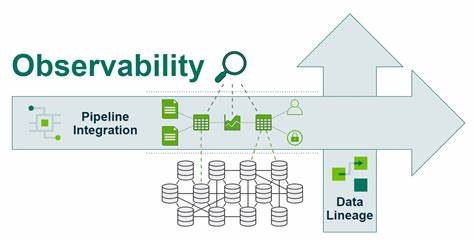
In der heutigen schnelllebigen digitalen Welt ist Observability ein unverzichtbares Werkzeug für Unternehmen, die ihre Infrastruktur, Anwendungen und Dienste überwachen und optimieren möchten. Die stetig wachsende Menge an Telemetriedaten wie Logs, Metriken und Traces bietet einen Schatz an Informationen, der jedoch nur dann wirklich wertvoll wird, wenn sich daraus klare, präzise und umfassende Einblicke gewinnen lassen. Trotz der großen Bedeutung dieser Datenquellen werfen viele Experten und Praktiker die Frage auf, ob der aktuelle Stand der Abfrage von Observability-Daten den Anforderungen der Nutzer gerecht wird oder ob fundamentale Defizite den vollen Nutzen verhindern.Die Herausforderung bei der Abfrage von Observability-Daten liegt vor allem in der Vielfalt und Komplexität der verschiedenen Telemetriesignale. Logs, Metriken und Traces stammen häufig aus unterschiedlichen Systemen und Tools, die jeweils eigene Speichermodelle, Abfragesprachen und Analysemethoden nutzen.
Dies führt dazu, dass Nutzer bislang meist gezwungen sind, diese Signale isoliert zu analysieren – eine Vorgehensweise, die wichtige Zusammenhänge und Korrelationen kaum oder nur umständlich erkennen lässt. Zwar bieten viele Plattformen grundlegende Funktionen zum Durchsuchen einzelner Datentypen, doch nahtlose und integrierte Abfragen über verschiedene Datenarten hinweg bleiben in den meisten Fällen außer Reichweite.Ein markantes Beispiel ist die Schwierigkeit, Logs von einem bestimmten Host abzurufen, der während eines definierten Zeitraums den höchsten CPU-Verbrauch aufweist. Diese Art der Fragestellung verlangt, zuerst die relevanten Metrikdaten auszuwerten, um den Host zu identifizieren, und anschließend mühsam die Logs dieses Hosts separat zu analysieren. Diese Zweischritt-Prozedur ist nutzerunfreundlich, zeitaufwändig und stößt an ihre Grenzen, wenn Echtzeit-Einblicke oder umfassende Korrelationen über eine Vielzahl von Hosts und Diensten gefragt sind.
Ein weiterer kritischer Punkt betrifft die Aggregation und Auswertung von Daten über mehrere Dimensionen hinweg. Viele Observability-Tools erlauben zwar einfache Zähloperationen wie das Zählen eindeutiger Werte innerhalb einer einzelnen Spalte – etwa die Anzahl verschiedener Quell-IP-Adressen oder Services. Sobald jedoch mehrere Dimensionen kombiniert werden, beispielsweise wenn man die eindeutigen Hosts und gleichzeitig die dazugehörigen Services zusammen analysieren möchte, sind die meisten Systeme überfordert. Diese fehlende Flexibilität schränkt das analytische Potenzial erheblich ein und verhindert tiefgründige Drilldowns, die für die Ursachenforschung und Prävention von Problemen essenziell sind.Um diese Lücken zu schließen, entwickeln moderne Plattformen wie SigNoz neue Ansätze für die Abfrage von Observability-Daten.
Besonders vielversprechend ist das Konzept der sogenannten Sub-Queries, bei denen das Ergebnis einer Abfrage als Input für eine zweite Abfrage dient. Dadurch lassen sich komplexe Filterungen und Verknüpfungen realisieren, die bisher nur mit erheblichem manuellen Aufwand möglich waren. Beispielsweise kann zunächst die Liste der Hosts mit hohem CPU-Verbrauch ermittelt und anschließend automatisch deren Logs durchsucht werden, ohne dass der Nutzer zwischen verschiedenen Schnittstellen wechseln muss.Darüber hinaus gewinnt die Fähigkeit, sogenannte Cross-Signal-Joins zu ermöglichen, zunehmend an Bedeutung. Dabei werden unterschiedliche Telemetriesignale direkt miteinander verknüpft, sodass neben Metriken auch Logs und Traces in einer einheitlichen Ansicht dargestellt und analysiert werden können.
Dadurch entstehen neue Möglichkeiten für umfassende Korrelationen und tiefere Einblicke in komplexe IT-Umgebungen, die bisher nicht ohne weiteres zugänglich waren. Ein System, das derartige Verknüpfungen unterstützt, ermöglicht beispielsweise, dass man die Ursache für eine auftretende Latenz im Netzwerk direkt durch die Kombination von Metriken und zugehörigen Trace-Daten identifizieren kann.Allerdings bedeutet die Umsetzung solcher Funktionen auch erhebliche technische Herausforderungen. Die verschiedenen Datenarten unterscheiden sich nicht nur in Struktur und Volumen, sondern auch in ihrem Lebenszyklus und der Art ihrer Speicherung. Metriken sind oft zeitserienorientiert und sehr aggregiert, während Logs detailreiche, unstrukturierte Textdaten enthalten können und Traces zusätzlich eine komplexe hierarchische Struktur aufweisen.
Die Vereinheitlichung und Abfrage all dieser Datenquellen erfordert intelligente Abfrageprozessoren, effiziente Speicherlösungen und eine durchdachte Architektur, die Skalierbarkeit und Performance garantiert.Trotz dieser Schwierigkeiten besteht wachsender Bedarf in der Industrie für solche innovativen Ansätze. Entwickler und Betreiber von IT-Systemen erwarten nicht nur schnelle und flexible Abfragen, sondern auch eine vereinigte Benutzererfahrung, mit der sich mehrere Telemetriesignale parallel untersuchen lassen. Diese Integration fördert eine präzise Fehlerdiagnose, verbessert das Monitoring und ermöglicht das frühzeitige Erkennen von Ausfällen oder Performance-Einbrüchen. Der Trend geht eindeutig dahin, Observability nicht als fragmentierte Sicht auf einzelne Signale, sondern als ganzheitliches Bild der Systemgesundheit zu begreifen.
Neben der technischen Machbarkeit spielt auch die Usability eine entscheidende Rolle. Die Abfragewerkzeuge müssen intuitiv bedienbar sein und ohne tiefes Expertenwissen genutzt werden können. Oftmals liefern klassische SQL-ähnliche Sprachen zwar mächtige Features, sind aber für Administratoren und Entwickler frustrierend komplex. Daher investiert die Community verstärkt in benutzerfreundliche UI-Konzepte und visuelle Query Builder, die auch komplexe Operationen ohne Programmierkenntnisse ermöglichen.Zusammenfassend lässt sich festhalten, dass der aktuelle Stand der Abfragen von Observability-Daten in vielen Fällen tatsächlich unzureichend ist.





![Dakar-Djibouti (1931-1933): Counter Investigations [pdf]](/images/8E7EC862-27A7-4596-A1EC-937549EEE0F8)