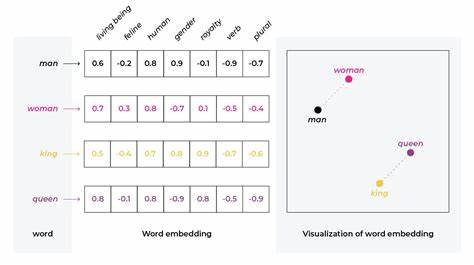
Im Zeitalter der digitalen Informationsflut gewinnt die präzise und effiziente Suche nach relevanten Textdaten zunehmend an Bedeutung. Text-Embeddings, also die Umwandlung von Texten in numerische Vektoren, haben sich als integraler Bestandteil moderner Such- und Empfehlungssysteme etabliert. Sie ermöglichen es Maschinen, die semantische Bedeutung von Wörtern und Dokumenten besser zu erfassen und damit auch komplexere Suchanfragen zu bedienen. Doch trotz dieser Fortschritte gibt es Herausforderungen, die die Leistung von Suchsystemen beeinträchtigen können. Eine der weniger diskutierten, aber dennoch entscheidenden Problemstellungen ist die sogenannte Größenverzerrung (Size Bias) bei Text-Embeddings.
Diese Verzerrung kann die Suchergebnisse maßgeblich beeinflussen und zu einer schlechteren Nutzererfahrung führen. Text-Embeddings werden häufig durch Modelle erzeugt, die Wörter oder Dokumente auf eine mehrdimensionale Vektorfläche abbilden. Idealerweise sollte dabei die Länge oder die Größe des Textes keinen übermäßigen Einfluss auf die Repräsentation und die resultierende Ähnlichkeit zwischen Dokumenten haben. In der Praxis jedoch neigen längere Texte dazu, größere oder anders gewichtete Embeddings zu produzieren, was die Vergleichbarkeit und somit auch die Suchergebnisse verzerrt. Diese Größenverzerrung zeigt sich insbesondere bei der Verwendung klassischer Ähnlichkeitsmaße wie dem Cosinus-Abstand oder der euklidischen Distanz, die für die Bewertung der Nähe von Vektoren genutzt werden.
Längere Dokumente haben oft eine höhere Menge an Informationen, die im Vektor zusammengefasst werden. Dadurch bekommt ihr Embedding eine größere Norm, was dazu führt, dass sie in Vergleichen als ähnlicher oder weniger ähnlich bewertet werden, als es ihrem tatsächlichen semantischen Gehalt entspricht. Dies kann zu unbeabsichtigten Priorisierungen länger Texte in den Suchergebnissen führen, während kürzere, aber ebenso relevante Dokumente benachteiligt werden. Die Auswirkungen dieser Verzerrung auf Suchsysteme sind vielschichtig. Einerseits kann die Rangfolge der Suchergebnisse unausgewogen werden, indem lange Dokumente bevorzugt werden, obwohl sie nicht zwangsläufig relevanter sind.
Andererseits kann die Interpretation von Suchanfragen erschwert werden, wenn die Embeddings von Anfragen selbst unterschiedlich lang sind und somit unterschiedlich behandelt werden. Dies führt dazu, dass Suchalgorithmen weniger präzise arbeiten und die Nutzerzufriedenheit sinkt. Forscher und Entwickler beschäftigen sich intensiv mit der Frage, wie die Größenverzerrung reduziert werden kann. Verschiedene Ansätze nutzen Normierungstechniken, bei denen die Vektorlänge standardisiert oder spezifisch angepasst wird, um vergleichbare Embeddings zu erhalten. Andere Methoden setzen auf die Veränderung der Trainingsstrategien von Modellen, beispielsweise indem sie Short- und Long-Texte gesondert behandeln oder durch den Einsatz von Pooling-Methoden, die die Merkmalsgewichte besser ausbalancieren.
Darüber hinaus bieten neuere Modelle wie Transformer-basierte Architekturen flexible Möglichkeiten, die Textrepräsentation konsistenter zu gestalten und die Einflussnahme der Textlänge zu verringern. Die Berücksichtigung von Kontext und semantischer Aggregation kann hier die Grundlage bilden, um die Verzerrung deutlich zu minimieren. Neben der Verbesserung der Algorithmen müssen auch praktische Aspekte der Suchsysteme beachtet werden. So ist eine Vorverarbeitung der Texte empfehlenswert, welche die Länge berücksichtigt und gegebenenfalls bei der Embedding-Erstellung kompensiert. Adaptive Suchalgorithmen können zusätzlich dynamisch die Größe der Texte in den Vergleich einfließen lassen und so die Relevanzwerte der Ergebnisse verbessern.
Die Größenverzerrung wirkt sich nicht nur auf allgemeine Suchmaschinen aus, sondern auch auf spezialisierte Anwendungsgebiete wie die Suche in wissenschaftlichen Datenbanken, juristischen Dokumenten oder sozialen Medien. In diesen Bereichen ist es besonders wichtig, dass Suchergebnisse fair und objektiv nach Relevanz bewertet werden, um eine zuverlässige Informationsbeschaffung zu gewährleisten. Die Herausforderung der Größenverzerrung bei Text-Embeddings verdeutlicht die Komplexität moderner Suchtechnik und zeigt, dass trotz fortgeschrittener KI-Methoden stets Optimierungspotential besteht. Ein besseres Verständnis und gezielte Gegenmaßnahmen können die Suchqualität signifikant verbessern und damit das Nutzererlebnis nachhaltig positiv beeinflussen. Abschließend ist festzuhalten, dass das Bewusstsein für die Größenverzerrung bei Text-Embeddings ein wichtiger Schritt für Entwickler und Unternehmen ist, die Suchsysteme betreiben oder entwickeln.
Die Integration geeigneter Strategien zur Kompensation von Textlängeneffekten sollte Bestandteil jeder fortschrittlichen Suchmaschine sein. Nur so kann gewährleistet werden, dass Suchanfragen präzise, fair und zufriedenstellend beantwortet werden, unabhängig von der Länge der zugrunde liegenden Texte.