Die japanische Schriftsprache stellt Lernende vor eine große Herausforderung, besonders aufgrund der Komplexität und Vielfalt der Kanji-Zeichen. Kanji, die logographischen Schriftzeichen der japanischen Sprache, stammen ursprünglich aus China und haben ein breites Spektrum an Bedeutungen und Lesungen. Für diejenigen, die Japanisch lernen möchten, ist das Verständnis von Kanji-Häufigkeit ein wesentlicher Faktor, um den Lernprozess zu strukturieren und das Leseverständnis zu verbessern. Kanji-Häufigkeit beschreibt, wie oft ein bestimmtes Kanji in verschiedenen Textsorten wie literarischen Werken, Nachrichtenartikeln oder Enzyklopädieeinträgen verwendet wird. Dieses Wissen kann Lernenden dabei helfen, gezielt die wichtigsten und am häufigsten verwendeten Schriftzeichen zuerst zu erlernen und somit schneller Fortschritte zu machen.
Eine umfassende Datenanalyse von Kanji-Häufigkeiten basiert auf der Auswertung umfangreicher Textkorpora. Dabei werden verschiedene Quellen genutzt, um ein ausgewogenes Bild der Kanji-Verwendung in unterschiedlichen Kontexten zu erhalten. Eine bedeutende Quelle stellt Aozora Bunko dar, eine digitale Bibliothek klassischer japanischer Literatur, die über 17.000 Texte umfasst und mehr als 67 Millionen Kanji-Zeichen enthält. Daneben liefert die japanische Wikipedia mit rund 100.
000 Artikeln und knapp 60 Millionen Kanji einen modernen Einblick in die politische, soziale und kulturelle Walze des Landes. Zusätzlich bieten Nachrichtenartikel eine dynamische Perspektive auf die alltägliche Sprache und den aktuellen Wortgebrauch, wenn auch in einem kleineren Umfang mit etwa 3.700 Texten und über einer Million Kanji-Zeichen. Das Studium dieser Korpora verdeutlicht, dass die Verwendungshäufigkeit von Kanji stark von der Textart abhängt. Literarische Werke etwa tendieren dazu, häufiger ältere oder seltenere Schriftzeichen zu verwenden, während Nachrichtenartikel eine zugängliche, oft standardisierte Sprache nutzen, die für breitere Bevölkerungsschichten verständlich sein soll.
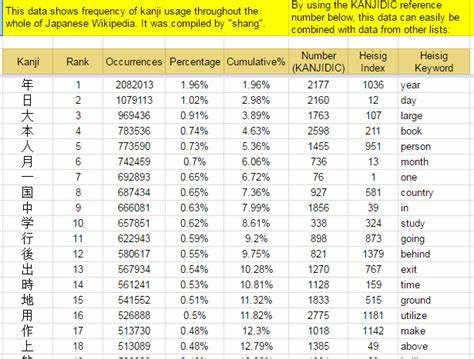
Die Wikipedia wiederum vermittelt eine Mischung aus beiden Welten, indem es sowohl wissenschaftliche Präzision als auch eine allgemein verständliche Sprache verbindet. Interessanterweise variiert die Rangfolge der meistgenutzten Kanji deutlich zwischen diesen Korpora, was zeigt, dass der Kontext für das Lernen und die Anwendung der Kanji von großer Bedeutung ist. Die wichtigsten Kanji in literarischen Texten spiegeln oft die menschliche Erfahrung wider. So steht beispielsweise das Zeichen für „Mensch“ (人) an oberster Stelle bei Aozora Bunko. Im Gegensatz dazu sind Zeichen wie „Jahr“ (年) und „Tag“ (日) bei Wikipedia und Nachrichten, die den Zeitgeist besser abbilden, dominanter.
Die Kenntnis solcher Unterschiede ermöglicht es Lernenden, ihren Fokus je nach Lernziel anzupassen: Wer klassische Literatur lesen möchte, sollte die Kanji frequent in diesem Bereich beherrschen, während Nachrichtenleser eine andere Palette an Zeichen priorisieren sollten. Eine weitere wichtige Erkenntnis ist die Verteilung der Kanji-Häufigkeit in den Texten. Dabei ist es relevant, nicht nur die Gesamtzahl eines Kanji in einem Korpus zu betrachten, sondern auch, wie viele Dokumente es tatsächlich enthalten. Das bedeutet, dass ein Kanji häufig vorkommen kann, jedoch auf wenige Texte konzentriert sein kann, oder es erscheint moderat oft, dafür aber in einer großen Vielzahl von Dokumenten. Beispielsweise erscheint das Kanji für „eins“ (一) in nahezu allen Texten des Nachrichtenkorpus, was seine grundlegende Bedeutung unterstreicht.
Diese Art der Analyse unterstützt Lernende dabei, die Relevanz bestimmter Kanji für eine umfassendere sprachliche Kompetenz besser zu erfassen. Neben dem Nutzen der Häufigkeitsdaten für den Lernprozess bieten sie auch interessante Einblicke in die Entwicklung der japanischen Sprache über die Zeit. Historische Texte, wie sie in den Aozora-Bunkosammlung zu finden sind, enthalten oft eine andere Schreibweise oder Verwendung von Kanji als moderne Texte in Wikipedia oder Nachrichten. Seit einigen Jahrzehnten gibt es offizielle Reformen der japanischen Orthografie, die zum Beispiel die Anzahl der offiziell anerkannten Schriftzeichen vorher bestimmten kanonischen Listen reduziert haben. Das Verständnis dieser Geschichte ist besonders wichtig für Leser klassischer Literatur, die sich auf ältere Varianten oder weniger gebräuchliche Kanji vorbereiten müssen.
Die Analyse der kumulativen Kanji-Abdeckung ist eine Methode, um den Lernaufwand abzuschätzen. Studien zeigen, dass das Erlernen der 100 häufigsten Kanji in Nachrichtenartikeln bereits dazu führt, dass man etwa 45 Prozent der Kanji-Zeichen in diesem Kontext erkennen kann. Mit weiterem Lernen steigt diese Abdeckung deutlich an: Bei 300 Zeichen kann man circa 72 Prozent der Kanji lesen, und bei der Beherrschung von etwa 1000 häufigsten Kanji ist eine Erkennungsrate von rund 96 Prozent möglich. Diese Erkenntnisse erleichtern die Planung des Lernprozesses und motivieren dazu, sich zunächst auf die gebräuchlichsten Kanji zu konzentrieren, um schnell Kommunikationsfähigkeit zu erlangen. Ein weiterer Aspekt, der Kanji-Häufigkeitsdaten besonders wertvoll macht, ist ihr Beitrag zur Entwicklung von modernen Lerntechnologien.
Online-Plattformen und Apps profitieren enorm von solchem Wissen, indem sie personalisierte Lernpläne entwickeln können, die auf den individuellen Zielen und dem bevorzugten Texttyp basieren. So kann jemand, der hauptsächlich Nachrichten lesen möchte, entsprechend angepasste Kanji-Lernsets erhalten, während Literaturbegeisterte tiefer in klassische Zeichenund deren Verwendung eintauchen können. Nicht zuletzt hat die Verfügbarkeit dieser Daten unter einer Creative Commons Attribution 4.0 International Lizenz es ermöglicht, dass Entwickler und Sprachenthusiasten frei darauf zugreifen und diese nutzen können. Das fördert nicht nur die Verbreitung, sondern auch die Weiterentwicklung von Lernmaterialien und Tools.
Die Pflege und Aktualisierung solcher Datensätze ist jedoch eine kontinuierliche Herausforderung, insbesondere aufgrund der sich wandelnden Medienlandschaft, Paywalls bei Nachrichtenwebsites sowie den Einschränkungen bei der Datenerfassung auf Plattformen wie Twitter. Zusammenfassend lässt sich sagen, dass ein fundiertes Verständnis der Kanji-Häufigkeit im Japanischen unerlässlich ist, um effizient und zielorientiert zu lernen. Die verschiedenen Datensätze aus literarischen Werken, modernen Nachrichtentexten und Enzyklopädieartikeln bieten eine wertvolle Basis, um die Lernziele individuell anzupassen. Durch die Kombination von Frequenz- und Dokumentenbasierter Analyse erhalten Lernende ein präzises Werkzeug an die Hand, mit dem sie die Komplexität der japanischen Schriftsprache systematisch und effektiv bewältigen können. Dabei spielt nicht nur die Menge der gelernten Kanji eine Rolle, sondern auch deren Kontext und Gebrauchsweise in der jeweiligen Textsorte.
Die Zukunft des Kanji-Lernens wird stark von solchen umfangreichen Korpus-Analysen geprägt sein, sodass immer mehr Lernende von maßgeschneiderten und wissenschaftlich fundierten Methoden profitieren können. Die Berücksichtigung von Zeiträumen, textuellen Unterschieden und Fortschritten in der Datenverfügbarkeit ermöglicht es, den Lernprozess kontinuierlich zu optimieren und für jeden individuell bestmöglich zu gestalten. Wer diese Erkenntnisse nutzt, hat gute Chancen, den scheinbaren Berg der Kanji effizient zu erklimmen und die japanische Sprache in all ihren Facetten erfolgreich zu meistern.