821-958B-42B4-A298-FE56BC2BF003)