Die rapide Entwicklung generativer KI-Technologien und große Sprachmodelle (LLMs) haben enorme Anforderungen an die zugrunde liegende Infrastruktur geschaffen. Während KI-Modelle ständig komplexer und ressourcenintensiver werden, steigen auch die Anforderungen an effiziente, skalierbare und kostengünstige Bereitstellungslösungen. Genau hier setzt llm-d an – ein Kubernetes-natives, verteiltes Inferenz-Framework für große Sprachmodelle, das darauf ausgelegt ist, die oft komplizierten Herausforderungen von LLM-Bereitstellungen zu meistern und gleichzeitig höchste Performance und optimale Kosten-effizienz zu erzielen. Traditionelle Ansätze zur Skalierung von Anwendungen in Kubernetes setzen meist auf gleichförmige Replikate und einfache Load-Balancing-Methoden wie Round-Robin. Dies funktioniert sehr gut für viele klassische Einsatzfälle, bei denen Anfragen relativ kurz sind, gleichmäßig verteilt werden und alle Instanzen jeden Request gleich gut bedienen können.
Bei LLM-Workloads gestaltet sich die Situation jedoch anders. Die Anfragen sind oft teuer in Bezug auf Rechenressourcen, weisen eine starke Varianz in Eingabelänge und Ausgabegröße auf und können eine ungleichmäßige Lastverteilung erzeugen. Zudem haben viele große Sprachmodelle mehrstufige oder iterative Anfragemuster, bei denen der Kontext oder vorherige Zwischenergebnisse bei der Verarbeitung eine bedeutende Rolle spielen. llm-d betrachtet diese speziellen Anforderungen als Chance und verwendet fortschrittliche Optimierungen, die speziell für LLM-Inferenz abgestimmt sind. Dazu zählt unter anderem die sogenannte prefix-cache-aware routing Methode.
Hierbei werden Anfragen gezielt auf Instanzen geroutet, die bereits Vorberechnungsergebnisse – sogenannte Key-Value-Caches (KV-Caches) – für die jeweiligen Eingaben im Speicher halten. Somit entfällt eine langwierige Vorverarbeitung und die Antwortzeiten werden dramatisch verbessert. Diese Art des bewussten Routings ist insbesondere bei interaktiven Anwendungen wie Chatbots oder Agenten mit langen Konversationsverläufen ein großer Vorteil und führt zu einer erheblich geringeren Inter-Token-Latency. Ein weiterer innovativer Bestandteil von llm-d ist die Disaggregated Serving Architektur, die die Inferenz in zwei unterschiedliche Phasen trennt: Prefill und Decode. Während die Prefill-Phase mit der Generierung des ersten Tokens aus dem Prompt auf parallelisierbare und rechenintensive Weise arbeitet, ist die Decode-Phase sequenziell und eher speicherbandbreitenorientiert.
Klassische Deployments, bei denen beide Phasen in einer einzigen Instanz zusammenlaufen, sind hinsichtlich Ressourcenausnutzung oft suboptimal. Die Trennung dieser Phasen auf spezialisierte Instanzen ermöglicht eine genauere Skalierung und Optimierung für jede Phase. llm-d nutzt dazu leistungsfähige Schnittstellen und Transporttechnologien wie NVIDIA NIXL, um eine möglichst schnelle und effiziente Kommunikation zwischen den Phasen zu gewährleisten. Die Komplexität moderner LLM-Anwendungen zeigt sich auch in den unterschiedlichen Qualitätsanforderungen an den Service. Während manche Use Cases wie Code Completion oder Suchanfragen extrem niedrige Latenzzeiten verlangen, können andere Anwendungen wie Batch-Analysen oder nächtliche Zusammenfassungen deutlich längere Antwortzeiten tolerieren.
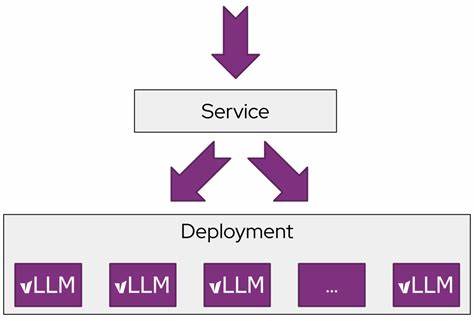
llm-d trägt diesem Spektrum durch flexible QoS-Handling-Mechanismen Rechnung und ermöglicht so eine optimierte Ressourcenzuweisung für latenzkritische und latenztolerante Workloads innerhalb desselben Clusters. Eine weitere wichtige Säule von llm-d ist die nahtlose Integration ins Kubernetes-Ökosystem. Kubernetes gilt als Industriestandard für das Deployment containerisierter Applikationen und bringt robuste Werkzeuge für Skalierung, Orchestrierung und Ausfallsicherheit mit, die von llm-d voll ausgenutzt werden. Über das offizielle Kubernetes-Projekt Inference Gateway (IGW) wird eine erweiterte Gateway-API genutzt, die speziell auf Inferenzbedürfnisse zugeschnitten ist. Diese API unterstützt intelligente Routing-Entscheidungen, Priorisierung von Requests sowie eine erweiterbare Scheduling-Logik, um „smarte“ Lastverteilung zu realisieren – etwa indem einzelne Instanzen abhängig vom jeweiligen Cache-Zustand und der Priorität des Requests selektiert werden.
Das Säulenmodell von llm-d basiert auf bewährten Open-Source-Bausteinen. Die zugrundeliegende Inferenz-Engine vLLM unterstützt unterschiedlichste Modelle und Hardwareplattformen – von NVIDIAs GPUs über Google TPUs bis hin zu AMD- und Intel-Beschleunigern. Die modulare Architektur von llm-d erlaubt es, neue Hardware und Optimierungen einfach zu integrieren, was zukünftige Erweiterungen und Anpassungen erleichtert. Das Zusammenspiel von vLLM, Kubernetes und dem Inference Gateway wirkt wie ein leistungsfähiges Ökosystem, das schnell einsatzfähige und skalierbare LLM-Services ermöglicht. Ein besonderes Augenmerk legt llm-d außerdem auf die automatische Skalierung der Instanzen.
Durch die Analyse der tatsächlichen Anfragenlast, deren Zusammensetzung in Bezug auf Eingabe- und Ausgabelängen sowie die Qualitätsanforderungen wird ein intelligenter Autoscaler implementiert. Dieser passt die Anzahl der Prefill- und Decode-Instanzen flexibel an den aktuellen Bedarf an, um Kosten zu sparen und gleichzeitig die Einhaltung der Service Level Objectives sicherzustellen. Experimentelle Messungen bestätigen die Wirksamkeit und Vorteile des llm-d Ansatzes eindrucksvoll. In Benchmarks mit großen LLMs wie LLaMA 3.1 70B auf Multi-GPU-Systemen konnte llm-d im Vergleich zu herkömmlichen Deployments eine bis zu dreifach niedrigere Time To First Token erzielen sowie den Durchsatz (Queries Per Second) verdoppeln oder sogar verdreifachen, ohne dass Service Level Agreements verletzt wurden.
Diese Leistungssprünge sind vor allem auf die cache- und prefix-aware Routing-Strategien sowie die disaggregierte Architektur zurückzuführen. Für Unternehmen und Entwickler, die große Sprachmodelle betreiben wollen, bietet llm-d somit einen klaren Mehrwert. Es erschließt den Zugang zu komplexen verteilten Inferenzoptimierungen, die bisher meist nur in hochspezialisierten Systemen zu finden waren. Gleichzeitig wird durch die Kubernetes-Integration ein vertrautes und bewährtes Deployment-Umfeld geschaffen, das in vielen Unternehmen und Cloud-Anbietern bereits etabliert ist. Die Community hinter llm-d wächst momentan schnell und ist offen für Beteiligung und Beiträge von KI-Ingenieuren, Plattform-Teams und Forschern.
Über eine aktive Slack-Gruppe, öffentliche GitHub-Repositories sowie umfangreiche Quickstart-Anleitungen können Interessierte direkt und unkompliziert einsteigen. Damit wird eine offene und kollaborative Entwicklungsumgebung geschaffen, in der Innovationen schnell umgesetzt und verbreitet werden können. Zusammenfassend lässt sich sagen, dass llm-d ein Meilenstein in der Entwicklung skalierbarer, verteilter LLM-Inferenz ist. Durch die Kombination spezialisierter Techniken wie prefix-cache-aware Routing, disaggregierter Serving-Architekturen und Kubernetes-nativer Integrationen wird nicht nur die Performance deutlich verbessert, sondern auch die Betriebsführung erheblich vereinfacht. Gerade im Zeitalter von immer größeren und komplexeren allgemeinen KI-Modellen stellt llm-d einen entscheidenden Schritt dar, um diese Technologie praktikabel, nachhaltig und wirtschaftlich nutzbar zu machen.