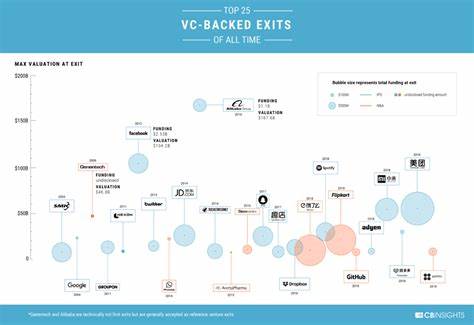
Die rasante Entwicklung großer Sprachmodelle (Large Language Models, LLMs) wie GPT-4, Claude und anderer hat die Art und Weise, wie wir mit Computern interagieren, grundlegend verändert. Die Fähigkeit dieser Modelle, menschenähnliche Texte zu erzeugen, Codeschnipsel zu schreiben oder kreative Inhalte zu erstellen, ist beeindruckend und öffnet zahlreiche Türen für neue Anwendungen in Wirtschaft, Bildung, Forschung und Unterhaltung. Trotz ihrer enormen Potenziale steht die Branche vor einer bedeutenden Herausforderung: Die verlässliche und präzise Umsetzung von detaillierten, oft komplexen Benutzeranweisungen. Diese Herausforderung scheint nicht nur technischer Natur zu sein, sondern beeinflusst unmittelbar die Nutzererfahrung und das Vertrauen in die Technologie. Viele Nutzer erleben diese Problematik in ihrem Alltag mit LLMs.
Es geht dabei nicht nur um gelegentliche Fehler, sondern um wiederkehrende Inkonsistenzen und die Unfähigkeit der Modelle, festgelegte Vorgaben dauerhaft zu berücksichtigen. So kommt es häufig vor, dass bei mehrstufigen Aufgaben wichtige Anweisungen ignoriert oder nur teilweise umgesetzt werden. Beispielsweise kann ein Modell trotz der ausdrücklichen Aufforderung, bestimmte Wortwahl zu vermeiden oder eine streng strukturierte Gliederung einzuhalten, dennoch vom ursprünglichen Briefing abweichen. Solche Unzuverlässigkeiten machen die Integration von LLMs in professionelle Prozesse herausfordernd, da im schlimmsten Fall manuelle Nacharbeit erforderlich wird. Jenseits der Textgenerierung treten diese Probleme ebenso bei der Unterstützung im Programmierbereich auf.
Nutzer berichten davon, dass generierte Codes nicht konsistent den vorgegebenen Stil oder die geforderte Logik widerspiegeln. Auch bei der Strukturierung von Daten in Formaten wie JSON oder XML zeigen sich ähnliche Schwierigkeiten, die eine zuverlässige Automatisierung erschweren. Eine weitere Dimension ist die mangelnde Gedächtnisfunktion über mehrere Sitzungen hinweg. Viele Nutzer haben die Erfahrung gemacht, dass ein LLM in einer späteren Konversation die zuvor geäußerten Präferenzen oder spezifischen Regeln schlichtweg vergisst. Diese fehlende Persistenz führt zu wiederholtem Verlust individueller Anpassungen und negiert erwartete Personalisierungen.
Vor dem Hintergrund dieser Herausforderungen stellt sich die zentrale Frage, ob es einen Bedarf für eine neue Lösung gibt, die genau hier ansetzt: eine Schicht über den bestehenden Modellen, die strikte und unverrückbare Vorgaben ermöglicht und laufend sichert. Ein solches System könnte die Anweisungen eines Benutzers nicht nur strikt einhalten, sondern zudem über Sessions hinweg bewahren. Es würde somit die Zuverlässigkeit deutlich erhöhen und das Nutzererlebnis maßgeblich verbessern. Die Diskussion um diese Problematik zeigt allerdings, dass einige Experten skeptisch sind, ob sich Vagheit etwa bei Tönen oder Logik mithilfe von vorhandenen Prompt-Techniken zuverlässig eliminieren lässt. Die intrinsische Natur der Sprachmodelle als probabilistische Systeme stellt eine Art von Unschärfe dar, die nicht einfach durch ausgefeilte Eingaben ausgehebelt werden kann.
Trotzdem sprechen viele Anwender von konkreten Fällen, in denen gerade die konsequente Befolgung von Strukturvorgaben und Ausschlusskriterien elementar für die Arbeit ist. Hier zeigen sich deutliche Defizite im aktuellen Stand, denen mit cleveren Lösungsansätzen begegnet werden muss. Eine teils praxisbewährte Methode zur Steigerung der Konsistenz besteht darin, die Modelle Code generieren zu lassen, der im Anschluss ausgeführt wird und klar definierte Datenstrukturen oder Resultate produziert. Diese Vorgehensweise kann die Variabilität der Antworten verringern und für reproduzierbare Ergebnisse sorgen. Dies ist jedoch nicht in allen Anwendungsfällen praktikabel oder wünschenswert und betrifft hauptsächlich Aufgaben mit technisch präzisen Ergebnissen.
Über die technischen Überlegungen hinaus wirft die Diskussion um zuverlässige LLMs auch ökonomische Fragen auf. Würden Nutzer für ein Produkt zahlen, das diese Problematik zuverlässig löst? Viele Stimmen aus der Praxis bejahen dies, da hohe Erwartungen an Automatisierungen entstehen, die heute nur teilweise eingehalten werden. Unternehmen, Forscher, Entwickler und kreative Köpfe investieren viel Zeit darin, mit widersprüchlichen Ergebnissen umzugehen oder redundante Korrekturen durchzuführen. Eine Lösung, die diesen Aufwand reduziert, hätte daher einen signifikanten Mehrwert. Ein weiterer Aspekt, der in der Debatte häufig aufkommt, ist die Frage, ob sich solche Herausforderungen nicht zu kurz oder mittelfristig von den großen LLM-Anbietern selbst lösen lassen.
Die Innovationszyklen sind zwar kurz, und die Forschungsfortschritte rasant, doch verbleibt die Unsicherheit, ob Kernprobleme wie die fehlende strikte Befolgung von Anweisungen allein durch bessere Grundmodelle ausgehebelt werden können. Das lässt Raum für externe Entwickler oder Startups, die spezialisierte Lösungen anbieten, die oberhalb der Basistechnologie liegen. Die Idee, eine Art Kontrollschicht zu schaffen, die definierte Regeln permanent überwacht und Verstöße sofort korrigiert, könnte einen neuen Standard im Umgang mit KI-gestützten Text- und Datenproduktionssystemen setzen. Langfristig könnten LLMs, die ihre Performance auf Verlässlichkeit ausrichten und den Nutzerwünschen kompromisslos folgen, das Vertrauen in KI-Technologien drastisch steigern. Besonders in sicherheitskritischen Anwendungsfeldern wie Medizin, Recht oder Finanzwesen wäre der Nutzen solcher Systeme enorm.
Eines ist klar: Sprache lebt von Nuancen, Kontext und Flexibilität, doch genau hier liegt die Herausforderung, wenn es um prädiktive Modelle geht, die als Werkzeuge fungieren sollen. Die Balance zwischen Kreativität und Präzision, zwischen Freiheit und strikter Regelbefolgung zu finden, definiert die nächste Entwicklungsstufe der Künstlichen Intelligenz. Der heutige Status quo zeigt, dass trotz aller Fortschritte noch beträchtliche Reserven bestehen. Wer diesen Bedarf erkennt und adressiert, könnte nicht nur technologisch punkten, sondern auch kommerziell erfolgreich sein. Zusammenfassend lässt sich sagen, dass die Frage nach der verlässlichen Befolgung von Anweisungen durch LLMs nicht nur eine technische Hürde darstellt, sondern ein fundamentales Anliegen im Umgang mit digitaler Intelligenz ist.
Die Zukunft könnte Modelle bringen, die nicht nur mit beeindruckenden Fähigkeiten glänzen, sondern auch jene Kontinuität und Konstanz liefern, die für praktische Anwendungen unerlässlich sind. Bis dahin bleibt es spannend zu beobachten, welche Lösungen sich durchsetzen und wie die Evolution dieser Technologie den Alltag von Millionen verändern wird.