Die rasante Entwicklung grosser Sprachmodelle (Large Language Models, LLMs) hat die Art und Weise, wie Unternehmen mit Kunden interagieren, grundlegend verändert. Ob im Kundenservice, in der Beratung oder im technischen Support – LLMs bieten die Möglichkeit, Fragen automatisiert und kontextbezogen zu beantworten. Doch trotz ihres Potenzials gibt es eine zentrale Herausforderung: Wie kann sichergestellt werden, dass diese KI-gestützten Antworten tatsächlich richtig, vollständig und hilfreich sind? Die Gewährleistung der Antwortgenauigkeit von LLMs ist nicht nur entscheidend für die Kundenzufriedenheit, sondern auch für das Vertrauen in die Technologie und das Markenimage eines Unternehmens. Ein falscher Tipp, eine fehlende Information oder gar eine Halluzination – also eine komplett erfundene Antwort – können neben Irritationen auch erheblichen Schaden anrichten. Die Überprüfung und Messung der Qualität von LLM-Ausgaben ist somit ein essenzielles Thema in der praktischen Anwendung und Weiterentwicklung solcher Systeme.
Eine der größten Herausforderungen bei der Kontrolle von LLM-Antworten liegt in deren inhärenter Komplexität. Sprachmodelle arbeiten nicht mit statischen Daten, sondern generieren Antworten basierend auf gelernten Mustern, was sie anfällig für Fehler wie Halluzinationen macht. Diese sogenannten „Halluzinationen“ entstehen, wenn das Modell Informationen erfindet, die faktisch nicht korrekt sind. Kunden können damit in die Irre geführt werden oder erhalten Antworten, die nicht mit der tatsächlichen Sachlage übereinstimmen. Zusätzlich sind auch unvollständige Antworten oder solche, welche wichtige Aspekte auslassen, problematisch, da sie den Kunden nicht wirklich weiterbringen.
Ein weiterer Faktor ist der Einfluss der Fragestellung auf die Antwortqualität. Unterschiedliche Formulierungen oder die Art der Fragestellung können das Modell dazu bringen, sehr unterschiedliche Antworten zu geben – von präzise bis vage oder sogar falsch. Ein herkömmliches Mittel, um die Qualität zu beurteilen, sind Feedback-Systeme, bei denen Nutzer eine einfache Daumen-hoch- oder Daumen-runter-Bewertung abgeben. Diese Methode ist intuitiv und schnell implementiert, doch weist sie große Schwächen auf. Zum einen bieten die Nutzerbewertungen eine sehr oberflächliche Messgröße, die keine detaillierten Informationen über Fehlerart oder Ursache liefert.
Zum anderen sind solche Signale oft verzerrt, da nur besonders zufriedene oder extrem unzufriedene Nutzer bewerten, was einen unvollständigen und wenig repräsentativen Eindruck erzeugt. Um eine robustere Überwachung zu gewährleisten, setzen viele Unternehmen auf die Nutzung sogenannter „bekannter Abfragen“ oder „Testfragen“, deren korrekte Antworten im Vorfeld definiert sind. Indem das LLM regelmäßig mit diesen standardisierten Fragen getestet wird, kann geprüft werden, ob die erwarteten Antworten geliefert werden. Dieses Vorgehen ermöglicht eine gezielte Qualitätskontrolle und den Vergleich verschiedener Versionen des Modells über die Zeit. Allerdings hat auch dieses System Grenzen, denn es setzt voraus, dass alle relevanten Fragen im Vorfeld bekannt und abgedeckt sind, was in echten Kundeninteraktionen oft nicht der Fall ist.
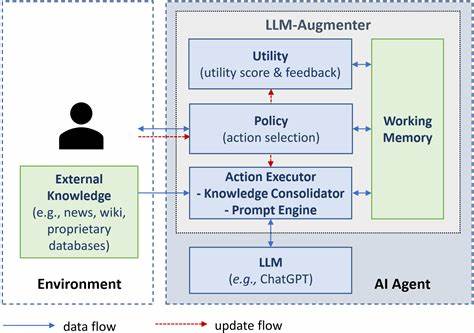
Fortschrittlichere Methoden nutzen automatisierte Ansätze, bei denen maschinelles Lernen selbst eingesetzt wird, um die Qualität der LLM-Antworten zu bewerten. Dabei können andere KI-Modelle die generierten Antworten mit bekannten Faktenbanken abgleichen, Relevanz bzw. Kohärenz prüfen und Fehlermuster erkennen. Auch Natural Language Understanding (NLU)-Technologien können zur Analyse und Validierung eingesetzt werden. So ist es möglich, sowohl in Echtzeit als auch im Nachgang Antworten zu scannen und automatisch Qualitätsmetriken zu erzeugen.
Ein integraler Bestandteil der Qualitätskontrolle ist die Erfassung und Analyse von Nutzungsdaten. Durch Monitoring der Interaktionen können Unternehmen Muster erkennen, in denen das Modell häufiger falsche oder unzufriedene Antworten gibt. Die Analyse solcher Daten erlaubt es, gezielt Verbesserungen umzusetzen oder Warnmechanismen zu entwickeln. Beispielsweise kann bei abfallender Genauigkeit oder vermehrten negativen Rückmeldungen eine Alarmierung erfolgen, um das Modell zu überprüfen oder Anpassungen vorzunehmen. Neben quantitativen Daten helfen qualitative Kunden-Rückmeldungen, die über Ratings hinausgehen, tiefergehende Einsichten in die Probleme und Bedürfnisse der Anwender zu gewinnen.
Ein weiterer wichtiger Aspekt ist die Gestaltung der Eingaben, also wie Nutzerfragen formuliert oder per Prompt Engineering optimiert werden können. Da LLM-Antworten stark von den Eingaben abhängen, kann eine intelligente Anleitung der Nutzer die Qualität der resultierenden Antworten verbessern. Unternehmen investieren deshalb in die Entwicklung von Eingabeformularen, die Fragen klar strukturieren und die Präzision fördern. Ebenso kann das Modell mit zusätzlichen Kontextinformationen oder externen Datenquellen „feeded“ werden, um eine fundiertere Entscheidungsbasis zu schaffen und Bedingungen für korrekte Auskünfte zu erhöhen. Die Integration von Fachexperten in den Entwicklungsprozess und die Qualitätsprüfung stellt eine weitere Möglichkeit dar, die Antwortsicherheit zu erhöhen.
Experten können Antworten stichprobenartig oder bei besonders komplexen Fragen überprüfen und so die Schwachstellen des Modells identifizieren. Im Rahmen eines hybriden Systems wird dadurch eine Kombination von maschineller Effizienz und menschlicher Expertise genutzt, um die Fehlerquote zu minimieren. Die Nutzung von Benchmarks und Qualitätsmetriken ist zentral, um Fortschritte messbar zu machen. Neben klassischen Bewertungsmethoden wie Precision, Recall oder F1-Score nutzen einige Unternehmen spezifische KI-Performance-Indikatoren, die auf Kundenzufriedenheit oder Geschäftsergebnisorientierung zugeschnitten sind. Durch regelmäßige Evaluation anhand solcher Kennzahlen wird die kontinuierliche Verbesserung der Modelle gefördert.
Folgt man den Diskussionen in Entwickler-Communities und Plattformen wie Hacker News oder einschlägigen Fachforen, gibt es keine Patentlösung für die Frage, wie man die Richtigkeit von LLM-Antworten umfassend sicherstellen kann. Stattdessen zeigt sich, dass der Einsatz mehrerer paralleler Verfahren, von Nutzerfeedback über automatisierte Prüfungen bis hin zu Expertenreviews, der effektivste Weg ist. Auch der pragmatische Umgang mit den Grenzen der Technologie und die transparente Kommunikation gegenüber Kunden über mögliche Fehlerquellen sind wichtig, um Erwartungen realistisch zu setzen und Vertrauen zu erhalten. Zukünftige Entwicklungen in den Bereichen Erklärbarkeit (Explainability) von KI und verbesserte selbstüberwachende Modelle werden die Überprüfung der Antwortqualität weiter erleichtern. Solche Modelle können dann eigenständig Warnsignale generieren, wenn Unsicherheiten in den Antworten bestehen, und so proaktiv Qualitätssicherung betreiben.




![Google IO: Android Desktop Windowing [video]](/images/18067355-B79D-4EA3-9E65-95635EBB3A89)