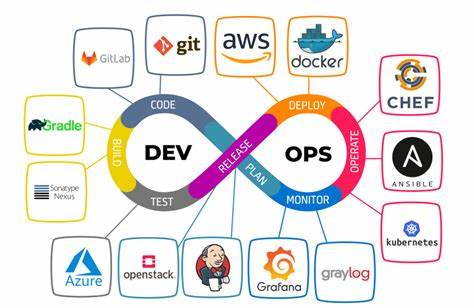
Im Zeitalter der Digitalisierung und datengetriebenen Entscheidungsprozesse ist Data Engineering zu einem unverzichtbaren Teil moderner Unternehmen geworden. Während Data Science oft im Rampenlicht steht, bleibt der entscheidende Rahmen, in dem Daten verlässlich, skalierbar und automatisiert bereitgestellt werden, häufig unzureichend beachtet. Hier spielt DevOps eine immer zentralere Rolle. DevOps im Kontext von Data Engineering ist längst nicht mehr nur ein Schlagwort, sondern ein essenzieller Eckpfeiler, um komplexe Datenpipelines stabil, wartbar und effizient nutzbar zu machen. Ursprünglich kam DevOps aus dem Bereich der Softwareentwicklung, um Silos zwischen Entwicklung und Betrieb aufzulösen und eine kontinuierliche Integration und Bereitstellung (CI/CD) zu ermöglichen.
Im Data Engineering übernimmt DevOps zunehmend ähnliche Aufgaben, indem es Infrastruktur, Pipeline-Deployments und Überwachungsprozesse automatisiert. Dennoch zeigt sich, dass viele Teams vor der Herausforderung stehen, diese Praktiken zu implementieren, da der Einstieg in DevOps und speziell GitOps oft komplex ist und anfänglich viel Zeit und Ressourcen beansprucht. Ein zentraler Ansatz von DevOps im Data Engineering ist GitOps, bei dem das gesamte Infrastruktur- und Deployment-Management über Git-Repositories gesteuert wird. Dies bedeutet, dass Änderungen an der Dateninfrastruktur und den Pipelines durch Versionierung in Git nachvollziehbar und automatisch in die Produktionsumgebung übernommen werden. Die Vorteile sind vielfältig: Fehler lassen sich zurückverfolgen, rollbacks sind einfach durchführbar, und es entsteht ein transparentes Audit-Trail.
Gleichzeitig erfordert GitOps das konsequente Umsetzen von Infrastructure as Code (IaC), bei dem alle Komponenten der Plattform, sei es Kubernetes-Cluster, Datenbanken oder Pipelines, in deklarativen Konfigurationsdateien beschrieben werden. Infrastructure as Code hat in den letzten Jahren eine starke Weiterentwicklung erfahren. Heute umfasst es nicht nur die reine Bereitstellung von Ressourcen, sondern integriert auch Sicherheitsrichtlinien, Compliance-Anforderungen und Governance als Code. Tools wie Terraform, Pulumi oder Helm Charts sind dabei die zentralen Bausteine, um diese Komplexität handhabbar zu machen. Insbesondere in Kubernetes-basierten Datenplattformen ist IaC unabdingbar, um Mandantenisolation, Datenbankmigrationen und Überwachungsmechanismen einheitlich zu verwalten.
Die Integration von Datenbank-Migrationstools wie Liquibase erweitert die Automatisierungsebene und minimiert manuelle Fehler bei Schemaänderungen. Durch automatisierte Tests auf mehreren Ebenen wird die Qualitätssicherung weiter vorangetrieben: Die Datenpipelines, Infrastrukturkomponenten und Migrationen werden getrennt validiert, bevor sie im Zusammenspiel in einer isolierten Testumgebung geprüft werden. Dieses frühe und kontinuierliche Testen, oft als „Shift Left“ bezeichnet, sorgt für stabile Produktivsysteme und reduzierter Fehlerraten. Ein weiterer wichtiger Punkt ist die Trennung von Verantwortlichkeiten und Arbeitsbereichen. Indem die Entwicklungsumgebung für Datenwissenschaftler, Analysten und Data Engineers klar von der Infrastruktur getrennt wird, können Fachleute sich auf ihre Kernkompetenzen konzentrieren, während DevOps-Teams die Einhaltung von Deployment-Standards und Systemzuverlässigkeit sicherstellen.
Dieser klare Fokus fördert Produktivität und reduziert Konflikte zwischen den Teams. Der Einstieg in GitOps und DevOps-Praktiken im Data Engineering gestaltet sich oft schwierig. Neue Teams müssen sich mit komplexen Automatisierungs- und Überwachungstools vertraut machen, was zunächst einen erheblichen Zeitaufwand bedeutet. Allerdings stabilisiert sich der Prozess mit zunehmender Routine und Werkzeugerfahrung. Sobald ein stabiler Satz an Deployment-Skripten und Templates etabliert ist, reduziert sich der Aufwand auf Wartungsarbeiten und Updates.
Die anfänglichen Investitionen zahlen sich langfristig aus, insbesondere in Szenarien mit kontinuierlichem Wachstum und hoher Änderungsfrequenz. Viele Unternehmen stehen zudem vor der Frage, ob sie auf Open-Source-Lösungen setzen oder geschlossene, kommerzielle Plattformen von Hyperscalern wählen sollen. Während geschlossene Systeme eine schnellere und einfachere Implementierung versprechen, bringen sie oft Einschränkungen bezüglich Erweiterbarkeit und Anpassung mit sich. Open-Source-Tools erlauben maximale Flexibilität, erfordern aber eine höhere organisatorische und technische Kompetenz im Bereich DevOps. Auch hier zeigt sich, dass eine klare DevOps-Strategie maßgeblich dafür ist, wie effektiv und skalierbar die Datenplattform betrieben werden kann.
Bei der Implementierung solcher Infrastruktur- und Deployment-Strategien hat sich die Verwendung von Blueprint-Architekturen bewährt. Beispielsweise bieten Referenzarchitekturen für Kubernetes-basierte Datenplattformen mit GitOps-Workflows eine bewährte Grundlage, die Infrastrukturkonfigurationen, Mandantenisolation, Datenbankmigrationen und Monitoring-Vorlagen umfasst. Diese Blueprints sind in der Lage, komplexe Umgebungen reproduzierbar zu erstellen und gewährleisten eine hohe Betriebssicherheit. Neben dem technischen Fokus gewinnt der Developer Experience Aspekt zunehmend an Bedeutung. DevOps-Konzepte wie GitOps verbessern die Produktivität von Datenentwicklungsteams, da sie durch automatisierte Abläufe redundante manuelle Tätigkeiten reduzieren und die Zusammenarbeit durch transparente Prozessdokumentation fördern.
Moderne Tools und Workspaces, wie Codespaces oder Devcontainers, ermöglichen es zudem den Teams, ihre Entwicklungsumgebungen schnell und reproduzierbar bereitzustellen. Zudem verschmilzt das Konzept DataOps mit DevOps-Praktiken und ergänzt diese um neue Methoden zur Qualitätsverbesserung und Beschleunigung der analytischen Datenverarbeitung. DataOps fördert end-to-end Automatisierung, Monitoring und Governance und trägt dazu bei, die gesamte Wertschöpfungskette vom Rohdatenimport bis zur Analyse verständlich und steuerbar zu machen. Abschließend lässt sich sagen, dass der „State of DevOps“ im Data Engineering ein dynamisches Feld ist, das sowohl technische Innovationen als auch organisatorische Anpassungen erfordert. Die Einführung von GitOps, Infrastructure as Code, automatisierten Tests und klaren Rollenmodellen schafft die Grundlage für skalierbare und zuverlässige Datenplattformen.