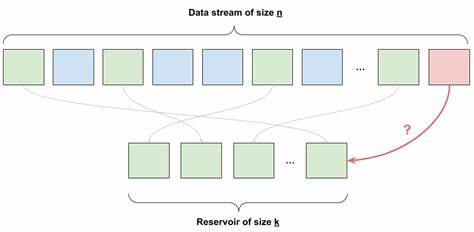
In der heutigen digitalen Welt steigen Datenmengen stetig an. Systeme, die große Datenströme verarbeiten, stehen oft vor der Herausforderung, repräsentative Zufallsstichproben zu ziehen, ohne dabei die gesamte Datenmenge speichern oder verarbeiten zu müssen. Hier kommt das Reservoir Sampling ins Spiel, ein Algorithmus, der genau dieses Problem elegant löst. Die Methode ermöglicht es, aus einem Datenstrom mit unbekannter oder sehr großer Länge eine zufällige Auswahl von k Elementen zu treffen, ohne die gesamte Datenquelle gleichzeitig im Speicher zu halten. Das spart nicht nur Ressourcen, sondern garantiert auch eine faire Wahl mit gleichen Wahrscheinlichkeiten für alle Elemente.
Das Grundkonzept von Reservoir Sampling ist einfach und genial zugleich. Man hält einen Vorrat – das sogenannte Reservoir – mit einer Kapazität von k Elementen bereit. Wenn weniger als k Elemente bisher betrachtet wurden, fügt man jedes neue Element einfach direkt in das Reservoir ein. Sobald der Strom mehr als k Datenpunkte bereithält, entscheidet der Algorithmus für jedes neue Element mit einer bestimmten Wahrscheinlichkeit, ob es in das Reservoir aufgenommen wird. Im Fall einer Aufnahme ersetzt es ein zufällig ausgewähltes Element im bestehenden Reservoir.
So ist sichergestellt, dass über den gesamten Datenstrom hinweg jedes Element mit derselben Wahrscheinlichkeit ausgewählt wird. Die mathematische Eleganz des Verfahrens lässt sich durch Induktion beweisen und ist für Informatiker und Statistikbegeisterte gleichermaßen faszinierend. Zu jedem Zeitpunkt i im Datenstrom sind die vorherigen und das aktuelle Element gleichwahrscheinlich im Reservoir vertreten. Auf diese Weise bildet das Reservoir eine wahrhaft repräsentative Stichprobe. Ein naheliegender Vergleich ist das zufällige Mischen einer Liste aller Elemente, wobei anschließend die ersten k Einträge entnommen werden – was jedoch in der Praxis meistens nicht möglich ist, da die gesamte Datenmenge nicht stets verfügbar oder zu groß für den Speicher ist.
Reservoir Sampling ist besonders in Bereichen von immensem Nutzen, in denen Echtzeit-Datenströme verarbeitet werden oder Speicher begrenzt ist. Beispielsweise in der Ereignisprotokollierung großer Systeme, bei Netzwerküberwachungen, in der Analyse sozialer Medien oder in der Machine-Learning-Vorbereitung großer Datensätze. In solchen Szenarien ist es oft unmöglich, alle Daten zu speichern, bevor eine Auswahl erfolgt. Hier ermöglicht Reservoir Sampling, auch bei unbestimmter oder kontinuierlich einströmender Datenmenge eine zufällige Auswahl zu gewährleisten, ohne den Gesamtüberblick zu verlieren. Die Herausforderung bei der Implementierung von Reservoir Sampling besteht nicht nur im Umgang mit großen Datenmengen, sondern auch in der Erzeugung von wirklich gleichverteilten Zufallszahlen.
Eine häufig auftretende Falle ist der sogenannte Modulus-Bias, wenn man einfach einen Zufallswert modulo der Zielgröße nimmt. Diese Methode führt insbesondere dann zu verzerrten Wahrscheinlichkeiten, wenn die Obergrenze des Zufallszahlengenerators nicht durch die Zielgröße teilbar ist. Das kann auf lange Sicht bedeuten, dass einige Elemente des Datenstroms bevorzugt ausgewählt werden – was die Gleichverteilung untergräbt. Um diesem Problem entgegenzuwirken, verwenden gut implementierte Algorithmen eine Technik, bei der Zufallszahlen lediglich innerhalb eines sorgfältig bestimmten Bereichs akzeptiert werden. Indem Zahlen, die außerhalb eines Vielfachen der Zielgröße liegen, verworfen werden, entsteht eine perfekte Gleichverteilung.
Dies ist zwar etwas aufwändiger, stellt aber sicher, dass alle Elemente im Reservoir dieselbe Wahlchance erhalten. Der Algorithmus gewährt zwar keine absolute garantierte Laufzeit, da in sehr seltenen Fällen länger gebraucht werden kann, garantiert aber über große Stichproben eine exakte Zufallsauswahl mit höchster Gleichverteilung. In der Praxis lässt sich Reservoir Sampling in vielen Programmiersprachen mit nur wenigen Zeilen Code realisieren. Besonders in der Programmiersprache C, mit der Systemanwendungen häufig geschrieben werden, ist der Algorithmus durch seine Einfachheit beeindruckend kompakt und effizient. Eine typische Implementierung liest fortlaufend Werte aus einem Datenstrom ein, füllt zunächst das Reservoir, um dann jedes weitere Element entweder gegen eine Zufallszahl zu prüfen oder gegebenenfalls einen vorhandenen Wert zu ersetzen.
Die Zeit- und Speicherkomplexität bleibt dabei konstant in Bezug auf die Reservoirgröße k und unabhängig von der Gesamtzahl der betrachteten Elemente. Neben dem klassischen Reservoir Sampling existieren auch Varianten und Erweiterungen, die zusätzliche Anforderungen adressieren. Beispielsweise Varianten zur gewichteten Stichprobenziehung, bei denen Elemente mit unterschiedlichen Wahrscheinlichkeiten in das Reservoir gelangen, oder Ansätze, die mehrere Reservoirs gleichzeitig verwalten, um parallele Datenquellen zu bedienen. Außerdem gibt es technologische Weiterentwicklungen, die Reservoir Sampling mit Streaming-Algorithmen und Approximationstechniken kombinieren, um auch bei extremen Datenströmen zuverlässig zu funktionieren. Ein Beispiel für den praktischen Einsatz von Reservoir Sampling sind Social-Media-Plattformen.
Diese müssen ständig große Mengen an Interaktionen wie Likes, Kommentare und Shares erfassen. Für Analysen und Qualitätssicherungen kann eine zufällige, gleichverteilte Stichprobe aus allen Interaktionen hilfreich sein, ohne dass hierzu alle menschlichen Aktionen zwischengespeichert werden müssen. Durch Reservoir Sampling erhalten Unternehmen schnell und ressourcenschonend relevante Daten, die Rückschlüsse auf Nutzerverhalten und Trends ermöglichen. Die Anwendungsgebiete von Reservoir Sampling beschränken sich jedoch nicht nur auf die IT- und Datenwelt. Auch im wissenschaftlichen Kontext wird der Algorithmus eingesetzt, etwa in der Biostatistik oder Umweltforschung, wenn Proben aus kontinuierlich resultierenden Messdaten ausgewählt werden sollen.
Zudem findet man Reservoir Sampling in der Quantitativen Finanzwelt, wo kontinuierlich neue Transaktionen, Trades oder Marktdaten analysiert werden und Stichproben zum Testen von Modellen benötigt werden. Auf der technischen Seite sollte ein Entwickler Reservoir Sampling mit der nötigen Sorgfalt implementieren. Dazu gehört insbesondere die sorgfältige Wahl eines geeigneten Zufallszahlengenerators und Maßnahmen gegen gängigen Bias bei der Modulo-Berechnung. Zudem sollte das Programm robust gegen Speicherengpässe und definitiven Datenstromabbrüchen sein, um jederzeit gültige Stichproben auszugeben. In fertigeren Bibliotheken steckt daher häufig tratitionell geprüfter und performance-optimierter Code, der auf lange Sicht bei Produktionssystemen eingesetzt werden kann.
Auch über die Grenzen des einfachen Reservoir Sampling hinaus entwickeln sich neue Forschungstrends. So gewinnen Streaming-Algorithmen an Bedeutung, die neben der Zufallsauswahl auch Trends und wichtige Datenpunkte in Echtzeit erkennen. Reservoir Sampling steht dabei oft als Kernmechanismus, der kombiniert mit anderen statistischen Techniken effektive und ressourcenschonende Datenanalysen erlaubt. Künftige Entwicklungen könnten zudem besser an komplexe Datenstrukturen angepasst werden, womit die Anwendbarkeit der Methode auch bei hochdimensionalen und komplex vernetzten Daten erweitert wird. Zusammenfassend lässt sich sagen, dass Reservoir Sampling ein unverzichtbares Werkzeug im Umgang mit großen und dynamischen Datenmengen geworden ist.
Es verbindet mathematische Eleganz mit praktischer Anwendbarkeit und sorgt dafür, dass gleichmäßige und faire Zufallsstichproben jederzeit und überall möglich sind, selbst wenn die Datenquelle riesig oder niemals vollständig zugänglich ist. Für Entwickler, Datenwissenschaftler und Ingenieure eröffnet die Methode eine effiziente Möglichkeit, aus ständig anfallenden Datenströmen wertvolle Einblicke zu gewinnen, ohne dabei unerschwingliche Ressourcen zu verbrauchen. Wer sich mit großen Datensätzen beschäftigt, sollte Reservoir Sampling kennen, verstehen und anwenden – denn zufällige, aber faire Auswahlverfahren sind der Schlüssel zu aussagekräftigen und vertrauenswürdigen Ergebnissen in der modernen Datenwelt.