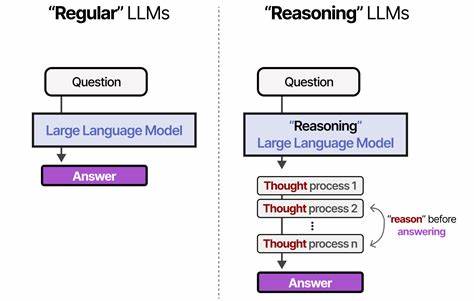
Die rasante Entwicklung großer Sprachmodelle (Large Language Models, LLMs) hat in den letzten Jahren immense Fortschritte in der künstlichen Intelligenz ermöglicht. Anwendungen wie automatische Textgenerierung, komplexe Problemlösungen in Wissenschaft und Technik oder sogar kreative Aufgaben sind mittlerweile Alltag geworden. Doch während die Qualität der Antworten oft beeindruckend ist, zeigt sich eine grundlegende Schwäche: LLMs wissen derzeit nur selten, wann sie besser schweigen sollten. Genau hier setzt die Forschung rund um das neue Benchmarking-Tool namens AbstentionBench an – ein Meilenstein für das Verständnis und die Weiterentwicklung von KI-Systemen hinsichtlich ihrer Fähigkeit, auf unbeantwortbare oder unklare Fragen angemessen zu reagieren. Ein verlässlicher Einsatz von LLMs in kritischen Bereichen wie Medizin, Recht oder technischen Anwendungen erfordert nicht nur präzise Antworten, sondern auch ein vernetztes, selbstkritisches Verhalten, das Risiken minimiert und Unsicherheiten anerkennt.
AbstentionBench stellt eine umfassende Sammlung von über zwanzig speziell kuratierten Datensätzen dar, die vielfältige Herausforderungen an Sprachmodelle stellen. Dies umfasst Fragen mit unbekannten oder veralteten Fakten, unklar formulierte Anfragen, solche mit falschen Grundannahmen sowie solche, die der subjektiven Interpretation unterliegen. Die Vielfalt dieser Testfälle reflektiert reale Interaktionen, bei denen Nutzende häufig unvollständige oder missverständliche Informationen eingeben. Die Fähigkeit eines Modells, korrekt zu erkennen, dass eine Antwort nicht möglich oder sinnvoll ist, wurde bislang kaum systematisch evaluiert und bleibt eine der größten Schwachstellen moderner LLMs. Die Ergebnisse von AbstentionBench sind ernüchternd: Selbst modernste, auf komplexe Problemlösung trainierte Modelle zeigen erhebliche Schwierigkeiten, eine angemessene Abstinenz zu wahren.
Das Benchmark enthüllt, dass mit steigender Modellgröße allein keine Verbesserung einhergeht – die reine Skalierung hilft nicht dabei, das Kernproblem der Unsicherheitsbewertung zu lösen. Überraschend ist zudem, dass spezielle Feineinstellungen auf reasoning-orientierte Trainingsdaten, die etwa mathematische oder naturwissenschaftliche Fragestellungen abdecken, in der Praxis sogar die Abstention-Performance um durchschnittlich 24 Prozent verschlechtern können. Dies legt nahe, dass eine Fokussierung auf das Reinforcement von Problemlösungsfähigkeiten die Fähigkeit zur Zurückhaltung beeinträchtigen kann, was einer fehlenden Balance zwischen generativer Kreativität und epistemischer Vorsicht entspricht. Ein weiteres wichtiges Ergebnis ist, dass zwar systemseitige Eingriffe, wie sorgfältig entwickelte Systemprompts, die Tendenz zur Selbstenthaltung verbessern können, jedoch kein Allheilmittel sind. Solche Strategien tragen dazu bei, die Modelle in die Lage zu versetzen, verbalere Unsicherheitsbekundungen oder Ablehnungen zu formulieren, ohne jedoch das zugrundeliegende Problem des mangelhaften Unterscheidungsvermögens vollständig zu beseitigen.
Die fundamentale Herausforderung liegt darin, dass LLMs tendenziell darauf trainiert sind, kohärente Antworten zu generieren, was sie oft dazu verleitet, hypothetische oder erfundene Antworten zu liefern, anstatt eine neutrale Position einzunehmen oder Unsicherheit zu signalisieren. Vor dem Hintergrund dieser Erkenntnisse hat AbstentionBench das Ziel, die Forschungscommunity zu inspirieren, die Zuverlässigkeit und Vertrauenswürdigkeit von KI-Systemen maßgeblich zu verbessern. Hierzu gehört die Entwicklung neuer Trainingsmethoden und Architekturen, die explizit auch das Recht auf Nicht-Antworten respektieren. Besonders wichtig ist die Arbeit an transparenten und nachvollziehbaren Modellen, die nicht nur auf statistische Muster reagieren, sondern auch ein metakognitives Verständnis von Wissen und Unwissen fördern. Die Integration von Unsicherheitsabschätzung und Modelle der Epistemik sind vielversprechende Ansätze, um die komplexen Anforderungen echter Anwendungsszenarien zu meistern.
Ein weiterer Aspekt betrifft die Interaktion zwischen Mensch und Maschine. Nutzerinnen und Nutzern muss bewusst gemacht werden, dass KI-Systeme trotz hoher Leistungsfähigkeit Limitationen haben – insbesondere in Bezug auf Wahrheitshaltigkeit und Gültigkeit von Informationen. Das Einführen klarer Mechanismen und Standards für Abstinenz und Unsicherheitskommunikation kann die Akzeptanz und das Vertrauen in KI-Anwendungen verbessern. So können Modelle kritische oder potenziell gefährliche Fehlinformationen vermeiden und stattdessen transparent angeben, wann eine Antwort nicht verantwortbar ist. AbstentionBench positioniert sich als zukunftsweisender Meilenstein in der Bewertung von KI-Systemen, dessen ethnische und praktische Bedeutung nicht unterschätzt werden darf.
Die Forschungsarbeit von Polina Kirichenko, Mark Ibrahim, Kamalika Chaudhuri und Samuel J. Bell hebt hervor, dass das richtige Verhalten bei unbeantwortbaren Fragen eine komplexe Herausforderung darstellt, die weit über reine Leistungskennzahlen hinausgeht. Für Entwickler, Forschende und Anwender von KI bedeutet dies eine neue Perspektive auf die Bedeutung von Vertrauenswürdigkeit, Sicherheit und Robustheit. Insgesamt steht die KI-Landschaft vor der dringenden Aufgabe, strategisch an Fähigkeit und Verantwortungsbewusstsein der LLMs zu arbeiten. AbstentionBench demonstriert eindrucksvoll, dass nur durch gezielte Evaluation und kontinuierliche Weiterentwicklung neue Standards für die Praxis etabliert werden können.
Das Ergebnis dieser Bemühungen wird maßgeblich dazu beitragen, KI-Technologie nicht nur effektiver, sondern auch sicherer und ethisch verträglicher zu gestalten – und damit ihr volles Potenzial im Alltag und in professionellen Kontexten zuverlässig auszuschöpfen.