In einer Welt, in der Künstliche Intelligenz und insbesondere Large Language Models (LLMs) zunehmend Einfluss auf die Online-Recherche und Inhalte-Verarbeitung nehmen, rückt das Thema der Zugänglichkeit und Steuerung von Website-Inhalten in den Fokus. Der Standard llms.txt ist eine innovative Antwort auf die Herausforderungen, die sich für Webseitenbetreiber in Bezug auf das Crawling und die Nutzung ihrer Inhalte durch KI-Systeme ergeben. Entwickelt wurde dieser Standard vom australischen Technologen Jeremy Howard und wird aktuell als eine potenzielle neue Norm diskutiert, ähnlich wie zuvor robots.txt und XML-Sitemaps die Interaktion mit Suchmaschinen definierten.
Der Kerngedanke hinter llms.txt ist es, LLMs eine bessere und strukturierte Möglichkeit zu bieten, Webseiteninhalte zu erfassen, ohne dabei die Grenzen ihrer technischen Möglichkeiten zu überschreiten. Viele KI-Modelle, egal wie fortgeschritten, stoßen auf das Problem kleiner Kontextfenster, was bedeutet, dass sie nicht den gesamten umfangreichen Inhalt einer Website auf einmal verarbeiten können. Zusätzlich erschweren komplexer HTML-Code, dynamische Navigationen oder JavaScript die Aufbereitung der Inhalte. llms.
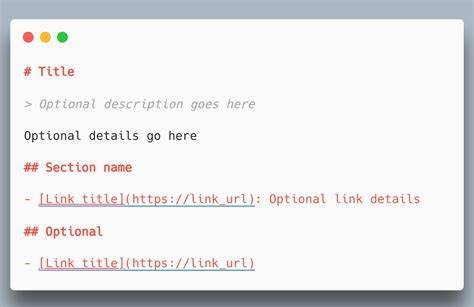
txt bietet nun die Möglichkeit, die Inhalte in einem klaren, lesbaren und präzisen Format bereitzustellen, das sowohl für Menschen als auch Maschinen leicht interpretierbar ist. Im Allgemeinen ähnelt llms.txt der robots.txt, da es als einfach zu handhabende Textdatei im Stammverzeichnis einer Website hinterlegt wird. Allerdings liegt ein wesentlicher Unterschied darin, dass llms.
txt nicht ausschließlich dazu dient, den Zugriff einzuschränken oder zu verhindern. Vielmehr ist es eine bewusste Auswahl dessen, welche Inhalte für KI-Modelle zugänglich gemacht oder in welcher Form bereitgestellt werden sollen – ob als URL-Übersicht, kurze Zusammenfassungen oder als komplett geflatteter Rohtext. Die Möglichkeit, Seiteninhalte vollständig in Textform abzubilden, eröffnet Website-Betreibern nicht nur Kontrolle, sondern auch zahlreiche Analyseoptionen, die vorher nur mit speziellen Tools möglich waren. Die praktischen Vorteile von llms.txt sind vielfältig.
Website-Besitzer können durch die Bereitstellung einer flachen, gut strukturierten und vollständig durchsuchbaren Version ihrer Inhalte die Ressourcenanforderungen der KI beim Crawling erheblich reduzieren. Gleichzeitig steigt die Chance, dass relevante und qualitativ hochwertige Inhalte von KIs korrekt interpretiert und verwendet werden – was insbesondere SEO-Aspekte betrifft. Eine gut gepflegte llms.txt kann die Sichtbarkeit einer Website in AI-gestützten Suchergebnissen nachhaltig beeinflussen und dabei helfen, die Inhalte zielgerichteter und effizienter zu distribuieren. Vor allem Marken profitieren davon, dass sie ein gewisses Maß an Einfluss darauf gewinnen, wie ihre Informationen in automatisierten Antworten erscheinen.
Somit ergibt sich eine Möglichkeit, die Reputation zu schützen und Fehlinformationen vorzubeugen. Darüber hinaus unterstützt llms.txt vielfältige Anwendungen, die über die einfache Crawlsteuerung hinausgehen. Die Nutzung einer vollständig geflatteten Website-Version wirkt sich positiv auf tiefergehende Analysen aus: Keyword-Frequenz, Entitäten-Erkennung oder die Bewertung der internen Verlinkungsstruktur können mit KI-Unterstützung schneller und präziser erfolgen. Für Unternehmen mit umfangreichen Online-Portfolios lassen sich so wertvolle Erkenntnisse ableiten, die zuvor aufwändige manuelle Prüfungen erforderten.
Trotz der verheißungsvollen Vorteile gibt es auch einige Herausforderungen bei der Einführung und Nutzung von llms.txt. Die wichtigste Frage ist die Akzeptanz seitens der KI-Entwickler. Weil die Einhaltung einer solchen Datei freiwillig ist, kann es passieren, dass einige LLMs die Vorgaben ignorieren und Inhalte ungefiltert nutzen. Für Websitebetreiber bedeutet das, dass allein die Existenz einer llms.
txt keine Garantie für den Schutz ihrer Daten bietet. Zudem müssen Website-Inhaber selbst aktiv werden und die Datei korrekt generieren und regelmäßig pflegen, was zusätzlichen Aufwand bedeutet. Ein weiteres Problemfeld ist die mögliche Überschneidung und Verwirrung mit bestehenden Standards wie robots.txt oder XML-Sitemaps. Wenngleich llms.
txt eine eigenständige Funktion übernimmt, besteht die Gefahr, dass Webmaster durch die Vielzahl von Steuerdateien den Überblick verlieren oder widersprüchliche Regeln aufstellen. Sicherheitsbedenken spielen ebenfalls eine Rolle. Das Bereitstellen einer simplifizierten und kompletten Textversion der Webseite erhöht die Transparenz, was zwar für KI vorteilhaft ist, aber auch potentiellen Wettbewerbern oder böswilligen Akteuren erleichtert, wertvolle Informationen analytisch auszuwerten oder gar zu missbrauchen. In der SEO- und GEO-Community ist die Haltung zu llms.txt gespalten.
Kritiker werfen ein, dass die klare Trennung zwischen Suchmaschinen-Crawlern und LLMs allmählich verschwindet und somit herkömmliche Protokolle für beide Zwecke ausreichen sollten. Sie sehen llms.txt als überflüssig oder gar als irreführend an, da viele moderne Suchmaschinen bereits KI-Technologien integrieren, die auf Standards wie robots.txt aufbauen. Trotzdem berichten Experten und Frühadapter, dass die Verwendung von llms.
txt derzeit neue Möglichkeiten der Inhaltsoptimierung und -analyse bietet, die sich zwar noch in der Entwicklung befinden, aber einen möglichen Wettbewerbsvorteil erzeugen können. Die Zukunft von llms.txt hängt maßgeblich von der breiteren Akzeptanz und Weiterentwicklung ab. Wichtig werden Branchenabsprachen, regulatorische Rahmenbedingungen und nicht zuletzt das Engagement der AI-Plattformen sein. Sollte sich der Standard durchsetzen, könnten Inhalte weltweit strukturierter und gezielter für KI-Modelle bereitgestellt werden.
Webseitenbesitzer würden mehr Transparenz und Kontrolle über die Verwendung ihrer digitalen Assets gewinnen, während Nutzer von präziseren und relevanteren KI-generierten Antworten profitieren. Zusätzlich könnte llms.txt dazu beitragen, mehr wissenschaftliche Ansätze in die oft undurchsichtige Welt des GEO (Growth Engine Optimization) zu bringen. Während SEO in vielen Bereichen schon auf etablierten Protokollen und Messgrößen beruht, existieren für GEO bis heute kaum belastbare Standards. llms.
txt stellt insofern einen Schritt in Richtung messbare und überprüfbare Optimierung für KI-gestützte Technologien dar. Insbesondere für größere Content-Anbieter mit umfangreichen Sites kann dieses Tool eine wichtige Rolle spielen. In der Praxis zeigen erste Beispiele von Unternehmen und Projekten wie Anthropic, Hugging Face oder Zapier, dass llms.txt bereits Anwendung findet und auf Interesse stößt. Verschiedene frei verfügbare Generierungstools erleichtern den Einstieg für Webseitenbetreiber.
Ob mit Plugins für WordPress oder Open-Source-Software – die Barriere zur Implementierung ist vergleichsweise niedrig. Dennoch ist Vorsicht geboten: Sicherheit und sorgfältige Prüfung der Inhalte sollten stets Priorität haben, um ungewollte Datenlecks oder Manipulationen auszuschließen. Insgesamt markiert llms.txt einen bedeutenden Schritt in der Weiterentwicklung der Interaktion zwischen KI und Webseiten. Es spiegelt die wachsende Notwendigkeit wider, Datenströme und Zugriffsrechte in einer Ära zu regeln, in der Informationen immer mehr automatisiert verarbeitet werden.




![I solved the LA protests [video]](/images/3CE4DF84-A5AA-4C03-A83F-4232D87B4A16)
